



































Les données relatives aux noms et aux adresses sont essentielles pour déterminer l’exactitude du marché et des clients d’une entreprise et, par conséquent, le positionnement de ses produits. Les banques, les prestataires de soins de santé et d’autres institutions, par exemple, effectuent régulièrement des activités de nettoyage des données ( profilage, fusion et nettoyage des données ) pour mettre à jour les champs de nom et d’adresse et supprimer les anomalies résultant de la saisie manuelle, du manque de normalisation et des erreurs de système.
Toutefois, les erreurs d’absence, d’orthographe, de casse ou de ponctuation ne sont qu’un aspect du problème de la mauvaise qualité des données. Les champs de nom en double, les formats de champ incohérents et les informations d’adresse abrégées peuvent s’avérer être un défi très complexe.
Par conséquent, l’épuration des données, qui consiste en des transformations sophistiquées du format des noms et des adresses, peut être une bien meilleure solution pour améliorer l’intégrité globale des données. Voyons comment DataMatch Enterprise de Data Ladder permet cela.
Qu’est-ce que l’épuration des données ?
Selon Techopedia, l’épuration des données désigne la « procédure de modification ou de suppression de données incomplètes, incorrectes, mal formatées ou répétées dans une base de données » – autant d’erreurs qui peuvent compromettre la santé des données de l’entreprise.
L’épuration des données est utilisée de manière interchangeable avec le nettoyage des données. Bien que le premier ait plus à voir avec la mise en place de contrôles de validation et la suppression des doublons, les deux ont pour objectif final de supprimer les anomalies de données à des fins d’exactitude des données.
En général, l’épuration des données permet aux entreprises de détecter et d’épurer les types de mauvaises données suivants :
- Erreurs générales et de base : ces erreurs peuvent se glisser dans les bases de données des entreprises, principalement en raison d’erreurs de saisie manuelle. Les fautes d’orthographe ou de frappe (« Johnn » vs. « John »), les erreurs de casse (« JOHN », « john » ou « jOHN »), les erreurs de ponctuation (« OConnor » vs. « O’Connor ») entrent toutes dans cette catégorie.
- Données en double : des entrées en double peuvent exister en raison d’un manque de validation correcte des champs de texte du nom et de l’adresse. Un exemple courant est celui d’une entreprise qui dispose de plusieurs sources disparates, chacune enregistrant une version unique du même nom ou de la même adresse.
- Données incohérentes : il s’agit d’erreurs de format qui prennent la forme d’informations essentielles manquantes ou de données transposées. Par exemple, « Avenue street » peut être enregistré comme « Ave St » ou ne pas comporter de données d’adresse secondaire. Les exemples de données transposées ou de format de données erroné peuvent inclure : Smith John » ou « Mr. Smith » au lieu de « John Smith », « 68 Bridge Street, CT 06078, Suite 307 » au lieu de « 68 Bridge Street, Suite 307, Suffield, Connecticut, 06078 ».
Transformations des noms et adresses de DataMatch Enterprise
La recherche et la suppression des données en double et redondantes font partie intégrante du processus de nettoyage des données. Mais comment s’assurer que toute correspondance entre les champs de nom et d’adresse (en particulier entre des sources de données disparates) est effectuée sur une base similaire afin de minimiser les faux positifs et négatifs ?
Après tout, il peut y avoir de nombreux cas de noms et d’adresses apparemment différents dans plus d’une source de données, qui peuvent ou non être des doublons. Prenons l’exemple suivant de trois ensembles de données : Source A, Source B, et Source C.
