




























Last Updated on enero 1, 2026
Los datos de nombres y direcciones son fundamentales para determinar la exactitud del mercado y los clientes de una empresa y, posteriormente, el posicionamiento de sus productos. Los bancos, los proveedores de servicios sanitarios y otras instituciones, por ejemplo, realizan actividades de depuración de datos de forma rutinaria (por ejemplo, elaboración de perfiles, fusión y limpieza de datos ) para actualizar los campos de nombre y dirección y eliminar las anomalías derivadas de la introducción manual, la falta de estandarización y los errores del sistema.
Sin embargo, los errores de omisión, ortografía, redacción o puntuación son sólo una cara del problema de la mala calidad de los datos. Los campos de nombre duplicados, los formatos de campo incoherentes y la información de dirección abreviada pueden resultar un reto muy complejo.
Por lo tanto, la depuración de datos consistente en sofisticadas transformaciones de los formatos de nombres y direcciones puede ser una alternativa mucho mejor para mejorar la integridad general de los datos. Veamos cómo DataMatch Enterprise de Data Ladder lo permite.
¿Qué es la depuración de datos?
Según Techopedia, la depuración de datos se refiere al «procedimiento de modificación o eliminación de datos incompletos, incorrectos, con formato inexacto o repetidos en una base de datos», todos ellos errores que pueden comprometer negativamente la salud de los datos de la empresa.
La depuración de datos se utiliza indistintamente con la limpieza de datos. Aunque el primero tiene más que ver con el establecimiento de controles de validación y la eliminación de duplicados, ambos tienen el objetivo final de eliminar las anomalías de los datos a efectos de su exactitud.
Normalmente, la depuración de datos permite a las empresas detectar y depurar los siguientes tipos de datos erróneos:
- Errores generales y básicos: estos errores pueden introducirse en las bases de datos de las empresas, sobre todo debido a errores de introducción manual. Los errores ortográficos o tipográficos («Johnn» frente a «John»), los errores de escritura («JOHN», «john» o «jOHN») y los errores de puntuación («OConnor» frente a «O’Connor») entran en esta categoría.
- Datos duplicados: pueden existir entradas duplicadas debido a la falta de validación adecuada de los campos de nombre y dirección. Un ejemplo común es cuando una empresa tiene múltiples fuentes dispares, cada una de las cuales registra una versión única del mismo nombre o registro de dirección.
- Datos incoherentes: se trata de errores de formato en forma de falta de información esencial o de datos transpuestos. Por ejemplo, la «calle de la avenida» puede registrarse como «Ave St» u omitir por completo los datos de la dirección secundaria. Ejemplos de datos transpuestos o de formato de datos erróneo pueden ser: ‘Smith John’ o ‘Mr. Smith’ en lugar de ‘John Smith’, ’68 Bridge Street, CT 06078, Suite 307′ en lugar de ’68 Bridge Street, Suite 307, Suffield, Connecticut, 06078′.
Transformaciones de nombres y direcciones de DataMatch Enterprise
Encontrar y eliminar los datos duplicados y redundantes es una parte integral del proceso de depuración de datos. Pero, ¿cómo asegurarse de que cualquier coincidencia de los campos de nombre y dirección (especialmente entre fuentes de datos dispares) se realiza de forma similar para minimizar los falsos positivos y negativos?
Después de todo, puede haber muchos casos de nombres y direcciones aparentemente diferentes en más de una fuente de datos que pueden ser o no un duplicado. Tomemos el siguiente ejemplo de tres conjuntos de datos: Fuente A, Fuente B y Fuente C.
