




























Last Updated on marzo 4, 2022
La vinculación de los registros suele ser un componente necesario para ejecutar eficazmente las diferentes iniciativas educativas. Tanto si se trata de medir el rendimiento de los estudiantes y los profesores a lo largo de las horas y en varios centros educativos como de evaluar la eficacia de los programas educativos a nivel estatal.
Sin embargo, existen ciertos retos en la industria que socavan la integridad de los datos. Dado que los organismos educativos deben basarse en los sistemas longitudinales estatales (SLDS) para comprender el alcance de los datos, la presencia de datos duplicados, faltantes y otros datos erróneos puede llevar a conclusiones inexactas y obstaculizar las medidas políticas.
Una solución para abordar estos problemas es un software de vinculación de registros de alta precisión. En este artículo, analizaremos los retos y las limitaciones de la precisión de los datos en el sector educativo y arrojaremos algo de luz sobre cómo mejorar la precisión y la calidad de los datos.
¿Qué es el SLDS y por qué es importante para el sector educativo?
Los sistemas SLDS son bases de datos que agregan los datos de los estudiantes recogidos de múltiples sistemas de datos y hacen un seguimiento de los datos clave desde la educación preescolar hasta la escuela secundaria, la universidad y la fuerza de trabajo. El objetivo subyacente es ayudar a los profesores, administradores, departamentos estatales de educación, etc. a realizar evaluaciones de políticas relacionadas con la educación mediante el análisis de los datos de los estudiantes recogidos a lo largo de múltiples años, programas y escuelas.
La importancia de los sistemas SLDS surgió cuando los datos educativos almacenados en conjuntos de datos dispares y aislados en diferentes organismos plantearon problemas para obtener una visión global de los datos de los estudiantes en todo el estado. Actualmente, los estados tienen el mandato a nivel federal de construir y difundir sistemas SLDS para que todas las partes interesadas puedan analizar, perfeccionar y mejorar todo el ecosistema educativo.
Gracias a un sistema SLDS, las distintas partes interesadas pueden responder a diversas preguntas, detectar tendencias y evaluar decisiones de numerosas maneras. Entre ellas se encuentran:
- Profesores y administradores educativos: pueden querer evaluar la eficacia de los programas de educación infantil, K12 y otros programas educativos; las características de los estudiantes de alto rendimiento frente a los de bajo rendimiento, el tiempo que los estudiantes permanecen matriculados en la universidad y la educación superior, etc.
- Responsables políticos y legisladores estatales: supervisar, calibrar y reformar los programas educativos para que puedan recibir subvenciones será una preocupación fundamental para los responsables políticos y los legisladores en materia de educación. Por ejemplo, a la luz de la subvención de 13.000 millones de dólares concedida en el marco de la Ley CARES, los investigadores y los responsables políticos pueden querer evaluar el impacto de las herramientas de aprendizaje en línea en el rendimiento de los estudiantes en relación con la educación en el aula para determinar el éxito de programas similares en situaciones de emergencia.
- Agencias y departamentos estatales de educación: los departamentos estatales deben basarse en datos longitudinales para hacer inferencias sobre las características que influyen en la progresión a través del sistema educativo dentro de un estado, investigar la educación técnica y los resultados de la carrera, así como el impacto en el trabajo y el desempleo.
Desafíos en los datos educativos
1. Los sistemas SLDS contienen datos en silo
Los sistemas SLDS pueden contener múltiples hilos de datos pero no ser lo suficientemente cohesivos como para presentar una cuenta verdadera del rendimiento de un estudiante a través de múltiples programas educativos y en tiempo extra. En resumen, no están diseñados para la integración o la elaboración de informes, sino sobre todo para el almacenamiento.
2. Falta de uniformidad en los informes
Los datos sobre educación (resultados de los exámenes de los alumnos, días de ausencia, fechas de matriculación) suelen recogerse como respuesta a los requisitos específicos de un programa concreto. Por ejemplo, puede haber muchos datos disponibles para la educación de adultos en las bases de datos del Sistema Nacional de Información (NRS). Sin embargo, los investigadores tendrán dificultades para sacar conclusiones sobre los resultados de la educación de adultos debido a los programas de educación infantil.
3. Límites de la vinculación de datos entre organismos
La información de identificación personal (IPI), como el número de la Seguridad Social, el número de la cuenta bancaria, el número de la licencia del vehículo, el número del pasaporte, etc., es crucial para identificar registros de contacto únicos y precisos.
Sin embargo, muchas agencias educativas estatales (SEA) y locales (LEA) pueden ser reacias a compartir datos vitales de los estudiantes con terceros por el riesgo de infringir la Ley de Derechos Educativos y Privacidad de la Familia (FERPA).
Como resultado, cualquier iniciativa de vinculación de datos entre organismos para crear almacenes de datos SLDS puede presentar problemas para localizar identificaciones únicas para el seguimiento de los estudiantes desde la etapa preescolar hasta la laboral y en varios estados.
Mejora de la vinculación de los registros para los registros dorados
Emparejamiento determinista frente a emparejamiento probabilístico
Lavinculación de registros o la resolución de entidades se refiere al proceso de identificar y comparar dos o más registros similares para asegurar si se refieren a la misma entidad o no. Normalmente, se identifica una coincidencia cuando los conjuntos de datos comparados están normalizados y los identificadores únicos están presentes o son coherentes. En este caso, lo ideal es la concordancia determinista o exacta.
