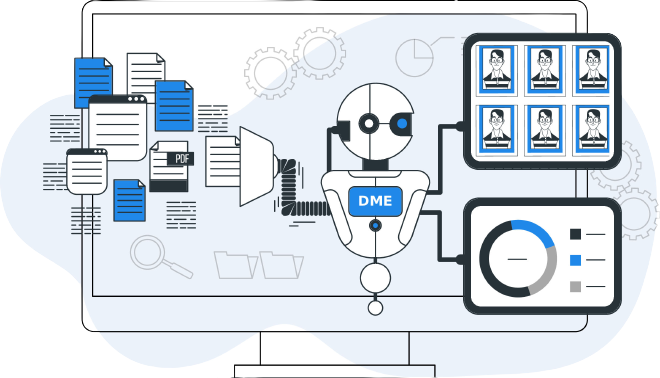







Connexion à la source de données
Connectez la base de données, mappez les champs et sélectionnez une combinaison de champs pour la correspondance floue qui a de fortes chances d'être similaire au cas où les enregistrements appartiennent à la même entité.

Calcul du score flou
Les scores de correspondance sont calculés à l'aide de la meilleure combinaison d'algorithmes flous propriétaires et établis, tels que la distance de Levenstein, la distance d'édition, le Soundex, le Metaphone ou la similitude cosinus, etc.

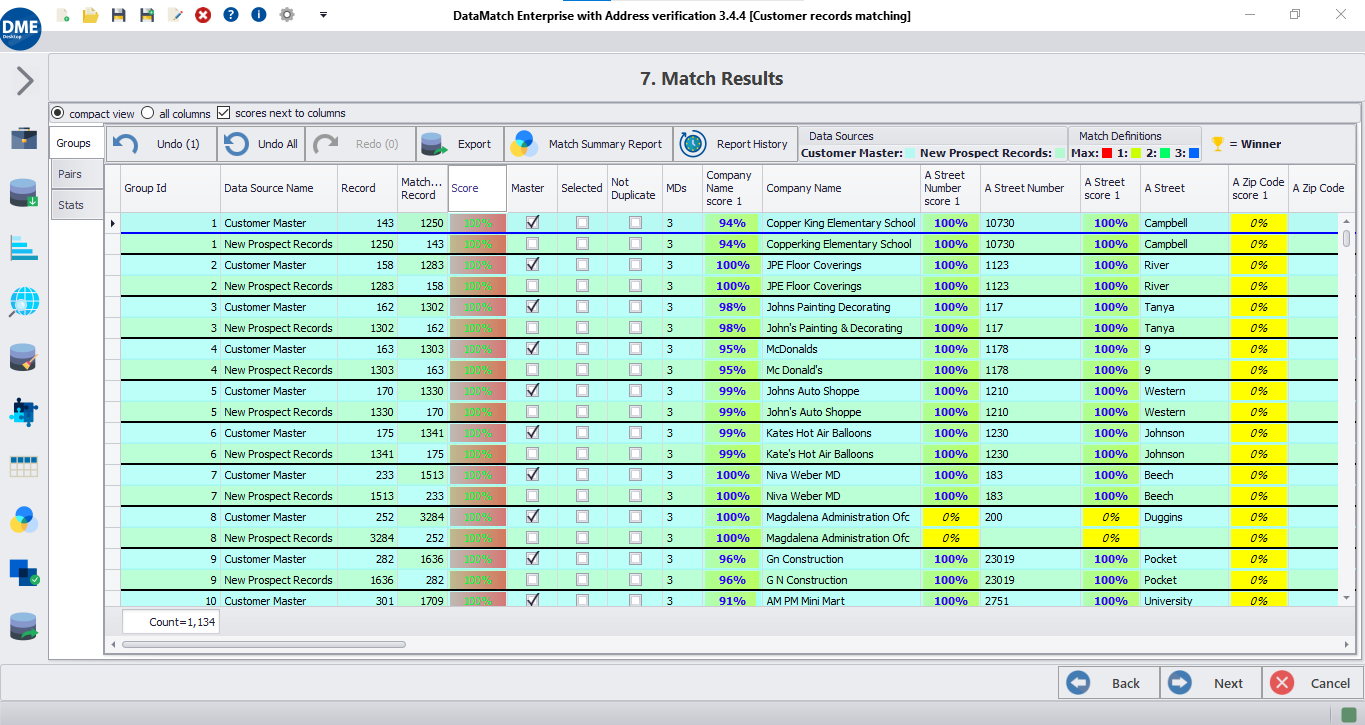
Configuration de la correspondance floue
Choisissez des pondérations appropriées (donnez la priorité à certains champs plutôt qu'à d'autres), des niveaux de seuil (définissez la limite entre les correspondances et les non-correspondances) et le type de correspondance floue (basée sur les caractères, phonétique, etc.).

Classification et évaluation
Les scores sont utilisés pour classer et regrouper les enregistrements en tant que correspondance ou non-correspondance. Selon la nature des données, vous pouvez rencontrer des résultats faussement positifs et négatifs qui nécessitent une évaluation plus approfondie.