































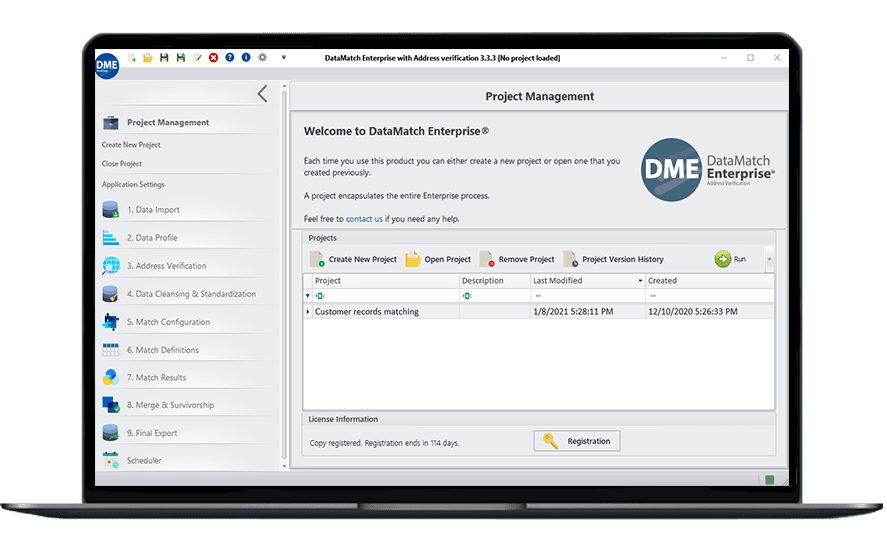






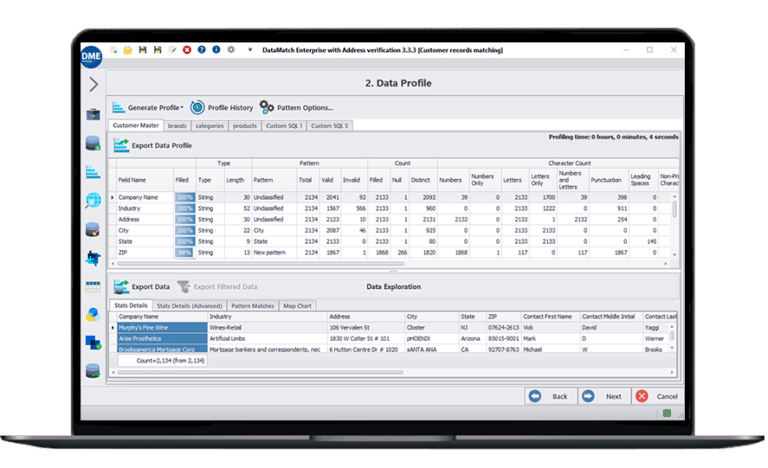
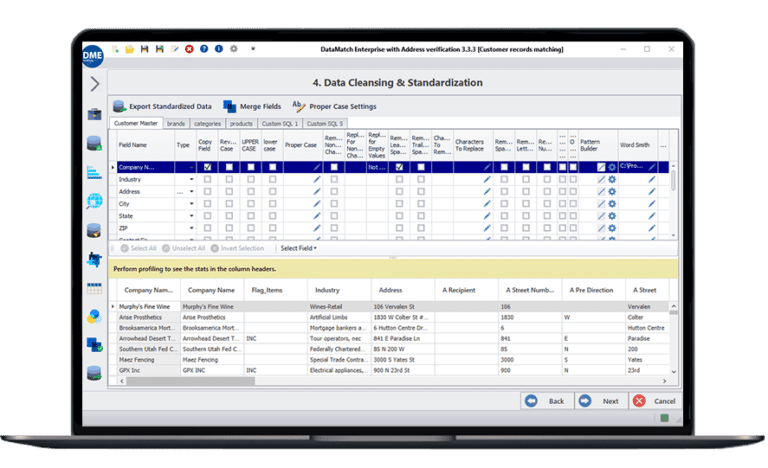
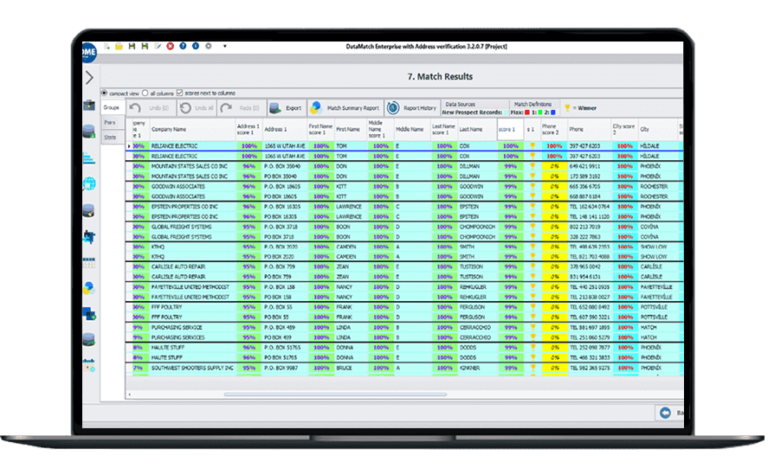
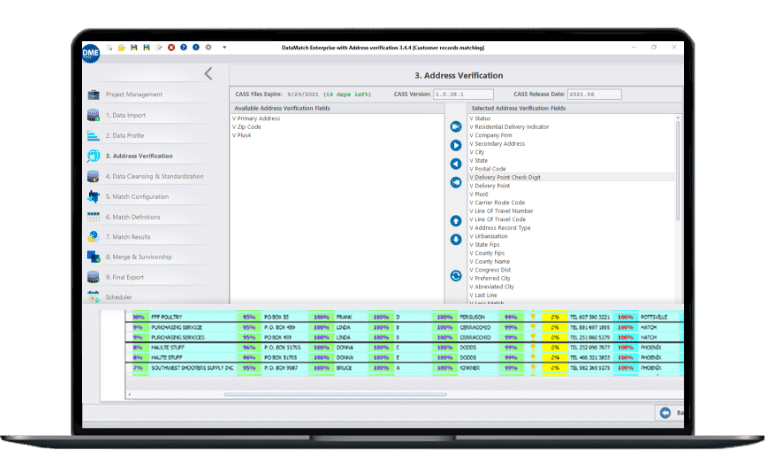
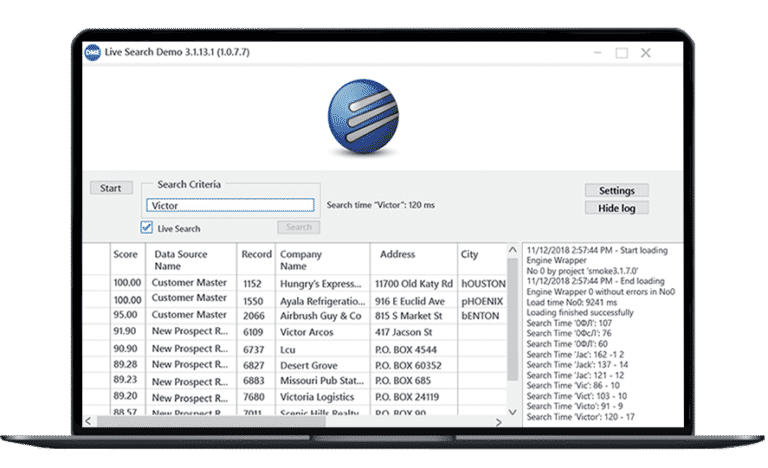
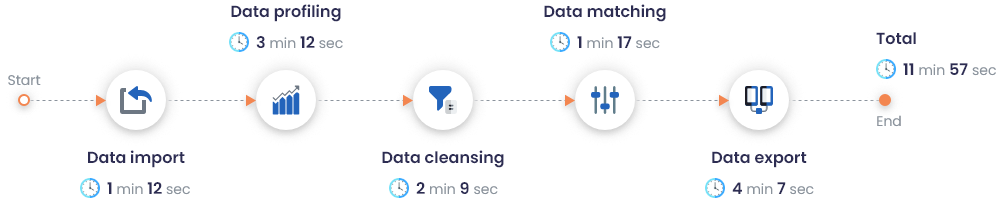

