





























Last Updated on April 13, 2022
Die Verknüpfung von Datensätzen ist oft eine notwendige Komponente für die effektive Durchführung verschiedener Bildungsinitiativen. Ob es sich um die Messung der Leistungen von Schülern und Lehrern über einen längeren Zeitraum und über mehrere Schulen hinweg handelt oder um die Bewertung der Wirksamkeit von Bildungsprogrammen auf staatlicher Ebene.
Es gibt jedoch einige Probleme in der Branche, die die Datenintegrität beeinträchtigen. Da sich Bildungseinrichtungen auf landesweite Längsschnitt-Systeme (SLDS) verlassen müssen, um den Umfang der Daten zu verstehen, kann das Vorhandensein von doppelten, fehlenden und anderen fehlerhaften Daten zu ungenauen Schlussfolgerungen führen und politische Maßnahmen behindern.
Eine Lösung für diese Probleme ist eine hochpräzise Software zur Verknüpfung von Datensätzen. In diesem Beitrag befassen wir uns mit den Herausforderungen und Grenzen der Datengenauigkeit im Bildungssektor und zeigen auf, wie sich die Datengenauigkeit und -qualität verbessern lässt.
Was ist SLDS und warum ist es wichtig für den Bildungssektor?
Bei SLDS-Systemen handelt es sich um Datenbanken, die Schülerdaten aus verschiedenen Datensystemen zusammenfassen und Schlüsseldaten von der Vorschule bis zur High School, dem College und dem Arbeitsmarkt verfolgen. Das zugrunde liegende Ziel ist es, Lehrern, Verwaltungsangestellten, staatlichen Bildungsabteilungen usw. dabei zu helfen, bildungsbezogene politische Entscheidungen zu treffen, indem sie Schülerdaten analysieren, die über mehrere Jahre, Programme und Schulen hinweg gesammelt wurden.
Die Bedeutung von SLDS-Systemen entstand, als es schwierig wurde, einen umfassenden Überblick über die Schülerdaten im gesamten Bundesstaat zu erhalten, da die Bildungsdaten in unterschiedlichen, isolierten Datensätzen in verschiedenen Behörden gespeichert waren. Derzeit sind die Staaten auf Bundesebene verpflichtet, SLDS-Systeme für alle Beteiligten zu entwickeln und zu verbreiten, um das gesamte Bildungssystem zu analysieren, zu verfeinern und zu verbessern.
Mit einem SLDS-System können die verschiedenen Interessengruppen verschiedene Fragen beantworten, Trends erkennen und Entscheidungen auf vielfältige Weise bewerten. Dazu gehören:
- Lehrer und Bildungsverwalter: Sie möchten möglicherweise die Wirksamkeit von frühkindlichen, K12- und anderen Bildungsprogrammen bewerten; Merkmale von leistungsstarken Schülern im Vergleich zu leistungsschwachen Schülern, die Verweildauer von Schülern an Colleges und Hochschulen, usw.
- Politische Entscheidungsträger und staatliche Gesetzgeber: Die Beaufsichtigung, Bewertung und Reformierung von Bildungsprogrammen, um sich für Zuschüsse zu qualifizieren, wird ein zentrales Anliegen von Bildungspolitikern und Gesetzgebern sein. Angesichts der im Rahmen des CARES-Gesetzes gewährten Zuschüsse in Höhe von 13 Milliarden Dollar könnten Forscher und politische Entscheidungsträger beispielsweise die Auswirkungen von Online-Lernprogrammen auf die Leistungen der Schüler im Vergleich zum Unterricht im Klassenzimmer bewerten wollen, um den Erfolg ähnlicher Programme in Notsituationen zu ermitteln.
- Staatliche Bildungsagenturen und -abteilungen: Staatliche Abteilungen müssen sich auf Längsschnittdaten stützen, um Rückschlüsse auf die Merkmale zu ziehen, die sich auf den Durchlauf durch das Bildungssystem innerhalb eines Staates auswirken, und um technische Bildungs- und Berufsergebnisse sowie die Auswirkungen auf Beschäftigung und Arbeitslosigkeit zu untersuchen.
Herausforderungen bei Bildungsdaten
1. SLDS-Systeme enthalten siloartige Daten
SLDS-Systeme können mehrere Datenstränge enthalten, die jedoch nicht kohärent genug sind, um ein wahrheitsgetreues Bild der Leistungen eines Schülers über mehrere Bildungsprogramme hinweg und über einen längeren Zeitraum hinweg zu vermitteln. Kurz gesagt, sie sind nicht für die Integration oder Berichterstattung, sondern hauptsächlich für die Speicherung gedacht.
