




























Last Updated on marzo 4, 2022
En este blog, hablaremos de lo que es la concordancia de datos y de los siguientes beneficios que ayudan a las empresas a mejorar la inteligencia empresarial y a tener un impacto directo en los resultados finales:
- Crear registros «dorados» para su uso posterior
- Trabaje con datos limpios en los que pueda confiar
- Preparar los datos para la inteligencia empresarial
- Aumentar la precisión de los datos
- Enriquecer los datos para profundizar en la información
- Afinar la segmentación de los clientes
- Garantizar un mejor cumplimiento
- Automatizar la prevención del fraude
¿Qué es la concordancia de datos?
El cotejo de datos -también conocido como vinculación de registros y resolución de entidades- se refiere a la tarea de identificar y asignar dos registros aparentemente diferentes como uno y el mismo en múltiples fuentes de datos.
Al encontrar coincidencias más precisas, las organizaciones pueden identificar más fácilmente los registros duplicados y optar por fusionarlos. Seleccione un registro maestro y descarte las demás entradas idénticas. Además, identifique las posibles coincidencias que en realidad son entidades diferentes.
Por esta razón, el cotejo de datos se considera la función más importante después de las actividades de perfilado, limpieza y normalización.
De este modo, el cotejo de datos permite a las organizaciones tener una visión más completa de cada entidad. Cliente, estudiantes, paciente, etc. – descartando los valores duplicados y garantizando que los datos que residen en sus sistemas de información son limpios y precisos.
¿Cómo funciona el cotejo de datos?
Elcotejo de datos se basa en varios algoritmos para analizar los registros y encontrar coincidencias con entradas similares. Sin embargo, el enfoque exacto para cotejar los datos varía en función de si el cotejo es determinista o probabilístico.
En la concordancia determinista, las coincidencias se identifican en función de la exactitud de dos o más entradas; sobre una base de 0 o 1. Los algoritmos utilizan reglas y patrones establecidos para determinar las puntuaciones para determinar una coincidencia.
La concordancia probabilística, en cambio, identifica las coincidencias basándose en una puntuación de coincidencia por encima de un determinado umbral que se sitúa entre 0 y 1.
Los algoritmos de lógica difusa, como Jaro-Wrinkler, determinan las probabilidades basándose en las asociaciones y pesos de los datos de los identificadores únicos (valores que no cambian con el tiempo. Por ejemplo, el número de la Seguridad Social y la fecha de nacimiento). Y para identificar el grado de coincidencia de un registro concreto con otros registros.
¿Cómo se aplica la concordancia de datos en los distintos sectores?
Aunque el resultado del cotejo de datos es encontrar registros más precisos y únicos de entre varios registros similares. La aplicación difiere de una industria a otra. A continuación se explica cómo se aplica la correspondencia de datos en múltiples contextos:
- Gobierno y sector público: las agencias federales y las instituciones públicas confían en la resolución de entidades mediante el examen de datos PII como el SSN, el pasaporte y los números de licencia para detectar el fraude y cumplir con las normas de cumplimiento. Y realizar análisis políticos.
Un ejemplo de ello es el Departamento de Justicia (DOJ), que tramita varios miles de solicitudes de la FOIA. Cada una de ellas debe ser interpretada adecuadamente, comunicada al solicitante. Y se ha investigado a fondo.
Mediante el cotejo de datos, la agencia pudo identificar los duplicados y reducir un campo de 4 a 3 millones de registros. Que se redujeron a 4.000 registros tras el filtrado. Toda la actividad de deduplicación duró sólo cuatro horas, lo que de otro modo habría llevado varias semanas si se hubiera hecho manualmente. - Educación: cotejo de datos entre fuentes dispares, como la información demográfica de alumnos y profesores, y otras para medir el rendimiento de los estudiantes. Distinguir los métodos de enseñanza exitosos de los no exitosos, analizar los cambios en la calificación. E identificar las iniciativas políticas a partir de los datos del SLDS.