Fuente A
| Nombre | Segundo nombre | Apellido | Dirección | Estado |
|---|---|---|---|---|
| Michael | Keith | Andrews | Suite 35, calle Avenue | NY |
Fuente B
| Nombre | Número de la calle | Estado |
|---|---|---|
| Mike | 123 Ave St. | NY |
Fuente C
| Nombre | Número de la calle | Código postal |
|---|---|---|
| Sr. Andrews | Casa 35, 123 NY | 10001 |
Cada fuente de datos tiene un formato diferente para registrar los nombres y las direcciones. Al ver estas fuentes, puede parecer que Michael Keith Andrews, Mike y el Sr. Andrews son tres personas diferentes a primera vista. Pero si se examina detenidamente, es probable que se trate de la misma persona y que se hayan registrado tres variaciones diferentes en múltiples fuentes.Así que esta es la pregunta clave: ¿cómo identificar los nombres que deben coincidir y los que no? Para encontrar si hay datos duplicados y redundantes en muchas fuentes de datos, los diferentes formatos de los campos deben ser estandarizados para permitir un cotejo más fácil, como se muestra a continuación.
| Fuente de datos | Prefijo | Nombre | Segundo nombre | Apellido | Dirección 1 | Dirección 2 | Estado | Código postal |
|---|---|---|---|---|---|---|---|---|
| A | Michael | Keith | Andrews | Calle de la Avenida | Suite 35 | NY | ||
| B | Mike | 123 Ave St. | NY | |||||
| C | El Sr. | Andrews | 123 | Suite 35 | NY | 10001 |
Al ordenar los datos en el formato anterior, podemos decir que hay una alta probabilidad de que las tres entidades sean la misma persona.
¿Cómo funciona?
DataMatch Enterprise viene equipado con transformaciones de datos integradas para corregir los formatos incoherentes de los campos de nombre y dirección. Al hacer clic en cualquiera de las transformaciones elegidas del menú desplegable que se muestra a continuación, Datamatch Enterprise puede organizar automáticamente los campos elegidos en incrementos más pequeños para garantizar la conformidad de los formatos.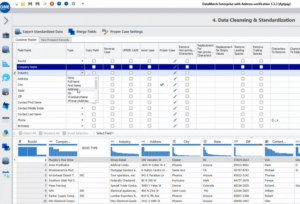 `
`
Figura 2
De este modo, los registros pueden compararse fácilmente entre sí y definir las reglas de correspondencia adecuadas (por ejemplo, correspondencia difusa, fonética o exacta) para la resolución de entidades, la deduplicación y el enriquecimiento de los datos maestros.
Modificación de los campos de nombre
Para transformar los campos de nombre, seleccione la pestaña de la fuente de datos («Nuevos registros de prospectos») que ha importado, pase el ratón por encima del campo «Tipo» situado junto al campo de nombre («Nombre del contacto») y elija «Nombre completo» en la lista desplegable.
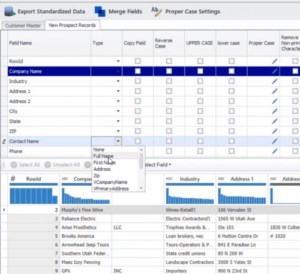
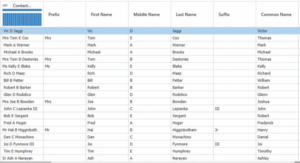
Una vez que la transformación surte efecto, las entradas del campo «Nombre de contacto» se ordenan en prefijo, nombre, segundo nombre, apellido, sufijo y nombre común, como se muestra en la figura 4. El campo del nombre común es generado por la biblioteca de apodos propiedad de DataMatch Enterprise y es una característica adicional para mejorar los vínculos entre el apodo y el nombre común (por ejemplo, Vic como Víctor, Tom como Tomás).
