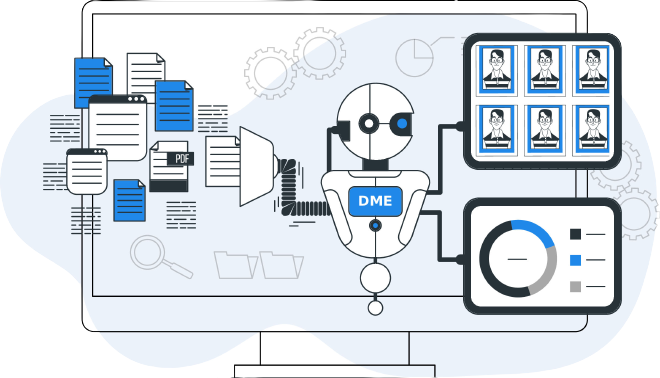







Conexión de la fuente de datos
Conecte la base de datos, mapee los campos y seleccione una combinación de campos para la coincidencia difusa que tengan una alta probabilidad de ser similares en caso de que los registros pertenezcan a la misma entidad.

Cálculo de la puntuación difusa
Las puntuaciones de coincidencia se calculan utilizando la mejor combinación de algoritmos difusos propios y establecidos, como la distancia Levenstein, la distancia de edición, el Soundex, el Metáfono o la similitud de coseno, etc.

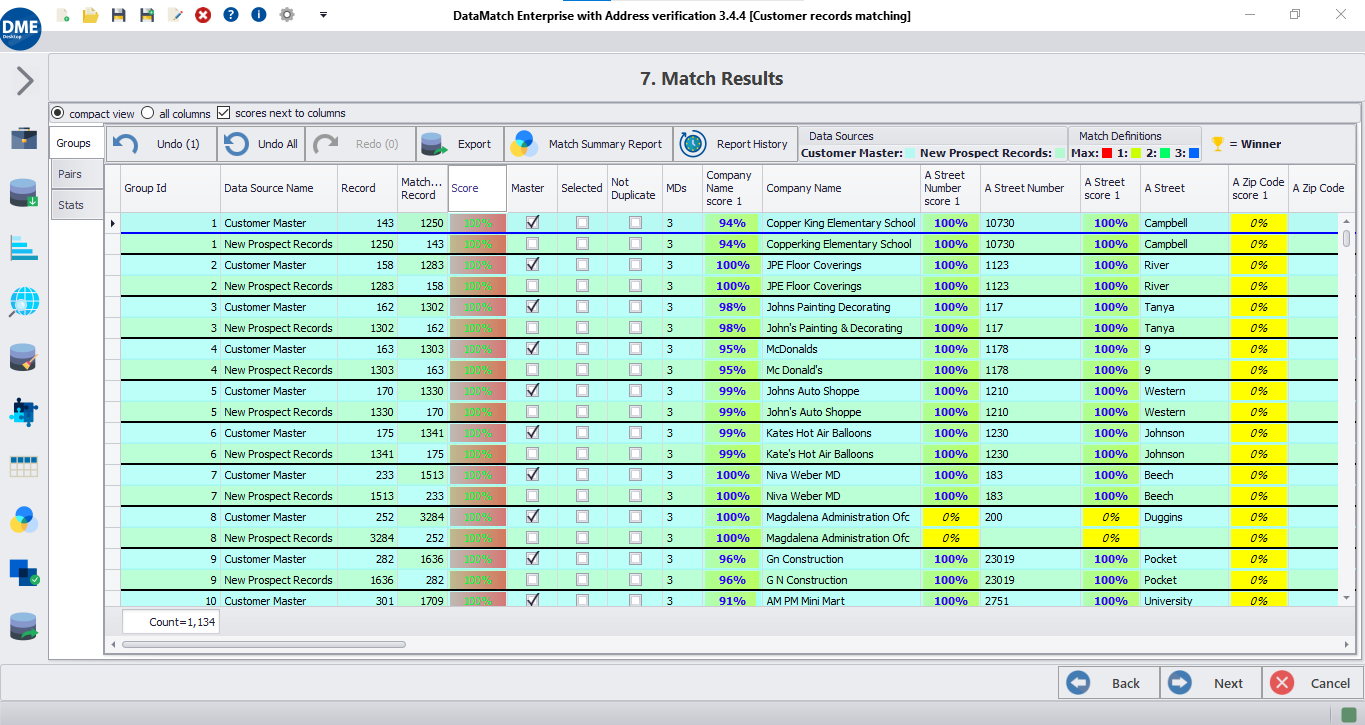
Configuración de la coincidencia difusa
Seleccione los pesos adecuados (dar más prioridad a unos campos que a otros), los niveles de umbral (establecer el límite entre las coincidencias y las no coincidencias) y el tipo de coincidencia difusa (basada en caracteres, fonética, etc.).

Clasificación y evaluación
Las puntuaciones se utilizan para clasificar y agrupar los registros como coincidentes o no coincidentes. Dependiendo de la naturaleza de los datos, puede encontrar algunos resultados falsos positivos y negativos que requieren una evaluación adicional.