Un estado llevó a cabo un programa de vinculación de registros con una muestra y evaluó el número de estudiantes en un año que asistieron a la educación post-secundaria en una ciudad específica. Con el antiguo programa existente, la muestra reveló que el 22% de los 5.344 estudiantes de esa ciudad habían accedido a la educación superior.
Tras la solución de cotejo de datos de Data Ladder, esa cifra subió a casi el 41%. Casi el doble de la primera cifra. Para más información, lea el estudio de caso del SLDS.
- Banca y finanzas: los bancos y las instituciones de servicios financieros utilizan el cotejo de datos para identificar a los culpables como parte de las iniciativas contra el blanqueo de dinero, cumplir con los requisitos de cumplimiento de KYC o llevar a cabo la puntuación de crédito FICO.
Bell Bank llevó a cabo un cotejo de datos con DataMatch Enterprise para conseguir una visión única y consolidada de sus clientes y proveedores repartidos en múltiples líneas de servicios. De la jubilación a la gestión del patrimonio.
Gracias al matching, Bell Bank pudo encontrar y seguir el recorrido de cada cliente en los diferentes servicios bancarios y reducir los costes operativos. Para más información, lea el estudio de caso del Bell Bank.
- Sanidad: las organizaciones sanitarias utilizan la coincidencia de pacientes en múltiples registros de HCE y bases de datos a través de identificadores únicos como ONC, USPS y CAQH para obtener una visión única del paciente y determinar el diagnóstico correcto y la prescripción correcta de medicamentos.
John Associates utilizó la limpieza de datos y el emparejamiento para ampliar la deduplicación de los registros de los candidatos a la contratación. Así se ahorran cientos de horas de limpieza y cotejo de registros. Haga clic aquí para obtener más información.
- Ventas y marketing: las empresas a menudo necesitan encontrar coincidencias para eliminar contactos duplicados y erróneos dentro de las bases de datos relacionales y de CRM. La visión única del cliente resultante permite a las empresas mejorar las actividades de venta cruzada y de incremento de ventas, y mejorar las campañas de marketing omnicanal. Y aumentar el retorno de la inversión en marketing.
TurnKey Auto Events -una empresa de servicios de marketing para concesionarios de automóviles- buscaba conciliar las ventas de los socios de los concesionarios con los clientes potenciales para obtener crédito de ventas.
Utilizando DataMatch Enterprise, cotejaron registros de varias fuentes para crear una visión consolidada y única de las posibles ventas de coches. Y en un tiempo mínimo, eliminar los duplicados y limpiar los registros en el proceso. Para más información, lea el estudio de caso de TurnKey Auto Events.
Ventajas de la comparación de datos
Disponer de una sólida herramienta de cotejo de datos como parte de su marco de gestión de la calidad de los datos puede reportar una amplia gama de beneficios, como por ejemplo
1. Crear registros «dorados» para su uso posterior

Cotejo y depuración de datos ayuda a identificar, cotejar y fusionar los registros almacenados en los distintos sistemas de información, consolidando los datos y creando una visión única del cliente. Mientras que algunos campos de datos, como el nombre, el número de teléfono, la dirección, etc., son los mismos en la mayoría de las aplicaciones. Algunos sistemas utilizan tecnologías de seguimiento para proporcionar una visión más profunda del cliente.
Por ejemplo, los datos recogidos a través de herramientas de automatización del marketing como Hubspot y Marketo suelen ser exhaustivos. Proporcionar un historial completo de cómo un cliente potencial interactuó con su empresa a través de Internet.
En cambio, si el mismo cliente visita el punto de venta de la empresa en persona. La cantidad de datos que el representante recogería e introduciría en el sistema CRM comprende menos detalles. Además, existe la posibilidad de que haya discrepancias en la información debido a un error humano.
Con el cotejo de datos, las empresas pueden tener una única fuente de verdad: los datos disponibles en diferentes bases de datos y conjuntos de datos se contarán y consolidarán. Y se fusionan para formar un registro de datos maestro o registro «dorado», que contiene toda la información que se tiene sobre un cliente potencial o potencial en particular.
