





























Last Updated on avril 8, 2022
Utilisation de Wordsmith pour éliminer le bruit et normaliser les données en vrac afin d’obtenir une plus grande confiance dans la correspondance.
Les données qui affluent dans votre organisation se présentent sous des formes très diverses : capitalisation incohérente, ponctuation, acronymes obscurs, caractères alphanumériques vivant dans des champs où ils ne devraient pas être, etc. Cela est dû au fait que vos données sont réparties dans plusieurs systèmes disparates, chacun ayant un format et des règles de stockage des données légèrement différents. Le problème est aggravé par l’erreur humaine lors de la saisie des données.
Ces petites différences peuvent donner lieu à des malentendus et à des interprétations erronées des données de votre organisation, ce qui amène les personnes qui s’appuient sur ces données à s’en méfier et à mettre en place de multiples contrôles pour s’assurer que les conclusions tirées de ces données sont réellement correctes.
Lorsque vous mettez en correspondance des données provenant de diverses sources, ces incohérences peuvent entraîner des correspondances manquées et des faux positifs, ce qui diminue la confiance dans le processus de mise en correspondance des données et fait que les doublons et les liens ne sont pas déterminés.
Avec DataMatch Enterprise, nous nous efforçons de vous aider à
Tirer le meilleur parti de vos données
en utilisant une variété de transformations de normalisation de données intégrées dans une interface de type pointer-cliquer. Dans ce blog, nous allons approfondir un peu plus et nous concentrer sur la façon dont vous pouvez utiliser notre fonctionnalité WordSmith pour améliorer le processus de correspondance et normaliser vos données en masse.
Qu’est-ce que WordSmith ?
Wordsmith est un outil de signature Data Ladder qui vous permet de profiler, de normaliser et de supprimer le bruit des données de la colonne. De nouvelles colonnes peuvent également être créées automatiquement pour analyser les données transformées des colonnes existantes. Nous examinerons les cas d’utilisation avec des exemples plus loin dans ce blog. L’idée est d’augmenter la confiance et la précision de la correspondance en assurant la cohérence et en minimisant la redondance.
Comment fonctionne WordSmith ?
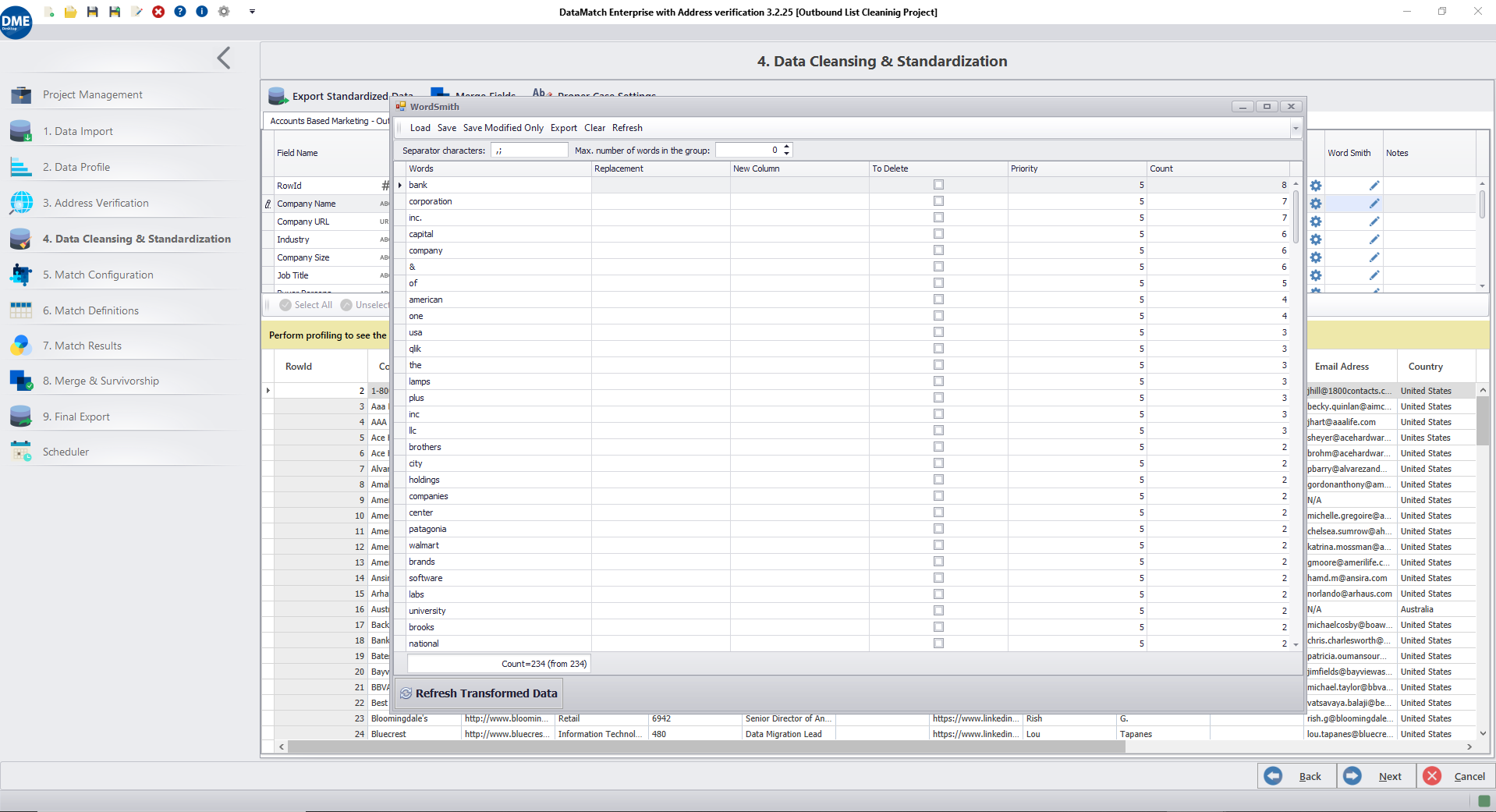
WordSmith se trouve sous le 4ème onglet de DataMatch Enterprise. Cet onglet contient toutes nos transformations de nettoyage de données préétablies. Comme le montre la capture d’écran ci-dessus, vous pouvez utiliser WordSmith pour n’importe quelle colonne de votre choix en cliquant sur l’icône « modifier ». Une deuxième fenêtre s’ouvre alors, comme le montre l’image.
