





























Last Updated on février 16, 2022
Dans ce blog, nous allons examiner en détail la correspondance floue, l’approche de référence pour la déduplication des données et le couplage des enregistrements. Nous allons couvrir :
- Qu’est-ce que l’appariement flou ?
- Pourquoi les entreprises ont-elles besoin de la correspondance floue ?
- Exemple d’un scénario de correspondance floue dans le monde réel
- Techniques d’appariement floues
- Avantages et inconvénients de la correspondance floue
- Comment réduire au minimum les faux positifs et négatifs ?
- Scripts de mise en correspondance floue ou logiciel de mise en correspondance floue : Lequel est le meilleur ?
- Comment exécuter la correspondance floue dans DataMatch Enterprise
Qu’est-ce que l’appariement flou ?
Plutôt que de marquer les enregistrements comme « correspondants » ou « non correspondants », la correspondance floue identifie la probabilité que deux enregistrements correspondent vraiment, selon qu’ils sont en accord ou en désaccord sur les différents identifiants.
Les identifiants ou paramètres que vous choisissez ici et la pondération que vous leur attribuez constituent la base de la correspondance floue. Si les paramètres sont trop larges, vous trouverez plus de correspondances, certes, mais vous augmenterez aussi invariablement les risques de « faux positifs ». Il s’agit de paires identifiées par votre algorithme ou le logiciel de correspondance floue de votre choix comme une correspondance, mais après un examen manuel, vous constaterez que votre approche a identifié un faux positif.
Considérons les chaînes de caractères « Kent » et « 10th« . Bien qu’il n’y ait manifestement pas de correspondance ici, les algorithmes de correspondance floue les plus répandus considèrent que ces deux chaînes de caractères sont similaires à près de 50 %, sur la base du nombre de caractères et de la correspondance phonétique. Vérifiez par vous-même.
Les faux positifs sont l’un des principaux problèmes de la correspondance floue. Plus le système que vous utilisez est efficace, moins il y a de faux positifs. Un système efficace permettra d’identifier :
- Acronymes
- inversion du nom
- variations de noms
- orthographes phonétiques
- fautes d’orthographe délibérées
- erreurs d’orthographe par inadvertance
- les abréviations, par exemple « Ltd » au lieu de « Limited ».
- insertion/suppression de la ponctuation, des espaces, des caractères spéciaux
- orthographe différente des noms, par exemple « Elisabeth » ou « Elizabeth », « Jon » au lieu de « John ».
- les noms raccourcis, par exemple « Elizabeth » correspond à « Betty », « Beth », « Elisa », « Elsa », « Beth », etc.
Et bien d’autres variations.
Pourquoi les entreprises ont-elles besoin de la correspondance floue ?
Des études révèlent que 94 % des entreprises admettent avoir des données en double, et la majorité de ces doublons ne sont pas des correspondances exactes et passent donc généralement inaperçus. Le logiciel de correspondance floue vous aide à établir ces liens automatiquement à l’aide d’une logique de correspondance propriétaire sophistiquée, sans tenir compte des fautes d’orthographe, des données non normalisées ou des informations incomplètes.
Mais il ne s’agit pas seulement de déduplication. D’un point de vue stratégique, la correspondance floue entre en jeu lorsque vous effectuez un couplage d’enregistrements ou une résolution d’entités. Nous l’avons également abordé brièvement dans la section précédente ; l’approche de la correspondance floue est inestimable pour créer une source unique de vérité pour l’analyse d’entreprise ou pour jeter les bases de la gestion des données de référence (MDM), en aidant les organisations à intégrer des données provenant de dizaines de sources différentes à travers l’entreprise, tout en garantissant l’exactitude et en minimisant la révision manuelle. Découvrez comment un important prestataire de soins de santé a pu économiser des centaines d’heures de travail par an.
Voici quelques exemples de l’utilisation de la correspondance floue pour améliorer les résultats :
- Obtenir une vision unique du client
- Travaillez avec des données propres auxquelles vous pouvez faire confiance
- Préparer les données pour la Business Intelligence
- Améliorer la précision de vos données pour une meilleure efficacité opérationnelle
- Enrichir les données pour approfondir les connaissances
- Assurer une meilleure conformité
- Affiner la segmentation de la clientèle
- Améliorer la prévention des fraudes
En savoir plus sur les avantages de la correspondance floue.