Con una visión completa del cliente, puede alinear mejor sus estrategias de marketing y ventas. Tener acceso a datos concretos para la elaboración de informes y análisis. Y, en última instancia, tomar decisiones empresariales bien fundamentadas para obtener un mayor rendimiento de la inversión y un mayor crecimiento del negocio.
2. Trabaje con datos limpios en los que pueda confiar
Las empresas utilizan una amplia red de sistemas de información y aplicaciones que están intrincadamente unidas para formar la infraestructura de datos interna.
Dado que los datos de los consumidores se recogen de varios canales de comunicación. Existe una alta probabilidad de discrepancia en la información introducida a través de diferentes medios.
Pensemos en un posible cliente, James O’Quinn, que vive en Carolina del Norte y trabaja en Fiserv. Hace clic en uno de sus anuncios de Google y visita una página de aterrizaje que ofrece un libro blanco. Rellena el formulario de contacto con los siguientes datos:
| Nombre | Envíe un correo electrónico a | Número de teléfono | Ubicación |
| James O’Quinn | j.oquinn@fiserv.com | +184 222 483 | Carolina del Norte |
Esta información se almacena en la base de datos de su CRM. Al leer el libro blanco. James decide suscribirse a su boletín mensual. Para ello tiene que rellenar un formulario de contacto independiente en su sitio web. En esa forma. Introduce su dirección de correo electrónico personal en lugar de la empresarial.
| Nombre | Envíe un correo electrónico a | Número de teléfono | Ubicación |
| James Quinn | jim.oq@gmail.com | +184 222 483 | N. Carolina |
Se crea un nuevo registro en su CRM que muestra a James como un nuevo cliente potencial, ya que el nombre y la dirección de correo electrónico son diferentes esta vez.
Unas semanas después, James visita una feria y se relaciona con su empresa. Se compromete con su representante y toma información sobre las soluciones que usted ofrece. Muestra interés y proporciona a su representante los datos de contacto de su empresa. Su representante registra la siguiente información:
| Nombre | Envíe un correo electrónico a | Número de teléfono | Ubicación |
| Jim Quinn | j.oquinn@fiser.com | +184 222 2482 | Carolna del Norte |
A continuación se presenta una instantánea compilada de toda la información que James proporcionó durante sus diversas interacciones con su negocio:
| Interacción | Nombre | Envíe un correo electrónico a | Número de teléfono | Ubicación |
| Inscripción en el Libro Blanco | James O’Quinn | j.oquinn@fiserv.com | +184 222 483 | Carolina del Norte |
| Suscripción al boletín de noticias | James Quinn | james.oq@gmail.com | +184 222 483 | N. Carolina |
| Feria de muestras | Jim Quinn | j.oquinn@fiserv.com | +184 222 2482 | Carolna del Norte |
Las variaciones en la información son bastante evidentes. Ahora, existen tres registros que apuntan a la misma entidad, a través de diferentes sistemas dentro de la organización.
Tener varios registros para la misma persona puede dar lugar a varios problemas. Por ejemplo, enviar un mismo correo electrónico varias veces y además con la ortografía del nombre equivocada. Lo que puede tener un impacto significativo en la experiencia del cliente incluso antes de que se convierta en un potencial cliente potencial.
Este es sólo un ejemplo de los cientos de escenarios en los que los registros duplicados pueden afectar a su negocio.
Ahí es donde la limpieza de datos y la deduplicación. Las herramientas de correspondencia de datos como DataMatch Enterprise aprovechan la mejor tecnología de correspondencia difusa de su clase. Para identificar los registros duplicados dispersos en sus distintos repositorios de datos.
Asignación de puntuaciones al grado de coincidencia encontrado para poder evitar los falsos positivos.
La solución también permite perfilar sus datos en cuestión de minutos para que conozca los problemas que existen en los datos de la empresa, y los corrija mediante nuestras opciones de estandarización y limpieza, y luego los empareje para limpiar los duplicados.