2. Mangel an einheitlicher Berichterstattung
Bildungsdaten (Testergebnisse der Schüler, Fehltage, Einschreibedaten) werden in der Regel als Reaktion auf die spezifischen Anforderungen eines einzelnen Studiengangs erhoben. So können beispielsweise in den Datenbanken des Nationalen Berichtssystems (NRS) umfangreiche Daten zur Erwachsenenbildung vorhanden sein. Allerdings wird es für die Forscher schwierig sein, Schlussfolgerungen über die Ergebnisse der Erwachsenenbildung aufgrund der frühkindlichen Bildungsprogramme zu ziehen.
3. Grenzen der behördenübergreifenden Datenverknüpfung
Persönlich identifizierbare Informationen (PII) wie Sozialversicherungsnummer, Bankkontonummer, Kfz-Kennzeichen, Reisepassnummer usw. sind entscheidend für die Identifizierung eindeutiger und genauer Kontaktdatensätze.
Viele staatliche Bildungsbehörden (SEA) und lokale Bildungsbehörden (LEA) zögern jedoch, wichtige Schülerdaten an Dritte weiterzugeben, da sie Gefahr laufen, gegen den Family Education Rights and Privacy Act (FERPA) zu verstoßen.
Daher können alle behördenübergreifenden Datenverknüpfungsinitiativen zur Schaffung von SLDS-Datenbanken Probleme bei der Suche nach eindeutigen IDs für die Verfolgung von Schülern von der Vorschule bis zum Berufsleben und über mehrere Staaten hinweg bereiten.
Verbesserung der Datensatzverknüpfung für Goldene Datensätze
Deterministischer Abgleich vs. Probabilistischer Abgleich
DieDatensatzverknüpfung oder Entitätsauflösung bezieht sich auf den Prozess der Identifizierung und des Vergleichs von zwei oder mehr ähnlichen Datensätzen, um sicherzustellen, dass sie sich auf dieselbe Entität beziehen oder nicht. In der Regel wird eine Übereinstimmung festgestellt, wenn die verglichenen Datensätze standardisiert sind und eindeutige Identifikatoren vorhanden oder konsistent sind. In diesem Fall ist der deterministische Abgleich oder der exakte Abgleich ideal.
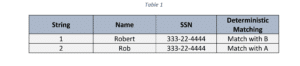
Was aber, wenn es keine eindeutige Kennung gibt oder wenn die Datenformate inkonsistent sind und variieren? An dieser Stelle sollte der probabilistische Abgleich eingesetzt werden. Dabei wird ausgewertet, inwieweit zwei oder mehr ähnliche Datensätze entweder zwischen 0 oder 1 liegen, um eine Übereinstimmung zu ermitteln. In diesem Fall müssen keine eindeutigen Identifikatoren vorhanden sein, um eine Übereinstimmung für die Datensatzverknüpfung zu klassifizieren.
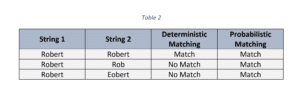
Warum der probabilistische Abgleich für die Verbesserung von SLDS-Daten von entscheidender Bedeutung ist
- Die Ungleichheit der Felder kann zu Problemen bei der Suche nach eindeutigen Schülerdatensätzen führen: Bei der Zusammenführung unterschiedlicher SLDS-Datenbanken ist es nicht ungewöhnlich, dass Name, Adresse und andere Felder in zwei oder mehr Formaten vorhanden sind. So kann beispielsweise ein Datensatz Namensdaten als „Vollständiger Name“ speichern, während ein anderer „Vorname“ und „Nachname“ enthalten kann.
- Mangel an eindeutigen Identifikatoren: Da personenbezogene Daten nach der Konsolidierung von Schülerdaten aus verschiedenen Datenbanken leicht verlegt werden oder verloren gehen können, kann die Verknüpfung von Datensätzen durch deterministischen oder exakten Abgleich zu verfehlten Ergebnissen und einer höheren Anzahl falsch positiver Ergebnisse führen. Der probabilistische Abgleich hingegen ist in der Lage, Übereinstimmungen zu klassifizieren, wenn zwei vergleichbare Datensätze nicht exakt sind und kein gemeinsamer Identifikator vorhanden ist.