Exemple d’un scénario de correspondance floue dans le monde réel
L’exemple suivant montre comment les techniques de couplage d’enregistrements peuvent être utilisées pour détecter la fraude, le gaspillage ou l’abus des programmes du gouvernement fédéral. Ici, deux bases de données ont été fusionnées pour obtenir des informations qui n’étaient pas disponibles auparavant dans une seule base de données.
Une base de données constituée d’enregistrements sur 40 000 pilotes d’avion titulaires d’une licence de l’Administration fédérale de l’aviation (FAA) des États-Unis et résidant en Californie du Nord a été mise en correspondance avec une base de données constituée d’individus recevant des paiements d’invalidité de l’Administration de la sécurité sociale. Quarante pilotes dont les dossiers figuraient dans les deux bases de données ont été arrêtés.
Un procureur du bureau du procureur des États-Unis à Fresno, en Californie, a déclaré, selon un rapport de l’AP :
« Il y a probablement eu un acte criminel répréhensible. » Soit les pilotes mentaient à la FAA, soit ils recevaient indûment des avantages. Les pilotes prétendaient être médicalement aptes à piloter des avions. Cependant, il se peut qu’ils aient volé avec des maladies débilitantes qui auraient dû les retenir au sol, allant de la schizophrénie et des troubles bipolaires à la toxicomanie et à l’alcoolisme, en passant par des problèmes cardiaques. »
Au moins douze de ces personnes « avaient des licences de transport commercial ou aérien », indique le rapport. La FAA a révoqué 14 licences de pilotes. Il s’est avéré que les autres pilotes mentaient sur leurs maladies afin de percevoir des prestations de sécurité sociale.
La qualité de la mise en relation des fichiers dépendait fortement de la qualité des noms et adresses des pilotes brevetés dans les deux fichiers mis en relation. La détection de la fraude dépendait également de l’exhaustivité et de l’exactitude des informations contenues dans une base de données particulière de la Social Security Administration.
Découvrez comment les entreprises de votre secteur utilisent la correspondance floue aujourd’hui.
Techniques d’appariement floues
Vous savez maintenant ce qu’est le fuzzy matching et les différentes façons de l’utiliser pour développer votre activité. La question est la suivante : comment envisagez-vous de mettre en œuvre des processus de correspondance floue dans votre organisation ?
Voici une liste des différentes techniques de correspondance floue utilisées aujourd’hui :
- Distance de Levenshtein (ou distance d’édition)
- Distance Damerau-Levenshtein
- Distance entre Jaro-Winkler
- Distance du clavier
- Distance de Kullback-Leibler
- Indice Jaccard
- Métaphone 3
- Variante du nom
- Alignement des syllabes
- Acronyme
Obtenez plus d’informations sur les algorithmes de correspondance floue.
Avantages et inconvénients de la correspondance floue
Puisque la correspondance floue est basée sur une approche probabiliste pour identifier les correspondances, elle peut offrir une large gamme d’avantages tels que :
– Une meilleure précision de la correspondance: la correspondance floue s’avère être une méthode bien plus précise pour trouver des correspondances entre deux ou plusieurs ensembles de données. Contrairement à la correspondance déterministe qui détermine les correspondances sur une base de 0 ou 1, la correspondance floue peut détecter les variations qui se situent entre 0 et 1 sur un seuil de correspondance donné.
–Fournit des solutions à des données complexes :la logique floue permet également aux utilisateurs de trouver des correspondances en reliant des enregistrements constitués de légères variations sous forme d’erreurs d’orthographe, de casse et de formatage, de valeurs nulles, etc., ce qui la rend mieux adaptée aux applications du monde réel où des fautes de frappe, des erreurs système et d’autres erreurs de données peuvent se produire. Cela inclut également les données dynamiques qui deviennent obsolètes ou doivent être mises à jour en permanence, comme le titre du poste et l’adresse électronique.
–Facilement configurable pour agir sur les faux positifs : lorsque le nombre de faux positifs doit être réduit ou augmenté pour répondre aux besoins de l’entreprise, les utilisateurs peuvent facilement ajuster le seuil de correspondance pour manipuler les résultats ou avoir plus de correspondances pour une inspection manuelle. Les utilisateurs disposent ainsi d’une plus grande souplesse pour adapter les algorithmes de logique floue à des exigences de correspondance spécifiques.
– Mieux adapté à la recherche de correspondances sans identifiant unique cohérent : il est essentiel de disposer de données d’identification uniques, telles que le SSN ou la date de naissance, pour trouver des correspondances entre des sources de données disparates dans le cas d’une correspondance déterministe. Cependant, en utilisant une approche d’analyse statistique, la correspondance floue peut aider à trouver des doublons même sans données d’identification cohérentes.