Además de mejorar la experiencia del cliente, la deduplicación reduce el número de registros en una base de datos. Lo que conduce a un menor consumo de espacio, así como disminuye la carga en el cliente y el servidor cada vez que una aplicación llama a los datos para su procesamiento.
3. Preparar los datos para la inteligencia empresarial
Antes de que los datos puedan ser utilizados para cualquier proceso o aplicación, lo que también se conoce como preprocesamiento de datos. Un paso importante en el aprendizaje automático.
Debe estar preparado para cumplir con los requisitos de esa operación en particular. Para hacerse una idea de la importancia de la preparación de los datos. Se gastan unos 22.000 dólares por analista de datos al año para preparar los datos de la empresa con fines de información y análisis.
Un proyecto típico de análisis y aprendizaje automático implica el uso de datos de unas 6 o más fuentes . Debido a la disparidad de formatos de datos entre las bases de datos, sólo hay que preparar los datos -limpiarlos y normalizarlos-.
Así que se puede analizar para la inteligencia empresarial ocupa el 80% del tiempo total dedicado al proceso, con sólo el 20% del tiempo dedicado al análisis real.
Para aliviar la carga y deshacerse de la dependencia de los recursos informáticos, las herramientas de cotejo de datos ofrecen sólidas capacidades de preparación de datos de autoservicio. Garantizar que cada conjunto de datos esté formado por el mismo tipo de datos.
Las herramientas de cotejo de datos automatizan el proceso de tamizado de los datos brutos a través de múltiples capas, la elaboración de perfiles, la limpieza, la deduplicación y la fusión para obtener información precisa a través de los análisis.
Con DataMatch Enterprise, puede estandarizar y limpiar cientos de millones de registros dentro y entre las fuentes de datos para normalizarlos. Convierta las anotaciones (número de casa, número de casa, H# a número de casa) en lo que su sistema reconoce, cambie las mayúsculas y minúsculas, elimine caracteres o palabras específicas, fusione campos y cientos de cosas más.
También se trata de convertir los datos numéricos, como los números de teléfono, al formato designado.Y el mismo patrón se sigue para el resto de los campos.
Una vez completados estos pasos, puede ejecutar sus datos a través del proceso de coincidencia/deduplicación. O exportarlo a su almacén de datos para la elaboración de informes analíticos y análisis posteriores.
La preparación de los datos mediante el cotejo garantiza que sus datos tengan una estructura adecuada. Y está preparada para que los sistemas de BI recojan los datos con precisión y generen ideas de alta calidad.
4. Aumentar la precisión de los datos
Para que las empresas tengan éxito, deben utilizar sus limitados recursos de la manera más eficiente posible. Sin embargo, los recursos humanos y de capital suelen desperdiciarse debido a las malas decisiones basadas en registros y datos inexactos.
Con el cotejo de datos, las organizaciones pueden optimizar los niveles de precisión en todas las unidades de negocio. De este modo, se mejora la productividad del equipo y la eficiencia general. Por ejemplo, si el departamento de ventas tiene datos precisos sobre los clientes potenciales.
Los representantes dispondrán de mejores conocimientos para captar clientes potenciales con mayores posibilidades de convertirlos en clientes.
El cotejo de datos facilita la la normalización . Dado que los registros se almacenan en varios formatos, las herramientas de cotejo de datos ofrecen la posibilidad de definir un estándar.
Wnes que pueden aplicarse de forma generalizada. Esto facilita la clasificación de los datos en función de campos específicos, permitiendo a los usuarios acceder a datos completos y precisos en todo momento.
5. Enriquecer los datos para profundizar en la información
El cotejo de datos permite aprovechar las ventajas del enriquecimiento de datos. Se trata de fusionar datos de fuentes autorizadas de terceros con la base de datos interna existente.
Mejorar la calidad y la coherencia de los datos de los consumidores puede permitir a las empresas racionalizar mejor sus procesos de marketing, ventas, producción y otros.