L’outil profile la colonne sélectionnée et affiche les mots par ordre décroissant en fonction de leur nombre. Vous pouvez modifier le nombre maximum de mots regroupés que l’outil doit afficher. Grâce à notre expérience de la mise en correspondance des données de plus de 4 000 clients dans le monde entier, nous savons que, généralement, les mots les plus répétitifs d’une colonne sont les moins standardisés et affectent donc la confiance de la correspondance.
L’outil vous permet de remplacer des mots, de les analyser dans une nouvelle colonne et de les supprimer. Ces fonctions peuvent être utilisées ensemble de diverses manières pour normaliser vos données en masse.
Comment puis-je normaliser les données en utilisant WordSmith ?
Jetons un coup d’œil à quelques-unes des façons les plus courantes dont nos clients utilisent WordSmith.
Suppression des données bruyantes ou redondantes
En science des données, le bruit est une donnée qui n’ajoute aucune signification supplémentaire à vos données et qui fausse généralement l’analyse. Lors de la mise en correspondance de vos données, la présence de bruit entraîne des correspondances manquées et des faux positifs.
Disons que, dans la colonne Nom de la société, vous voyez 3 sociétés différentes :
- ABC Inc.
- Société ABC
- ABC Industries
Maintenant, vous savez que ces trois-là sont la même entité. Mais en utilisant un logiciel de comparaison de données, vous manqueriez ces correspondances. Avec WordSmith, vous pouvez identifier de telles instances en définissant des valeurs max. Nombre de mots dans un groupe à 2 ou 3, puis utilisez l’option Remplacer pour remplacer les 3 phrases que nous avons énumérées ci-dessus par « ABC » ou tout autre format standard que vous préférez pour les noms de société.
La modification sera automatiquement appliquée à chaque instance de vos données, que vous ayez une centaine d’enregistrements ou 10 millions.
Prenons un autre exemple. Disons que vous avez les 3 sociétés distinctes suivantes dans la colonne CompanyName :
- XYZ Incorporated
- 123 Incorporé
- ABC Incorporated
Lors de la mise en correspondance, ces enregistrements peuvent être marqués comme correspondant parce que le mot Incorporé est présent dans les trois. Un faux positif. Avec WordSmith, vous pouvez identifier de telles instances et utiliser l’option de suppression pour les retirer entièrement de cette colonne.
Filtrage ou analyse des données dans une nouvelle colonne
Disons que vous êtes une société de logement et que vous disposez d’une colonne de clients qui contient des données relatives aux propriétaires et aux locataires. Vous voulez être en mesure d’identifier immédiatement les entités qui sont des locataires et celles qui sont des propriétaires en ajoutant une étiquette spéciale à chaque enregistrement.
Pour ce faire, avec WordSmith, vous pouvez créer une nouvelle colonne qui indique le statut, soit locataire, soit propriétaire. Vous pouvez associer les enregistrements des locataires et des propriétaires à leurs étiquettes respectives. Désormais, lorsque vous visualisez vos données, vous disposez d’une colonne supplémentaire qui vous permet de voir rapidement si l’entité est propriétaire ou locataire.
La fonction d’analyse syntaxique peut être utilisée de centaines de façons différentes. Un autre cas d’utilisation est celui des numéros de téléphone dont le préfixe est l’indicatif régional. Vous pourriez séparer les indicatifs régionaux des numéros de téléphone à des fins de normalisation. Il suffit d’analyser les codes régionaux dans une colonne distincte et d’attribuer une valeur de remplacement si vous le souhaitez, de sorte que la nouvelle colonne indique simplement le nom de la région plutôt que le code régional. Vous pouvez maintenant supprimer les indicatifs régionaux de la colonne d’origine. Tout cela peut être fait dans WordSmith par quelques simples actions de type pointer-cliquer et les changements seront appliqués à vos données en masse.
Conclusion
Bien que simple en apparence, WordSmith est utilisé par nos clients de milliers de façons innovantes pour la normalisation des données en vrac. Pour les sources de données qui peuvent contenir des types de données et de questions similaires, vous pouvez également enregistrer les modèles WordSmith que vous créez pour une utilisation ultérieure. Il suffit d’utiliser l’option « Charger » après avoir ouvert WordSmith et votre modèle sera prêt à être utilisé.
Conseil de pro : Lorsqu’ils travaillent avec des millions d’enregistrements, de nombreux utilisateurs préfèrent l’interface familière de Microsoft Excel.
Vous pouvez importer les bibliothèques WordSmith dans Excel
pour effectuer les modifications souhaitées, puis les recharger.