Cependant, la correspondance floue n’est pas sans limites. Il s’agit notamment de :
– Peut lier incorrectement différentes entités : malgré la configurabilité disponible dans la correspondance floue, un nombre élevé de faux positifs dus à une liaison incorrecte d’entités apparemment similaires mais différentes peut entraîner une augmentation du temps passé à vérifier manuellement les doublons par rapport aux identifiants uniques.
– Difficulté de mise à l’échelle sur des ensembles de données plus importants : la logique floue peut être difficile à mettre à l’échelle sur des millions de points de données, notamment dans le cas de sources de données disparates.
– Peut nécessiter des tests considérables pour être validé : les règles définies dans les algorithmes doivent être constamment affinées et testées pour garantir qu’il est possible d’exécuter des correspondances avec une grande précision.
Comment réduire au minimum les faux positifs et négatifs ?
Nous avons abordé brièvement les faux positifs dans la section précédente. Bien qu’ils rendent la correspondance plus difficile en ajoutant un temps de révision manuelle au processus, ils ne constituent pas un risque réel pour l’entreprise, car le système signalera les faux positifs en fonction du score de correspondance global. Examinons maintenant les « faux négatifs ». Il s’agit des matches qui ne sont pas du tout pris en compte par le système : il ne s’agit pas seulement d’un score de match faible, mais d’une absence de score de match. Cela entraîne un risque sérieux pour l’entreprise, car les faux négatifs ne sont jamais examinés, car personne ne sait qu’ils existent. Les facteurs qui conduisent généralement à des faux négatifs sont les suivants :
- Manque de données pertinentes
- Erreurs significatives dans la saisie des données
- Limites du système
- Le critère de correspondance est trop étroit
- Niveau inapproprié de la correspondance floue
La méthode la plus efficace pour minimiser les faux positifs et négatifs est de profiler et de nettoyer les sources de données séparément avant de procéder au rapprochement. Les principaux fournisseurs de solutions de rapprochement de données proposent généralement un profileur de données qui fournit rapidement suffisamment de métadonnées pour construire une analyse de profil convaincante de la qualité des données, comme les valeurs manquantes, le manque de standardisation, ou toute autre anomalie dans vos données. En établissant le profil de vos données, vous pouvez rapidement quantifier la portée et la profondeur du projet principal, qu’il s’agisse de la gestion des données de référence, du rapprochement, du nettoyage, de la déduplication ou de la normalisation.
Une fois que vous aurez établi le profil de vos données, vous saurez exactement quelles règles de gestion appliquer pour nettoyer et normaliser vos données le plus efficacement possible. Vous serez également en mesure de reconnaître et de combler rapidement les valeurs manquantes, peut-être en achetant des données de tiers.
Des données plus propres et plus complètes réduisent considérablement les faux positifs et négatifs en augmentant la précision des correspondances, car vos données sont désormais normalisées. Les algorithmes de correspondance floue que vous utilisez, les critères de correspondance que vous définissez, le poids que vous attribuez aux différents paramètres, la façon dont vous combinez les différents algorithmes et leur attribuez une priorité – ce sont tous des facteurs importants pour minimiser les faux positifs et négatifs également. Mais rien de tout cela ne sera d’une grande utilité si vous n’avez pas d’abord profilé et nettoyé vos données. Découvrez comment DataMatch Enterprise a aidé plus de 4 000 clients dans plus de 40 pays à nettoyer, dédupliquer et relier efficacement leurs données.
Scripts d’appariement flou ou logiciel d’appariement flou : Lequel est le meilleur ?
Scripts de correspondance floue
La logique floue peut facilement être appliquée à partir de scripts de codage manuel qui sont disponibles dans divers langages de programmation et applications. En voici quelques-unes :
– Python : Les bibliothèques Python telles que FuzzyWuzzy peuvent être utilisées pour exécuter la correspondance des chaînes de caractères de manière simple et intuitive. En utilisant le Python Record Linkage Tookit, les utilisateurs peuvent exécuter plusieurs méthodes d’indexation, y compris le voisinage trié et le blocage, et identifier les doublons en utilisant FuzzyWuzzy. Bien que Python soit facile à utiliser, l’exécution des correspondances peut être plus lente que d’autres méthodes.
