































Last Updated on January 2, 2026
The data that flows into your organization comes in a variety of formats: inconsistent capitalization, punctuation, obscure acronyms, alpha-numeric characters living in fields they shouldn’t be, and so on. This happens because your data lives in multiple, disparate systems and each has a slightly different format and rules for storing data. The problem is compounded by human error during data entry.
These small differences can result in misunderstanding and misinterpretations of your organization’s data, causing the people who rely on that data to distrust it and put multiple checks in place to make sure that the conclusions made off that data are actually correct.
When you’re matching data across various data sources, these inconsistencies can result in missed matches and false positives, decreasing confidence in the data matching process, which leads to duplicates and linkages not being determined.
With DataMatch Enterprise, we focus on helping you Get the Most Out of Your Data using a variety of built-in data standardization transformations within a point-and-click interface. In this blog, we’ll delve a bit deeper and focus on how you can use our signature WordSmith functionality to further enhance the matching process and standardize your data in bulk.
What is WordSmith?
Wordsmith is a signature Data Ladder tool that allows you to profile, standardize, and remove noise from column data. New columns can also be created automatically to parse out transformed data from existing columns. We will take a look at use-cases with examples further on in this blog. The idea is to increase matching confidence and accuracy by ensuring consistency and minimizing redundancy.
How Does WordSmith Work?
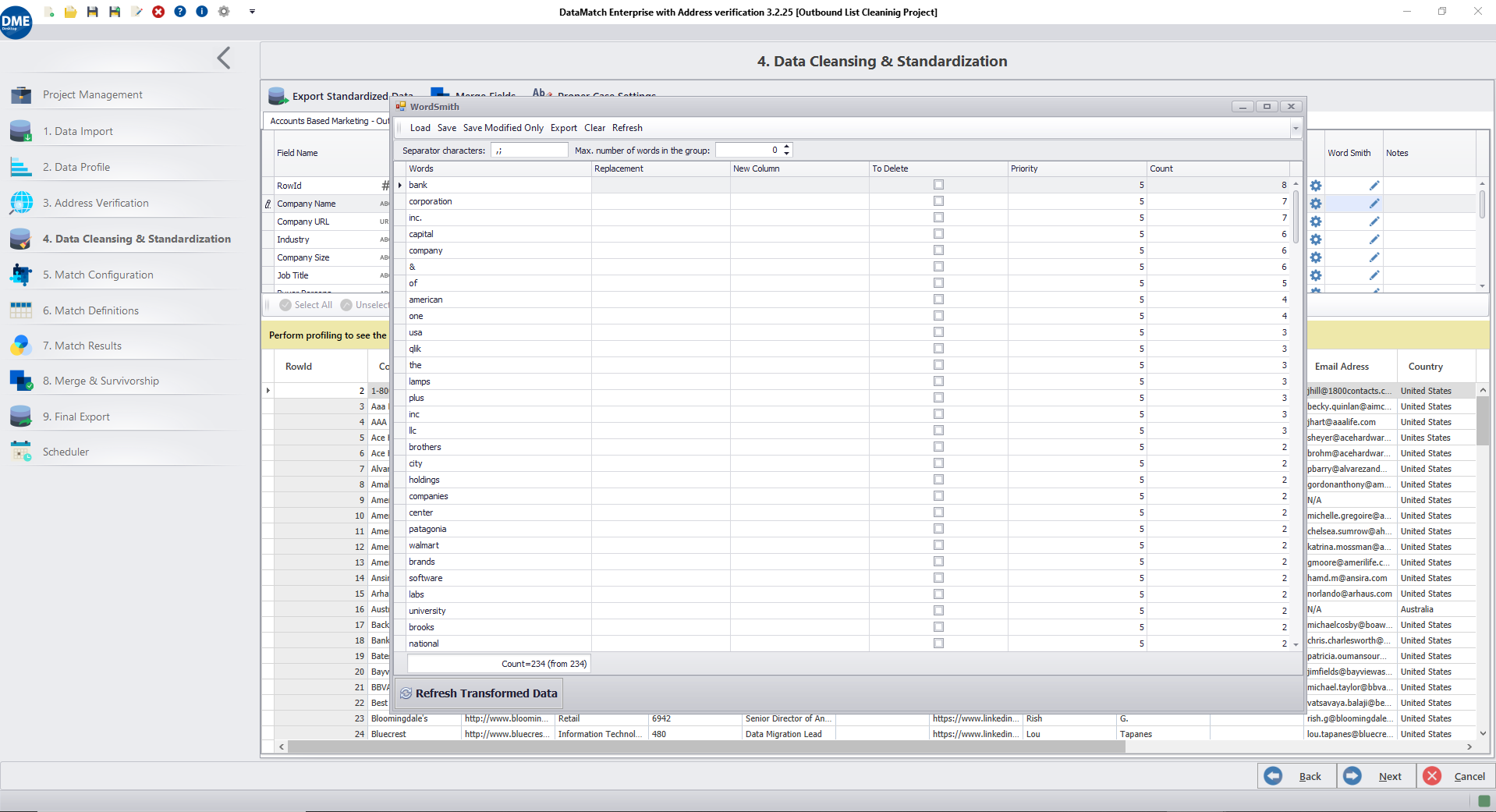
WordSmith can be found under the 4th tab of DataMatch Enterprise. This tab contains all our pre-built data cleansing transformations. As shown in the screenshot above, you can use WordSmith for any column you choose by clicking on the ‘edit’ icon. This will open up a second window, as shown in the image.
The tool profiles the selected column and displays words in descending order based on their count. You can change the maximum number of words grouped together that the tool should display. From our experience matched data across 4,000+ customers all over the world, we know that, generally, the most repetitive words in a column are generally the most unstandardized and therefore affect matching confidence.
The tool allows you to replace words, parse them into a new column, and delete them. These functions can be used together in a variety of ways to standardize your data in bulk.
How Can I Standardize Data Using WordSmith?
Let’s take a look at some of the most common ways our customers use WordSmith.
Removing Noisy or Redundant Data
