




























Last Updated on marzo 17, 2022
Uso de Wordsmith para eliminar el ruido y estandarizar los datos a granel para obtener una mayor confianza en las coincidencias
Los datos que llegan a su organización tienen una gran variedad de formatos: mayúsculas incoherentes, signos de puntuación, oscuros acrónimos, caracteres alfanuméricos que viven en campos que no deberían estar, etc. Esto sucede porque sus datos viven en sistemas múltiples y dispares y cada uno tiene un formato y reglas ligeramente diferentes para almacenar los datos. El problema se agrava por los errores humanos en la introducción de datos.
Estas pequeñas diferencias pueden dar lugar a malentendidos y a interpretaciones erróneas de los datos de su organización, lo que hace que las personas que confían en esos datos desconfíen de ellos y pongan en marcha múltiples comprobaciones para asegurarse de que las conclusiones extraídas de esos datos son realmente correctas.
Cuando se cotejan datos de varias fuentes de datos, estas incoherencias pueden hacer que se pierdan coincidencias y que se produzcan falsos positivos, lo que disminuye la confianza en el proceso de cotejo de datos y hace que no se determinen los duplicados y los vínculos.
Con DataMatch Enterprise, nos centramos en ayudarle a
Sacar el máximo partido a sus datos
utilizando una variedad de transformaciones de normalización de datos incorporadas dentro de una interfaz de apuntar y hacer clic. En este blog, profundizaremos un poco más y nos centraremos en cómo puede utilizar nuestra función de firma WordSmith para mejorar aún más el proceso de cotejo y estandarizar sus datos en bloque.
¿Qué es WordSmith?
Wordsmith es una herramienta de la firma Data Ladder que permite perfilar, normalizar y eliminar el ruido de los datos de las columnas. También se pueden crear nuevas columnas automáticamente para analizar los datos transformados de las columnas existentes. Más adelante en este blog veremos casos de uso con ejemplos. La idea es aumentar la confianza y la precisión de las coincidencias garantizando la coherencia y minimizando la redundancia.
¿Cómo funciona WordSmith?
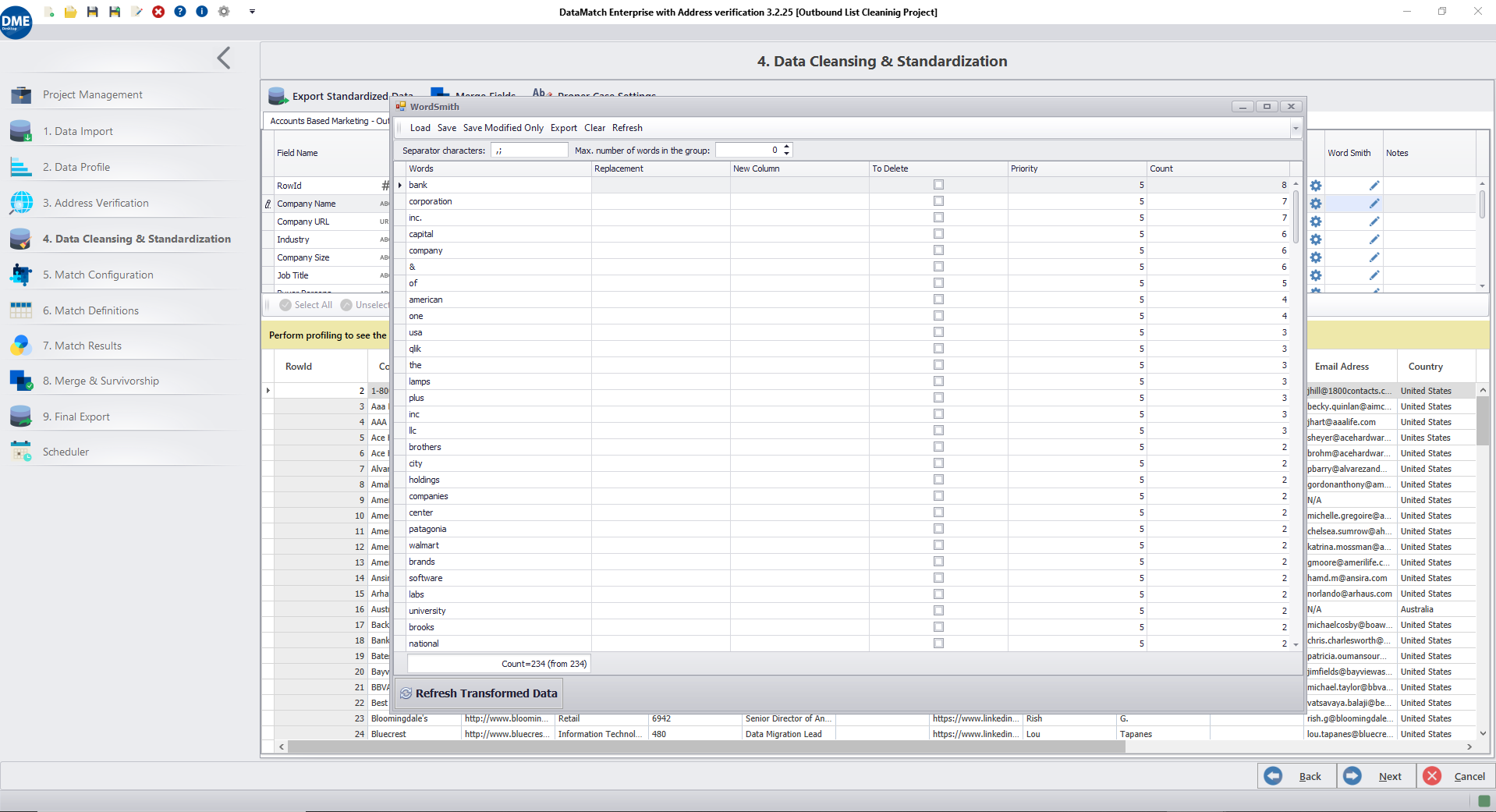
WordSmith se encuentra en la cuarta pestaña de DataMatch Enterprise. Esta pestaña contiene todas nuestras transformaciones de limpieza de datos pre-construidas. Como se muestra en la captura de pantalla anterior, puedes utilizar WordSmith para cualquier columna que elijas haciendo clic en el icono «editar». Esto abrirá una segunda ventana, como se muestra en la imagen.