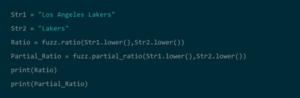
Source : DataCamp
– Java : Java comprend plusieurs algorithmes de similarité de chaînes de caractères, comme le paquet java-string-similarity qui comprend des algorithmes tels que Levenshtein, l’indice Jaccard et Jaro-Wrinkler. Il est également possible d’utiliser l’algorithme FuzzyWuzzy de Python dans Java pour exécuter les correspondances. Voici un exemple ci-dessous :

Source : GitHub
– Excel : Le module complémentaire Fuzzy Look-up peut être utilisé pour effectuer une correspondance floue entre deux ensembles de données. L’add-in possède une interface simple qui permet de sélectionner les colonnes de sortie ainsi que le nombre de correspondances et le seuil de similarité. Cependant, cette fonctionnalité peut également donner des faux positifs élevés, car elle peut ne pas identifier correctement les doublons. Par exemple, « ATT CORP » et « AT&T Inc. ».
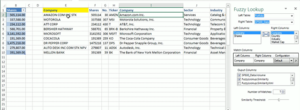
Source : Mr.Excel.com
Logiciel de correspondance floue
D’autre part, les logiciels de mise en correspondance floue sont équipés d’un ou plusieurs algorithmes de logique floue, ainsi que d’une mise en correspondance exacte et phonétique, afin d’identifier et de mettre en correspondance des enregistrements parmi des millions de points de données provenant de sources de données multiples et disparates, notamment des bases de données relationnelles, des applications Web et des CRM.
Les outils de comparaison floue sont dotés de fonctions de qualité des données prédéfinies, telles que le profilage, le nettoyage et la normalisation des données, afin d’affiner et d’améliorer efficacement la précision des correspondances entre deux ou plusieurs ensembles de données.
Contrairement aux scripts de correspondance, ces outils sont beaucoup plus faciles à déployer et à exécuter grâce à une interface de type pointer-cliquer.
Lequel est le meilleur ?
Le choix de l’une ou l’autre de ces deux approches dépend des facteurs suivants :
Temps
Les scripts de correspondance ont l’avantage d’être faciles à déployer à la convenance des utilisateurs. Toutefois, le perfectionnement et les tests constants nécessaires pour garantir son efficacité, en particulier sur des centaines et des milliers d’enregistrements, peuvent nécessiter des semaines, voire des mois de travail. Dans les scénarios où les doublons et les concordances doivent être trouvés plus rapidement pour respecter les délais serrés d’un projet, un outil de concordance floue s’avère beaucoup plus fiable et pratique pour effectuer des concordances dans de très grands ensembles de données en quelques jours ou quelques heures.
Coût
Les scripts de codage manuel sont peu coûteux à utiliser par rapport aux outils de comparaison, à condition que le nombre d’enregistrements soit faible. Toutefois, pour les ensembles de données comprenant des millions ou des milliards d’enregistrements, le coût de l’utilisation de scripts peut largement dépasser celui des outils de mise en correspondance, compte tenu du temps et des ressources nécessaires pour répondre aux besoins des utilisateurs.
Évolutivité
Les scripts de logique floue ont tendance à mieux fonctionner pour quelques milliers d’enregistrements, lorsque les variations de données ne sont pas trop importantes, sinon les règles peuvent s’effondrer et nécessiter plus de raffinement, ce qui rend difficile leur extension.
Un outil de comparaison floue est équipé de la capacité d’effectuer des comparaisons avec des millions de points de données en quelques heures, ainsi que de capacités d’automatisation par lots et en temps réel afin de minimiser les tâches répétitives et les heures de travail.
Complexité des données
Les utilisateurs peuvent vouloir trouver des correspondances ou des doublons dans quelques milliers d’enregistrements. En revanche, les agences fédérales, les institutions publiques et les entreprises disposent souvent d’ensembles de données non homogènes provenant de sources multiples (Excel, CSV, bases de données relationnelles, données d’anciens ordinateurs centraux et référentiels Hadoop).
Dans le cas des scripts de codage manuel, en revanche, les utilisateurs doivent rédiger de multiples règles complexes de logique floue pour tenir compte de la disparité des données et de leurs anomalies, ce qui est très fastidieux et prend beaucoup de temps.
C’est simple, rapide et axé sur la création de valeur pour l’entreprise.