In data science, noise is data that adds no additional meaning to your data and generally skews analysis. When matching your data, the presence of noise results in missed matched and false positives.
Let’s say that, in the CompanyName column, you see 3 different companies:
- ABC Inc.
- ABC Company
- ABC Industries
Now, you know that all 3 those are the same entity. But when using data matching software, you’d miss those matches. With WordSmith, you can identify such instances by setting max. Number of Words in a Group to 2 or 3 and then using the Replace option to replace the 3 phrases we listed above with ‘ABC’ or whichever standard format you prefer for company names.
The change would automatically be applied to every instance in your data – regardless of whether you have a hundred records or 10 million.
Let’s take a look at one more example. Say you have the following 3 distinct companies in the CompanyName column:
- XYZ Incorporated
- 123 Incorporated
- ABC Incorporated
When matching, these records might get flagged as a match because of the word Incorporated being present across all 3. A false positive. With WordSmith, you can identify such instances and use the delete option to remove it from this column entirely.
Filtering or Parsing Data to a New Column
Let’s say that you’re a housing company and have a customer column that contains data for both owners and renters. You want to be able to immediately identify which entities are renters and which are owners by adding a special tag to each record.
To do that with WordSmith, you can create a new column that shows status, either renter or owner. You can associate renter and owner records with their respective tags. Now when you are viewing your data, you will have an extra column that helps you quickly see whether the entity is an owner or renter.
The parsing feature can be used in hundreds of different ways. Another use-case is when you have phone numbers with area code as the prefix. You could separate area codes from phone numbers for standardization purposes. Simply parse out area codes into a separate column and assign a replacement value if you want so the new column simply lists area name rather than the area code. You can now delete the area codes from the original column. All of this can be done within WordSmith by a few simple point-and-click actions and the changes will be applied to your data in bulk.
Conclusion
While seemingly simple, WordSmith is used by our customers in thousands of innovative ways for bulk data standardization. For data sources that may contain similar types of data and issues, you can also save WordSmith templates that you create for future use. Just use the ‘Load’ option after opening WordSmith and your template will be ready for use.
Pro tip: When working with millions of records, many users prefer the familiar interface of Microsoft Excel. You can import WordSmith libraries into Excel to make the changes you want and then load them back up.