Modificación de los campos de dirección
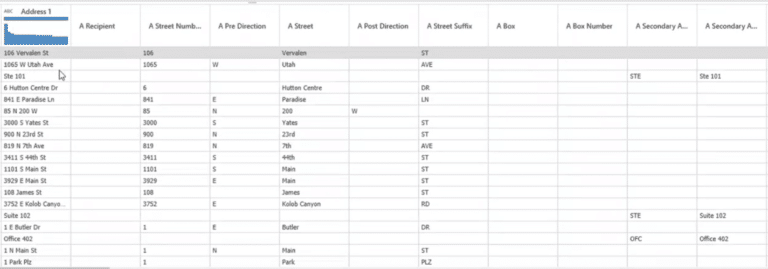
También puede utilizar la transformación «Dirección» para dividir los campos de dirección en Dirección 1 y Dirección 2, ciudad, estado y otros incrementos. Al igual que en la transformación de «Nombre completo», puede hacer clic en «Dirección» para aplicar los cambios.
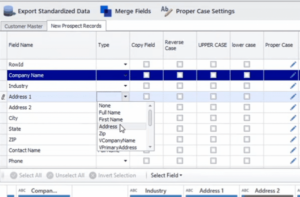
Al hacer clic en la transformación, los datos de la Dirección 1 se dividen en otros subcampos, como se muestra en la Figura 6.
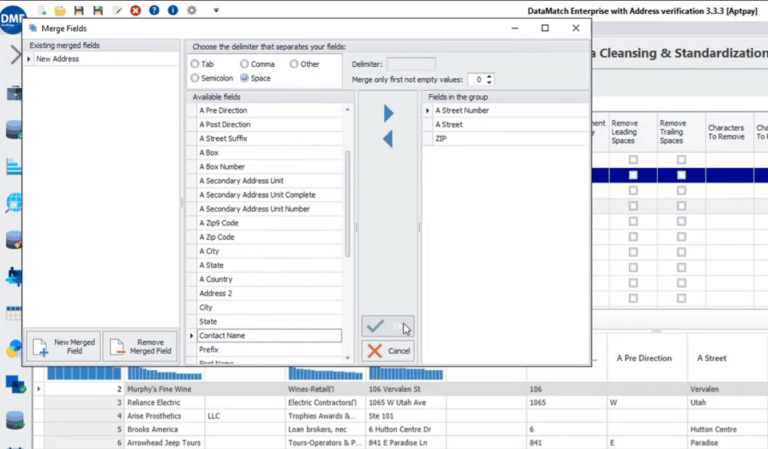
A continuación, puede elegir los campos pertinentes para su nuevo campo de dirección personalizado mediante la opción «Combinar campos». Por ejemplo, puede elegir un número de calle, una calle y un código postal y crear un nuevo campo de dirección.
Comparación y deduplicación
Tras estandarizar los campos según un formato establecido, podemos asignar cada campo con mayor precisión para lograr una mayor puntuación de coincidencia y minimizar los falsos positivos y negativos. Tomando el ejemplo de los campos de nombre de la Figura 4, podemos decidir hacer coincidir los nombres con los nombres y los apellidos con los apellidos en las dos fuentes de datos utilizando la coincidencia difusa de la siguiente manera:

A continuación, las coincidencias se combinan en identificaciones de grupo separadas y las puntuaciones de coincidencia resultantes pueden utilizarse para identificar registros duplicados y dorados.

Conclusión:
Es inevitable que los campos de nombre y dirección existan en distintos formatos en las bases de datos, archivos de Excel, aplicaciones empresariales, etc. Organizaciones como los bancos, los proveedores de servicios sanitarios y otras instituciones no pueden permitirse pasar por alto la más mínima discrepancia en los formatos para que repercuta negativamente en su precisión de cotejo y deduplicación.
Para superar este reto, las transformaciones de los campos de nombre y dirección de DataMatch Enterprise permiten a las empresas garantizar mapeos similares y detectar fácilmente las entradas redundantes o duplicadas para maximizar la integridad de sus datos.
Para obtener más información sobre las soluciones de depuración de datos de DataMatch Enterprise, haga clic aquí.

Cómo funcionan las mejores soluciones de concordancia difusa de su clase: Combinando algoritmos establecidos y propios
Inicie su prueba gratuita hoy mismo