High performance
Exceptionally high performance and scalability features, allowing tons of data to be cleansed, matched and processed on demand.

Quick implementation
Simply download and deploy the application within minutes with the help of our guided installation wizard and start matching.
Intuitive interface
A highly visual and intuitive interface made for business users, IT specialists, data analysts and scientists, as well as novice users.

Robust matching technology
Rated faster and more accurate than IBM and SAS, DME consistently had the least number of false positives in independent studies.

Seamless integration
Readily integrate the world’s fastest and most accurate data quality features into your custom-built or third-party applications.
Real time syncs
Compute exact, fuzzy, and intelligent matches in real-time, across and within multiple data sources at blazing speeds.

Quick data profiling
Master record selection
Workflow orchestration
Advanced filtering

Instant and live data preview

Record Linkage and Deduplication

Phone number standardization

Bulk cleansing and standardization

Email address cleansing
Seamless data integration
Cross-column matching

Pattern matching and recognition

It’s not just the software which works very well for us, but the focus and knowledge that Data Ladder brings to the table


Thanks to Data Ladder we successfully cleaned up and matched our internal sales file with new leads, greatly improving efficiency and sales.

We could not do these reports before. Now, DataMatch has become a main staple in my suite of tools that I work with


Merging Data from Multiple Sources – Challenges and Solutions

Deterministic vs. Probabilistic Matching: When to Choose Each Data Matching Type
Last Updated on July 30, 2026 Deterministic matching links two records only when specified fields agree exactly, like an identical account number. Probabilistic matching links
Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 30, 2026 Quick Verdict The best data deduplication software depends on where duplicate records exist, how many systems must be reconciled,
Deterministic vs. Probabilistic Matching: When to Choose Each Data Matching Type
Last Updated on July 30, 2026 Deterministic matching links two records only when specified fields agree exactly, like an identical account number. Probabilistic matching links
Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 30, 2026 Quick Verdict The best data deduplication software depends on where duplicate records exist, how many systems must be reconciled,
9 Best Fuzzy Matching Software for Data Teams in 2026
Last Updated on July 30, 2026 Quick Verdict The best fuzzy matching tool depends on the scale of the project, data sources, and technical resources