La puntuación y la elaboración de perfiles suelen ser los pasos iniciales antes de que pueda producirse cualquier mejora de los datos.
Se verifican los datos de contacto de los consumidores y se marcan los datos dudosos. Y la información de las direcciones está estandarizada para garantizar que los datos inexactos no afecten a la inteligencia empresarial.
El siguiente paso consiste en recopilar información adicional de recursos externos para crear un perfil de consumidor más completo y con más datos.
Los datos procedentes de fuentes de terceros pueden incluir datos financieros, intereses sociales, datos sobre el automóvil y acontecimientos vitales. Que se pueden recopilar en base a la información adicional disponible en los canales de comunicación más fiables y preferidos.
Los datos enriquecidos rellenan las lagunas de los datos de los consumidores, proporcionándole una hoja de datos completa delos «qué» y «cómo» de su público objetivo. Esto le permite mejorar sus procesos empresariales para mejorar la experiencia general del cliente.
6. Afinar la segmentación de los clientes
Para cualquier campaña de marketing y ventas, la segmentación de clientes desempeña un papel fundamental, especialmente en las empresas de big data. De hecho, se sabe que las campañas de marketing impulsadas por la segmentación de clientes experimentan una media de Aumento del ROI en un 760%.
Los responsables de marketing de la generación de demanda suelen tener dificultades para definir los límites que desbaratan los esfuerzos de personalización de sus campañas de marketing. ¿El culpable? Datos inexactos e incompletos.
Ofrece una combinación de capacidades de enriquecimiento y verificación de datos. DLas herramientas de comparación de datos le ayudan a identificar y clasificar a su público objetivo en función de múltiples factores demográficos. Como los ingresos, el estado civil, la edad, el lugar de residencia, etc.
Disponer de información precisa y completa sobre los clientes le ayuda a definir claramente los intereses, comportamientos y otros factores socioeconómicos para crear segmentos.
Aque le permite añadir el toque de personalización en sus mensajes. Con el tipo de personalización adecuado, puede maximizar la eficacia de sus campañas de ventas y marketing elaborando mensajes más relevantes para sus clientes.
7. Garantizar un mejor cumplimiento
ElGDPR exige a las empresas que piensen cuidadosamente en sus estrategias de marketing para los mercados europeos. La concordancia de datos puede desempeñar un papel importante para garantizar el cumplimiento de esta normativa.
Antes de que las empresas puedan ponerse en contacto con un cliente, el GDPR les obliga a pedir permiso para utilizar las direcciones de correo electrónico y otros datos personales de un cliente en sus campañas de marketing.
Dado que la interacción con el cliente es omnicanal, resulta difícil obtener el permiso de los clientes. Cuando los datos son incoherentes y varían según las plataformas en línea. Deeste modo, aumenta el riesgo de incurrir en sanciones.
Pero con el cotejo de datos, las empresas pueden acotar y saber exactamente con qué cliente están tratando. Proporcionarles la posibilidad de pedir un permiso explícito.
Laconcordancia con la OFAC es otro caso de uso de la concordancia de datos que vemos cada vez más en Data Ladder. La Oficina de Control de Activos Extranjeros (OFAC), una división del Departamento del Tesoro de Estados Unidos. Esto crea listas negras de personas y países que se enfrentan a sanciones económicas o comerciales para proteger los intereses federales.
A efectos de cumplimiento, las organizaciones deben cotejar las listas de proveedores, incluidas las transacciones individuales, con las listas negras de la OFAC antes de hacer negocios, o arriesgarse a recibir fuertes sanciones.
El problema es que no siempre tendrá coincidencias exactas. Los proveedores incluidos en la lista negra pueden estar utilizando seudónimos, los datos podrían haber sido mal introducidos en su base de datos de proveedores. Lo que significa que su software de cotejo de datos puede pasar por alto coincidencias e incumplir la normativa.
Con nuestras soluciones, puede asegurarse de que los pagos y los proveedores se cotejan con las bases de datos de la OFAC. Ya sea en tiempo real o en cargas por lotes.