Wie aus Tabelle 3 hervorgeht, kann der probabilistische Abgleich eine Übereinstimmung mit einem ähnlichen Datensatz auch ohne eine eindeutige Kennung (in diesem Fall die SSN) feststellen.
Wege zur Verbesserung der Datengenauigkeit
Eine effektive Datensatzverknüpfung geht Hand in Hand mit sauberen und konsistenten Daten. Je besser die Qualität der SLDS-Daten ist, d. h. je weniger ungültige Werte, falsch formatierte Einträge und Fehler in der Groß- und Kleinschreibung vorhanden sind, desto einfacher wird es für die Endnutzer, Übereinstimmungen zu finden und goldene Einträge über mehrere Behörden hinweg zu ermitteln.
Hier sind einige Möglichkeiten, wie dies erreicht werden kann.
1. Identifizieren Sie alle Datenquellen
Das Wichtigste zuerst: Bestimmen Sie alle Dateneingabepunkte für Ihr Projekt. Vieles davon wird von Ihren Datenzielen und -ergebnissen abhängen.
Die Durchführung groß angelegter K12- oder P-20W-SLDS-Initiativen erfordert häufig die Konsolidierung unterschiedlicher SLDS-Systeme, um die Datenintegrität der bestehenden Dateninfrastrukturen zu verbessern.
Ein Beispiel hierfür ist das staatlich finanzierte Projekt des Bildungsministeriums von Georgia (GDOE) zur Verbesserung der SLDS-Daten durch die Integration von Daten aus den folgenden Bereichen:
- Die Abteilung für Jugendstrafrecht
- Abteilung für Familien- und Kinderbetreuung
- Jugendgericht und
- PeachNet (Georgias Bildungsnetzwerk)
Es ist auch wichtig, die Vielfalt der Datenquellen für die Aufnahme zu erkennen. Während Bezirke und staatliche Bildungsministerien über aggregierte Daten in relationalen Datenbanken verfügen, können Schulen und Colleges Testergebnisse und Leistungen leichter in Excel-Dateien oder Webanwendungen aktualisieren. Sobald alle Datenquellen für die Aufnahme identifiziert sind, kann eine klare Strategie für das gesamte Daten-Ökosystem und die Ziele erreicht werden.
2. Führen Sie ein gründliches Datenprofil durch
Die Erstellung eines aussagekräftigen Gesundheitschecks der Daten vor einer Datenvorbereitung oder -bereinigung kann die Datenqualität erheblich verbessern. Die Erstellung von Datenprofilen kann dazu beitragen, wichtige Statistiken über Datenquellen aufzudecken – vom Prozentsatz fehlender Daten und der Art der Feldmuster bis hin zum Ausmaß der Formatierungs- und Rechtschreibfehler. Dies kann dazu beitragen, Standardprotokolle für die Datenqualität zu erstellen und die Genauigkeit der Datensatzverknüpfung zu verbessern.
Ein gutes Beispiel hierfür ist Minnesota, wo die staatlichen Behörden zusammenarbeiteten, um ihr SLDS-System mit dem Early Childhood Longitudinal Data System (ECLDS) zu kombinieren, wobei beide IT-Infrastrukturen von den Minnesota IT Services (MNIT) verwaltet werden. Das MNIT führte eine eingehende Datenprofilierung durch, um die Dateinamen und -beschreibungen sowie die erwarteten Datenformate zu ermitteln. Im Anschluss an die Maßnahme konnte MNIT die Konventionen für die Benennung der Dateien festlegen, um eine einheitliche Berichterstattung zu gewährleisten, und die Datenelemente bestimmen, auf die man sich konzentrieren muss, um einen genauen Abgleich vorzunehmen.
3. Bereinigung von Fehlern und Standardisierung von Datenformaten
Außerdem ist es wichtig, eine Datenbereinigung durchzuführen, um Datenfehler und Inkonsistenzen zu beseitigen, die die Abgleichsgenauigkeit beeinträchtigen und sich auf den allgemeinen Zustand von SLDS und anderen Schülerdaten auswirken können. Während der Datenbereinigungsphase sollten alle zu erwartenden Datenänderungen mit den Anforderungen aller Beteiligten – von Lehrern und Verwaltungsangestellten bis hin zu Forschern und bildungspolitischen Entscheidungsträgern – in Einklang gebracht werden.
