































Last Updated on January 6, 2026
Record linkage is often a necessary component to effectively execute different educational initiatives. Whether it is measuring the performance of students and teachers overtime and across multiple schools to evaluating the effectiveness of state-level education programs.
However, certain industry challenges exist that undermine data integrity. As educational bodies must rely on statewide longitudinal systems (SLDS) to understand the scope of data, the presence of duplicate, missing, and other erroneous data can lead to inaccurate conclusions and impede policy measures.
One solution to address these problems is with a high-precision record linkage software. In this post, we will look at the challenges and limitations of data accuracy in the education sector and shed some light on how to improve data accuracy and quality.
What Is SLDS And Why It Is Important for The Education Sector?
SLDS systems are databases that aggregate student data collected from multiple data systems and track key data from preschool to high school, college, and workforce. The underlying objective is to help teachers, administrators, state education departments, etc. make education-related policy assessments by analyzing student data collected over multiple years, programs, and schools.
The importance of SLDS systems arose when educational data stored in disparate, siloed datasets across different agencies posed challenges in getting a comprehensive view of student data across the state. Currently, states are mandated at the federal level to build and disseminate SLDS systems for all stakeholders to analyze, refine, and improve the entire education ecosystem.
Using an SLDS system, different stakeholders can answer various questions spot trends and evaluate decisions in numerous ways. These include:
- Teachers and educational administrators: they may want to evaluate the effectiveness of early childhood, K12 and other educational programs; characteristics of high-performing students vs. low-performing students, length of time students stay enrolled at college and higher education, etc.
- Policy makers and state legislators: overseeing, gauging and reforming education programs to qualify for grants will be a key concern for education policy makers and legislators. For example, in light of the $13 billion grant issued under the CARES Act, researchers and policy makers may want to assess the impact of online learning tools on student performance relative to classroom education to ascertain the success of similar programs in emergency situations.
- State education agencies and departments: state departments must rely on longitudinal data to make inferences on the characteristics that impact progression through the education system within a state, research technical education and career outcomes, as well as impact on job and unemployment.
Challenges in Educational Data
1. SLDS Systems Contain Siloed Data
SLDS systems can contain multiple strands of data but not be cohesive enough to present a true account of a student’s performance across multiple education programs and overtime. In short, they are not designed for integration or reporting, but mostly for storage purposes.
2. Lack of Uniform Reporting
Education data (student test scores, days of absence, enrolment dates) are usually collected as a response to an individual program’s specific requirements. For instance, there may be ample data available for adult education in National Reporting System (NRS) databases. However, researchers will face difficulty in drawing conclusions about adult education performance outcomes because of early childhood education programs.
3. Limits of Interagency Data Linking
Personally Identifiable Information (PII) such as Social Security number, bank account number, vehicle license number, passport number, etc. are crucial for identifying unique and accurate contact records.
However, many state education agencies (SEA) and local education agencies (LEA) can be reluctant to share vital student data to third parties for risk of breaching the Family Education Rights and Privacy Act (FERPA).
As a result, any interagency data linking initiatives for creating SLDS data warehouses can present problems in locating unique IDs for tracking students from pre-school to workforce and across multiple states.
Improving Record Linkage for Golden Records
Deterministic Matching vs. Probabilistic Matching
Record linkage or entity resolution refers to the process of identifying and comparing two or more similar records to ensure if they refer to the same entity or not. Usually, a match is identified when the compared datasets are standardized, and unique identifiers are present or consistent. In this case, deterministic matching, or exact matching is ideal.
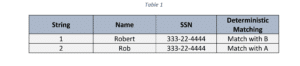
But what if no unique identifier exists or when data formats are inconsistent and vary? This is where probabilistic matching should be used. It works by evaluating the extent to which two or more similar records lie either between 0 or 1 to identify a match. In this case, unique identifiers don’t have to be present to classify a match for record linkage.
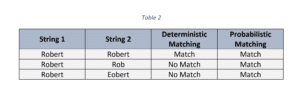
Why Probabilistic Matching is Critical for Improving SLDS Data
- The disparity in the fields can create issues in finding unique student records: In the case of merging disparate SLDS databases, it is not uncommon to find name, address, and other fields existing in two or more formats. For example, one dataset can store name data as “Full Name” whereas another can have ‘First Name’ and ‘Last Name’.
- Lack of unique identifiers: As PII data can get easily misplaced or lost after consolidating student data from different databases, linking records through deterministic or exact matching can lead to missed results and higher false positives. Probabilistic matching, on the other hand, has the capacity to classify matches when two comparable records are non-exact and in the absence of a common identifier.

As seen from Table 3, probabilistic matching can identify a match with a similar record even without the presence of a unique identifier (in this case – SSN).