8. Automatizar la prevención del fraude
La mayoría de las instituciones sanitarias y los organismos reguladores soportan enormes pérdidas por pagos y reclamaciones fraudulentas debido a las relaciones ocultas entre entidades.
Los datos suelen estar en forma de registros informáticos que se han introducido en diferentes sistemas de los departamentos o sucursales.
Los estafadores y defraudadores se aprovechan de los múltiples registros almacenados en varios puntos de una organización. Creando discrepancias para dificultar el rastreo hasta el registro original verdadero.
En algunos casos, los empleados utilizan tácticas fraudulentas para falsificar registros, como informes financieros, recibos de compra, etc. para su beneficio personal.
El software de cotejo de datos utiliza algoritmos de cotejo difusos de primera clase para identificar las relaciones entre los diferentes registros. Lo que puede ayudar a descubrir la verdad detrás del fraude.
Esta técnica permite a las empresas volver sobre sus pasos, facilitando las investigaciones para llegar al origen del problema.
La mayoría de los organismos gubernamentales del Reino Unido participan en la Iniciativa Nacional contra el Fraude. Lo que les obliga a realizar un ejercicio de cotejo de datos por ordenador.
DataMatch Enterprise – El software de comparación de datos más rápido y preciso
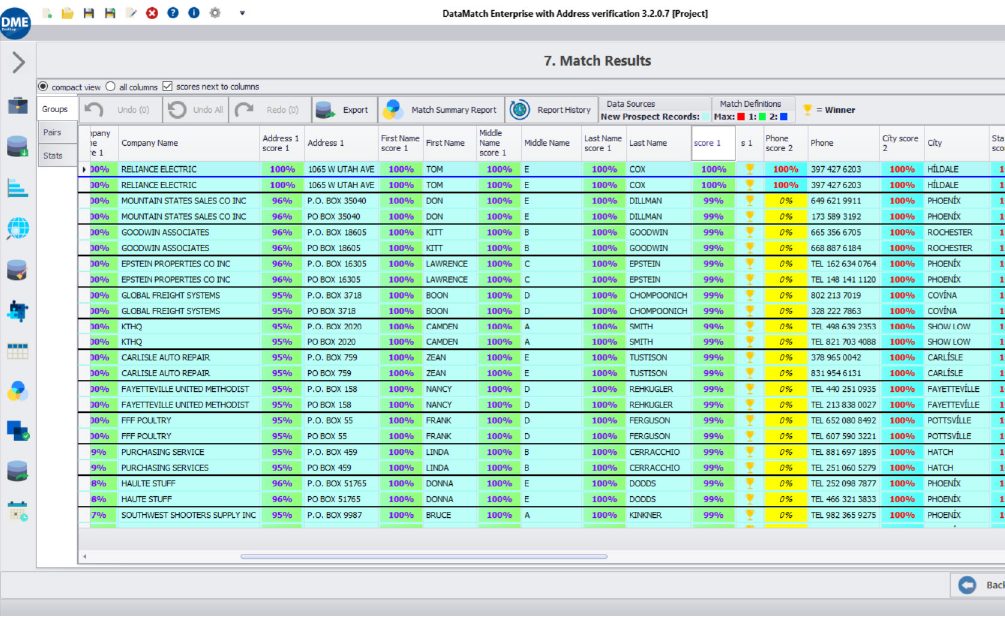
DataMatch Enterprise es una aplicación de limpieza de datos muy visual diseñada específicamente para resolver problemas de calidad de datos de clientes y contactos. La plataforma aprovecha múltiples algoritmos patentados y estándar para identificar variaciones fonéticas, difusas, con claves erróneas, abreviadas y específicas del dominio.
Construya configuraciones escalables para la deduplicación y la vinculación de registros, la supresión, la mejora, la extracción y la estandarización de datos empresariales y de clientes. Y cree una fuente única de verdad para maximizar el impacto de sus datos en toda la empresa.
Descargue la hoja de datos y vea cómo podemos ayudar a su empresa a crecer.



