






Data source connection
Connect database, map fields, and select a combination of fields for fuzzy matching that have a high chance of being similar in case records belong to the same entity.

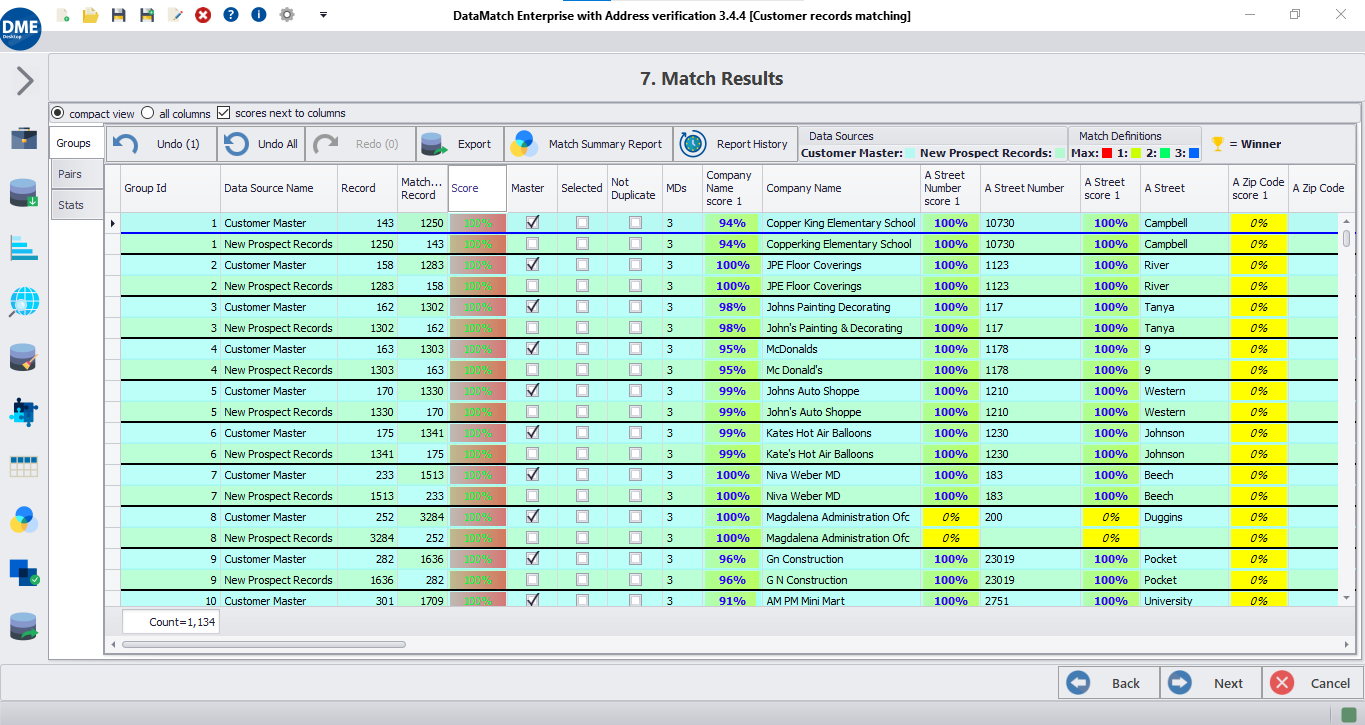
Fuzzy score calculation
Match scores are calculated using the best combination of proprietary and established fuzzy algorithms, such as Levenstein Distance, Edit Distance, Soundex, Metaphone, or Cosine Similarity etc.

Fuzzy match configuration
Select suitable weights (prioritize certain fields more than the other), threshold levels (set the boundary between matches and nonmatches), and the type of fuzzy matching (character-based, phonetic, etc.).

Classification and evaluation
Scores are used to classify and group records as a match or nonmatch. Depending on the nature of data, you may encounter some false positive and negative results which require further evaluation.