Während der Datenbereinigung können die Endnutzer eine Reihe von Aufgaben durchführen, wie z. B.:
- Korrektur von Rechtschreib-, Interpunktions-, Groß- und Formatierungsfehlern
- Entfernen oder Ersetzen von Sonderzeichen, Zeichen mit Zahlen, Zeichen mit Buchstaben für entsprechende Felder
- Korrektur von Datenmustern, indem sichergestellt wird, dass sie mit etablierten Mustern wie RegEX übereinstimmen
- Eigene, proprietäre Feldmuster erstellen
- Standardisierung der Felder für Name, Adresse, Telefonnummer und Postleitzahl zur Vermeidung von Problemen bei der Identitätsauflösung und mehr
Nach der Beseitigung aller bekannten Fehler werden die Daten dann für den Abgleich zwischen verschiedenen Datensätzen vorbereitet.
4. Identifizieren Sie doppelte und redundante Datensätze
Das Auffinden und Entfernen redundanter und doppelter Daten beginnt mit der Erstellung von Abgleichsregeln und Konfigurationen, die für einzelne Felder am besten geeignet sind. Bei der Verknüpfung zwischen den Behörden ist es möglich, dass Schüler aus dem SLDS für die frühkindliche Bildung eine andere ID-Nummer haben als in den K12- und Arbeitsmarktdaten.
Bei einem deterministischen Abgleich ist dies problematisch, da das Vorhandensein unterschiedlicher oder fehlender Tracking-IDs und anderer personenbezogener Daten einen Abgleich verhindern kann. Mit Fuzzy- und phonetischem Matching kann die Wahrscheinlichkeit von Übereinstimmungen jedoch deutlich erhöht werden; die daraus resultierenden Duplikate und redundanten Daten können je nach Unternehmenszielen aussortiert oder angereichert werden.
Wie DataMatch Enterprise von Data Ladder bei Bildungsdaten helfen kann
Ein Datensatzverknüpfungstool wie DataMatch Enterprise verfügt über eine Vielzahl von Funktionen und Lösungen, die sich am besten für die Lösung großer SLDS- und anderer Bildungsdatenprojekte mit einer Übereinstimmungsrate von über 90 % eignen.
Eine vom BOR Office of Policy durchgeführte unabhängige Studie ergab, dass der probabilistische Abgleichsalgorithmus von Data Ladder einen firmeneigenen Algorithmus übertraf. In der Studie wurden die Schülerdaten des Bildungsministeriums des Bundesstaates Connecticut (SDE) mit den Daten des National Student Clearinghouse (NSC) abgeglichen, um die Zahl der Highschool-Absolventen zu ermitteln, die sich an einer postsekundären Einrichtung eingeschrieben haben.
Die hauseigene Lösung ergab 15.570 Treffer, während die Lösung von Data Ladder 16.600 Treffer lieferte – 1.030 Treffer mehr.
Die hohe Abgleichsgenauigkeit von DataMatch Enterprise lässt sich auf proprietäre und bewährte Abgleichsalgorithmen und verschiedene Funktionen zurückführen, die eine hohe Abgleichsgenauigkeit ermöglichen. Diese sind:
- Excel-Dateien, SQL und Hadoop-basierte Repository-Konnektivität zur Verarbeitung von mehr als 2 Milliarden Datensätzen
- Integrierte RegEx-Muster zur automatischen Erkennung und Profilierung von Rechtschreib-, Zeichensetzungs- und anderen Datenfehlern
- Eine Reihe von Umwandlungen zur Bereinigung und Standardisierung von Namen, Adressen und anderen Feldern
- Exakte, proprietäre phonetische und etablierte Fuzzy-Matching-Algorithmen, einschließlich Jaro-Wrinkler, um Übereinstimmungen zu finden und mehr.
Um eine LEA-Erfolgsgeschichte von DataMatch Enterprise zu lesen, klicken Sie hier.
Schlussfolgerung
Im Bildungssektor gibt es Probleme mit der Datenqualität, z. B. das Fehlen gemeinsamer Identifikatoren und Datensilos, die die Verknüpfung von Daten und die Genauigkeit der Ergebnisse in staatlich finanzierten SLDS-Projekten behindern können. Während ein exakter Abgleich in bestimmten Kontexten nützlich sein kann, ist eine Software zur Datensatzverknüpfung mit probabilistischem Abgleich weitaus effektiver bei der Ermittlung von Übereinstimmungen in unterschiedlichen Datensätzen.
Weitere Informationen darüber, wie DataMatch Enterprise für Ihre K12-, P-20W- oder eine andere SLDS-Dateninitiative eingesetzt werden kann, finden Sie in unseren
Lösungen für die Bildungsindustrie
oder
kontaktieren Sie uns
um mit unserem Vertriebsteam in Kontakt zu treten.