La herramienta perfila la columna seleccionada y muestra las palabras en orden descendente según su número. Puede cambiar el número máximo de palabras agrupadas que la herramienta debe mostrar. Gracias a nuestra experiencia cotejando datos de más de 4.000 clientes de todo el mundo, sabemos que, por lo general, las palabras más repetitivas de una columna suelen ser las más desajustadas y, por tanto, afectan a la confianza de la cotejo.
La herramienta permite sustituir palabras, analizarlas en una nueva columna y eliminarlas. Estas funciones pueden utilizarse conjuntamente de diversas maneras para normalizar sus datos en bloque.
¿Cómo puedo normalizar los datos con WordSmith?
Veamos algunas de las formas más comunes en que nuestros clientes utilizan WordSmith.
Eliminación de datos ruidosos o redundantes
En la ciencia de los datos, el ruido es un dato que no añade ningún significado adicional a los datos y que, por lo general, sesga el análisis. Al cotejar los datos, la presencia de ruido hace que se pierdan coincidencias y se produzcan falsos positivos.
Digamos que, en la columna CompanyName, usted ve 3 empresas diferentes:
- ABC Inc.
- Empresa ABC
- Industrias ABC
Ahora, sabes que los 3 son la misma entidad. Pero al utilizar un software de comparación de datos, se perderían esas coincidencias. Con WordSmith, se pueden identificar estos casos estableciendo un máximo de. Número de palabras en un grupo a 2 o 3 y luego usar la opción Reemplazar para reemplazar las 3 frases que enumeramos arriba con «ABC» o cualquier formato estándar que prefiera para los nombres de las empresas.
El cambio se aplicaría automáticamente a todas las instancias de sus datos, independientemente de que tenga un centenar de registros o 10 millones.
Veamos un ejemplo más. Digamos que tiene las siguientes 3 empresas distintas en la columna CompanyName:
- XYZ Incorporated
- 123 Incorporado
- ABC Incorporated
Al realizar la coincidencia, estos registros pueden ser marcados como coincidentes debido a que la palabra Incorporada está presente en los 3. Un falso positivo. Con WordSmith, puede identificar tales instancias y utilizar la opción de eliminación para quitarla por completo de esta columna.
Filtrar o parsear datos en una nueva columna
Digamos que usted es una empresa de viviendas y tiene una columna de clientes que contiene datos tanto de propietarios como de inquilinos. Quiere poder identificar inmediatamente qué entidades son arrendatarias y cuáles son propietarias añadiendo una etiqueta especial a cada registro.
Para hacerlo con WordSmith, puede crear una nueva columna que muestre el estado, ya sea arrendatario o propietario. Puede asociar los registros de inquilinos y propietarios con sus respectivas etiquetas. Ahora, cuando vea sus datos, tendrá una columna adicional que le ayudará a ver rápidamente si la entidad es propietaria o arrendataria.
La función de análisis sintáctico puede utilizarse de cientos de maneras diferentes. Otro caso de uso es cuando se tienen números de teléfono con código de área como prefijo. Se podrían separar los códigos de área de los números de teléfono por motivos de estandarización. Simplemente analice los códigos de área en una columna separada y asigne un valor de reemplazo si lo desea para que la nueva columna simplemente liste el nombre del área en lugar del código de área. Ahora puede eliminar los códigos de área de la columna original. Todo esto se puede hacer dentro de WordSmith mediante unas simples acciones de apuntar y hacer clic y los cambios se aplicarán a sus datos de forma masiva.
Conclusión:
Aunque parezca sencillo, nuestros clientes utilizan WordSmith de miles de formas innovadoras para la normalización de datos en masa. Para las fuentes de datos que pueden contener tipos de datos y problemas similares, también puede guardar las plantillas de WordSmith que cree para utilizarlas en el futuro. Sólo tienes que utilizar la opción «Cargar» después de abrir WordSmith y tu plantilla estará lista para ser utilizada.
Consejo profesional: Al trabajar con millones de registros, muchos usuarios prefieren la interfaz familiar de Microsoft Excel.
Puede importar las bibliotecas de WordSmith a Excel
para hacer los cambios que quieras y luego volver a cargarlas.