Traditionnellement, l’appariement flou est considéré comme un art complexe et obscur, où les coûts des projets se chiffrent généralement en centaines de milliers de dollars, où il faut des mois, voire des années, pour obtenir un retour sur investissement tangible et où, même dans ce cas, des problèmes de sécurité, d’évolutivité et de précision subsistent. Ce n’est plus le cas avec les logiciels modernes de qualité des données. Basé sur des décennies de recherche et plus de 4 000 déploiements dans plus de 40 pays, DataMatch Enterprise est une application de nettoyage de données hautement visuelle, spécialement conçue pour résoudre les problèmes de qualité des données. La plateforme exploite plusieurs algorithmes propriétaires et standard pour identifier les variations phonétiques, floues, mal saisies, abrégées et spécifiques à un domaine.
Créez des configurations évolutives pour la déduplication et le couplage d’enregistrements, la suppression, l’enrichissement, l’extraction et la normalisation des données commerciales et clients et créez une source unique de vérité pour maximiser l’impact de vos données dans toute l’entreprise.
Comment l’exécuter dans DataMatch Enterprise
L’exécution du filtrage flou dans DataMatch Enterprise est un processus simple, étape par étape, comprenant les éléments suivants :
- Importation de données
- Profilage des données
- Nettoyage et normalisation des données
- Configuration des correspondances
- Définitions des correspondances et
- Résultats des matchs
Tout d’abord, nous importons les ensembles de données que nous utiliserons pour trouver des correspondances et nous utilisons l’option d’aperçu des données pour parcourir les enregistrements. Dans notre exemple, il s’agit de ‘Customer Master’ et ‘New Prospect Records’ comme indiqué ci-dessous.
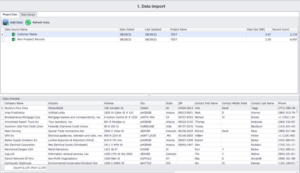
Ensuite, nous passons au module Profil des données pour identifier toutes sortes d’anomalies et d’erreurs dans les données statistiques, ainsi que les problèmes potentiels qui doivent être corrigés ou affinés avant de procéder à un rapprochement.
Comme indiqué ci-dessous, l’ensemble de données New Prospect Records est profilé en termes d’enregistrements valides et invalides, de valeurs nulles, distinctes, de chiffres uniquement, de lettres uniquement, d’espaces avant, d’erreurs de ponctuation, et bien plus encore.
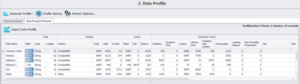
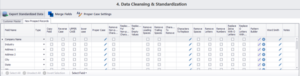
Après avoir établi le profil, nous passons au module de nettoyage et de normalisation des données, où nous corrigeons les erreurs de casse, supprimons les espaces de fin et de début, remplaçons les zéros par des os et vice versa, et analysons les champs tels que le nom et l’adresse en plusieurs incréments plus petits.
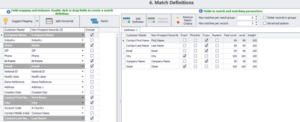
Après avoir affiné nos données, nous sélectionnons le type de configuration de correspondance dont nous avons besoin pour notre activité de mise en correspondance : Tous, Entre, Dans, ou Aucun. Pour notre exemple, nous allons sélectionner Entre pour trouver des correspondances uniquement entre les deux ensembles de données.

Dans Définitions de la correspondance, nous allons sélectionner la définition de la correspondance ou les critères de correspondance et « Fuzzy » (en fonction de notre cas d’utilisation), définir le niveau du seuil de correspondance à « 90 » et utiliser la correspondance « Exact » pour les champs Ville et État, puis cliquer sur « Correspondance ».
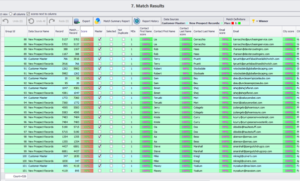
Sur la base de notre définition de la correspondance, de notre ensemble de données et de l’étendue du nettoyage et de la normalisation, nous obtenons 526 correspondances, chacune avec un score de correspondance correspondant de 100 % et moins. Si nous avons besoin de plus de faux positifs à inspecter manuellement, les utilisateurs peuvent facilement revenir en arrière et abaisser le niveau du seuil.
Pour plus d’informations sur la façon dont vous pouvez déployer la correspondance floue dans DataMatch Enterprise pour votre cas d’utilisation commerciale,
contactez-nous dès aujourd’hui.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Télécharger
Les entreprises ont besoin des meilleurs outils pour traiter ces données et leur donner un sens. Ce livre blanc explore les défis du rapprochement, le fonctionnement des différents types d’algorithmes de rapprochement et la manière dont les meilleurs logiciels utilisent ces algorithmes pour atteindre les objectifs de rapprochement des données.