Source A
| Prénom | Deuxième prénom | Nom de famille | Adresse | État |
|---|---|---|---|---|
| Michael | Keith | Andrews | Bureau n° 35, rue Avenue | NY |
Source B
| Nom | Numéro de rue | État |
|---|---|---|
| Mike | 123 Ave St. | NY |
Source C
| Nom | Numéro de rue | Code postal |
|---|---|---|
| M. Andrews | Maison 35, 123 NY | 10001 |
Chaque source de données a un format différent pour enregistrer les noms et les adresses. En examinant ces sources, il peut sembler à première vue que Michael Keith Andrews, Mike et M. Andrews sont trois personnes différentes. Mais en y regardant de plus près, il est probable qu’il s’agit de la même personne et que trois variations différentes ont été enregistrées sur plusieurs sources.Voici donc la question clé : comment allez-vous identifier les noms qui doivent correspondre et ceux qui ne le doivent pas ? Pour déterminer s’il existe des données en double ou redondantes dans de nombreuses sources de données, il convient de normaliser les différents formats de champ afin de faciliter les rapprochements, comme indiqué ci-dessous.
| Source des données | Préfixe | Prénom | Deuxième prénom | Nom de famille | Adresse 1 | Adresse 2 | État | Code postal |
|---|---|---|---|---|---|---|---|---|
| A | Michael | Keith | Andrews | Rue de l’Avenue | Suite 35 | NY | ||
| B | Mike | 123 Ave St. | NY | |||||
| C | Monsieur. | Andrews | 123 | Suite 35 | NY | 10001 |
En organisant les données dans le format ci-dessus, nous pouvons dire qu’il y a une forte probabilité que les trois entités soient la même personne.
Comment cela fonctionne-t-il ?
DataMatch Enterprise est équipé de transformations de données intégrées pour corriger les formats incohérents des champs de nom et d’adresse. En cliquant sur l’une des transformations choisies dans le menu déroulant ci-dessous, Datamatch Enterprise peut automatiquement organiser les champs choisis en incréments plus petits pour s’assurer que les formats sont conformes.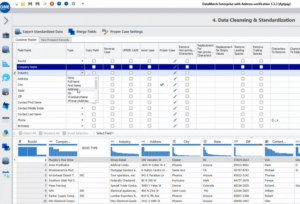 `
`
Figure 2
Ainsi, les enregistrements peuvent être facilement comparés les uns aux autres et les règles de correspondance appropriées (par exemple, correspondance floue, phonétique ou exacte) peuvent être définies pour la résolution des entités, la déduplication et l’enrichissement des données de base.
Modifier les champs de nom
Pour transformer les champs de nom, sélectionnez l’onglet de la source de données (‘New Prospect Records’) que vous avez importé, survolez le champ ‘Type’ à côté du champ de nom (‘Contact Name’) et choisissez ‘Full Name’ dans la liste déroulante.
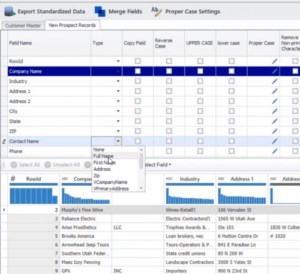
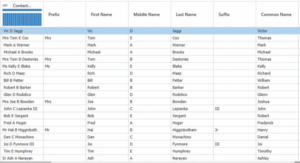
Une fois la transformation effectuée, les entrées du champ « Nom du contact » sont organisées en préfixe, prénom, second prénom, nom de famille, suffixe et nom commun, comme le montre la figure 4. Le champ du nom commun est généré par la bibliothèque de surnoms propriétaire de DataMatch Enterprise. Il s’agit d’une fonctionnalité supplémentaire permettant d’améliorer les liens entre le surnom et le nom commun (par exemple, Vic comme Victor, Tom comme Thomas).
Modifier les champs d’adresse
Vous pouvez également utiliser la transformation « Adresse » pour diviser les champs d’adresse en Adresse 1 et Adresse 2, ville, état et autres incréments. Comme pour la transformation du « Nom complet », vous pouvez cliquer sur « Adresse » pour appliquer les changements.