Ways to Improve Data Accuracy
Effective record linkage goes hand in hand with clean and consistent data. The better the SLDS data quality – lack of null values, incorrectly formatted entries, and casing and spelling errors – the easier it will be for end users to find matches and determine golden records across multiple agencies.
Here are a few ways how this can be done.
1. Identify All Data Sources
First things first; identify all data ingestion points for your project. Much of this will depend on your data goals and outcomes.
Carrying out large-scale K12 or P-20W SLDS initiatives often requires consolidating disparate SLDS systems to enhance the data integrity of existing data infrastructures.
An example of this is Georgia Department of Education (GDOE)’s state-funded project of enhancing SLDS data by integrating data from the following:
- The Department of Juvenile Justice
- Department of Family Child Services
- Juvenile Court and
- PeachNet (Georgia’s education network)
It is also important to recognize the variety of data sources for ingestion; while districts and state departments of education may have aggregated data in relational databases, schools and colleges may have test scores and performance updated more readily in Excel files or web applications. Once all data sources are identified for ingestion, a clear strategy for the entire data ecosystem and targets can be reached.
2. Carry Out a Thorough Data Profile
Building a cogent health check-up of data prior to any data prep or cleansing can garner significant improvements in data quality. Data profiling can help reveal important statistics about data sources; – from the percentage of missing data and type of field patterns to extent of formatting and spelling errors. This can help establish standard data quality protocols and enhance record linkage accuracy.
A good example of this was in Minnesota in which state agencies collaborated to combine its SLDS system with the Early Childhood Longitudinal Data System (ECLDS), both IT infrastructures managed by the Minnesota IT Services (MNIT). The MNIT conducted an in-depth data profiling to reveal data file names and descriptions and the expected formats of data. Following the activity, MNIT was able to determine file naming conventions for reporting consistency and which data elements to focus on for matching accuracy.
3. Clean Errors and Standardize Data Formats
It is also vital to perform data scrubbing to clean and remove data errors and inconsistencies that can affect matching accuracy and affect the overall health of SLDS and other student data. During the data cleaning phase, all expected data changes should be in line with requirements of all stakeholders – from schoolteachers and administrators to researchers and education policy makers.
During data cleaning, end-users can carry out a variety of tasks such as:
- Fix spelling, punctuation, casing, and formatting errors
- Remove or replace special characters, characters with numbers, characters with letters for appropriate fields
- Correct data patterns by ensuring it conforms to established patterns such as RegEX
- Create own, proprietary field patterns
- Standardize name, address, phone number, ZIP code fields to avoid identity resolution challenges and more
After removing all known errors, the data is then prepared for matching across different datasets.
4. Identify Duplicate and Redundant Records
Finding and removing redundant and duplicate data starts with creating matching rules and configurations best suited for individual fields. During interagency linking, it is possible for students from early childhood education SLDS to have a separate ID tracking number from that found in K12 and workforce data.
Under deterministic matching, this will be problematic as the presence of varying or missing tracking IDs and other PII can inhibit matches. With fuzzy and phonetic matching, however, the likelihood of matches can rise significantly; the resulting duplicates and redundant data can be discarded or enriched depending on organizational goals.
How Data Ladder’s DataMatch Enterprise Can Help with Education Data
A record linkage tool like DataMatch Enterprise has the breadth of features and solutions best-suited to resolving large-scale SLDS and other education data projects with 90%+ match rate.
An independent study conducted by BOR Office of Policy found that Data Ladder’s probabilistic matching algorithm outperformed an in-house proprietary algorithm. In the study, the Connecticut State Department of Education (SDE)’s student data file was matched against the National Student Clearinghouse (NSC) to determine number of high school graduates who enrolled in postsecondary institution.
The in-house solution garnered 15,570 matches while Data Ladder’s solution yielded 16,600 matches – an additional 1,030 matches.
DataMatch Enterprise’s high matching accuracy can be attributed to proprietary and established matching algorithms and various features that help identify high-precision matching accuracy. These are:
- Excel files, SQL and Hadoop-based repository connectivity to process 2 billion + records
- Built-in RegEx patterns to auto-detect and profile spelling, punctuation, and other data errors
- Array of transformations to cleanse and standardize name, address and more fields
- Exact, proprietary phonetic, and established fuzzy matching algorithms including Jaro-Wrinkler to find match results and more.
Conclusion
The education sector is marred by data quality challenges such as lack of common identifiers and siloes data that can hinder data linking and accuracy outcomes in state funded SLDS projects. While exact matching may be useful in certain contexts, a record linkage software with probabilistic matching can be far more effective in identifying matches across disparate datasets.
For further information on how DataMatch Enterprise can work for your K12, P-20W or any other SLDS data initiative, please view our education industry solutions or contact us to get in touch with our sales team.