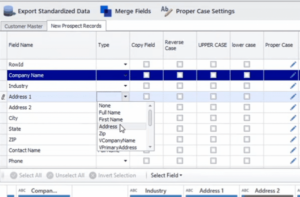
En cliquant sur la transformation, les données de l’adresse 1 sont divisées en plusieurs autres sous-champs, comme le montre la figure 6.
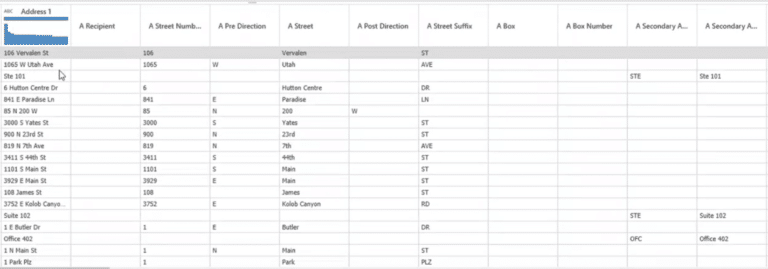
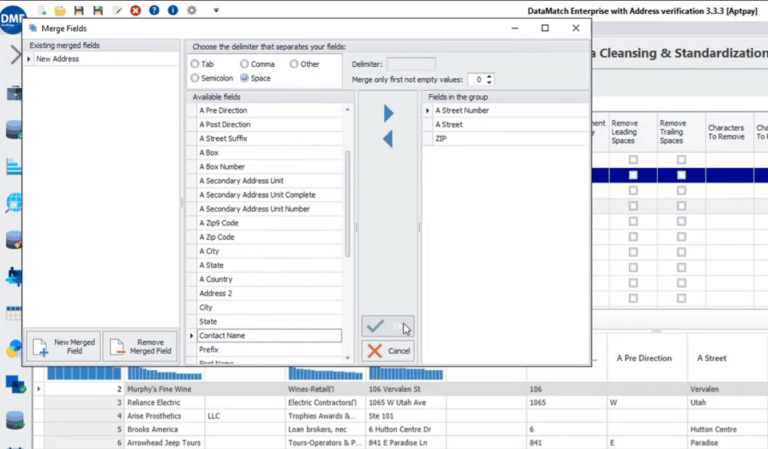
Vous pouvez ensuite choisir les champs pertinents à utiliser pour votre nouveau champ d’adresse personnalisé en utilisant l’option « Fusionner les champs ». Par exemple, vous pouvez choisir un numéro de rue, une rue et un code postal et créer un nouveau champ d’adresse.
Correspondance et déduplication
Après avoir normalisé les champs selon un format défini, nous pouvons cartographier chaque champ avec plus de précision pour obtenir un score de correspondance plus élevé et minimiser les faux positifs et négatifs. Si l’on reprend l’exemple des champs de nom de la figure 4, nous pouvons décider de faire correspondre les prénoms avec les prénoms et les noms avec les noms de famille dans les deux sources de données en utilisant la correspondance floue comme suit :

Les correspondances sont ensuite combinées dans des ID de groupe distincts et les scores de correspondance qui en résultent peuvent être utilisés pour identifier les doublons et les enregistrements dorés.

Conclusion
Il est inévitable que les champs de nom et d’adresse existent sous différents formats dans les bases de données, les fichiers Excel, les applications d’entreprise, etc. Les organisations telles que les banques, les prestataires de soins de santé et d’autres institutions ne peuvent pas se permettre de négliger la plus petite différence de format, qui pourrait avoir un impact négatif sur la précision de la correspondance et de la déduplication.
Pour surmonter ce défi, les transformations des champs de nom et d’adresse de DataMatch Enterprise permettent aux entreprises de garantir des correspondances identiques et de détecter facilement les entrées redondantes ou en double afin de maximiser l’intégrité de leurs données.
Pour plus d’informations sur les solutions d’épuration des données de DataMatch Enterprise, cliquez ici.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Commencez votre essai gratuit aujourd’hui
Aïe ! Nous n’avons pas retrouvé votre formulaire.