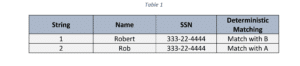
¿Pero qué pasa si no existe un identificador único o cuando los formatos de los datos son incoherentes y varían? Aquí es donde se debe utilizar la concordancia probabilística. Funciona evaluando la medida en que dos o más registros similares se encuentran entre 0 o 1 para identificar una coincidencia. En este caso, los identificadores únicos no tienen que estar presentes para clasificar una coincidencia para la vinculación de registros.
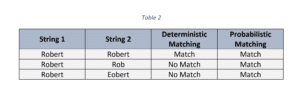
Por qué la concordancia probabilística es fundamental para mejorar los datos del SLDS
- La disparidad de los campos puede crear problemas a la hora de encontrar registros únicos de estudiantes: En el caso de la fusión de bases de datos SLDS dispares, no es raro encontrar nombres, direcciones y otros campos que existen en dos o más formatos. Por ejemplo, un conjunto de datos puede almacenar los datos del nombre como «Nombre completo» mientras que otro puede tener «Nombre» y «Apellido».
- Falta de identificadores únicos: Dado que los datos PII pueden extraviarse o perderse fácilmente tras consolidar los datos de los estudiantes de diferentes bases de datos, la vinculación de los registros a través de una coincidencia determinista o exacta puede llevar a resultados perdidos y a un mayor número de falsos positivos. El cotejo probabilístico, en cambio, tiene la capacidad de clasificar las coincidencias cuando dos registros comparables no son exactos y en ausencia de un identificador común.

Como se observa en la Tabla 3, la concordancia probabilística puede identificar una coincidencia con un registro similar incluso sin la presencia de un identificador único (en este caso – SSN).
Formas de mejorar la precisión de los datos
La vinculación eficaz de los registros va acompañada de datos limpios y coherentes. Cuanto mejor sea la calidad de los datos del SLDS (ausencia de valores nulos, entradas con formato incorrecto y errores de redacción y ortografía), más fácil será para los usuarios finales encontrar coincidencias y determinar los registros dorados en varios organismos.
He aquí algunas formas de hacerlo.
1. Identificar todas las fuentes de datos
Lo primero es identificar todos los puntos de entrada de datos de su proyecto. Gran parte de esto dependerá de los objetivos y resultados de sus datos.
Llevar a cabo iniciativas de SLDS a gran escala de K12 o P-20W a menudo requiere consolidar sistemas SLDS dispares para mejorar la integridad de los datos de las infraestructuras de datos existentes.
Un ejemplo de ello es el proyecto del Departamento de Educación de Georgia (GDOE), financiado por el Estado, de mejorar los datos del SLDS integrando los datos de
- El Departamento de Justicia Juvenil
- Departamento de Servicios Familiares para la Infancia
- Tribunal de Menores y
- PeachNet (red educativa de Georgia)
También es importante reconocer la variedad de fuentes de datos para la ingestión; mientras que los distritos y los departamentos estatales de educación pueden tener datos agregados en bases de datos relacionales, las escuelas y los colegios pueden tener las puntuaciones de los exámenes y el rendimiento actualizados más fácilmente en archivos de Excel o aplicaciones web. Una vez identificadas todas las fuentes de datos para la ingesta, se puede alcanzar una estrategia clara para todo el ecosistema de datos y los objetivos.
2. Realizar un perfil de datos exhaustivo
La creación de un chequeo de salud convincente de los datos antes de cualquier preparación o limpieza de los mismos puede conseguir mejoras significativas en la calidad de los datos. La elaboración de perfiles de datos puede ayudar a revelar estadísticas importantes sobre las fuentes de datos, desde el porcentaje de datos que faltan y el tipo de patrones de campo hasta el alcance de los errores de formato y ortografía. Esto puede ayudar a establecer protocolos de calidad de datos estándar y mejorar la precisión de la vinculación de los registros.
Un buen ejemplo de ello fue el de Minnesota, donde los organismos estatales colaboraron para combinar su sistema SLDS con el Sistema de Datos Longitudinales de la Primera Infancia (ECLDS), ambas infraestructuras informáticas gestionadas por los Servicios Informáticos de Minnesota (MNIT). El MNIT realizó un perfil de datos en profundidad para revelar los nombres y descripciones de los archivos de datos y los formatos previstos de los mismos. Tras la actividad, MNIT pudo determinar las convenciones de denominación de los archivos para la coherencia de los informes y los elementos de datos en los que centrarse para la exactitud de la correspondencia.
3. Limpiar los errores y estandarizar los formatos de datos
También es vital realizar una depuración de datos para limpiar y eliminar los errores e incoherencias de los datos que pueden afectar a la precisión de la correspondencia y afectar a la salud general del SLDS y otros datos de los estudiantes. Durante la fase de depuración de datos, todos los cambios previstos en los datos deben estar en consonancia con los requisitos de todas las partes interesadas, desde los profesores y administradores de las escuelas hasta los investigadores y los responsables de la política educativa.
Durante la limpieza de datos, los usuarios finales pueden llevar a cabo una serie de tareas como:
- Corregir errores ortográficos, de puntuación, de redacción y de formato
- Eliminar o reemplazar los caracteres especiales, los caracteres con números, los caracteres con letras para los campos apropiados
- Corregir los patrones de datos asegurándose de que se ajustan a los patrones establecidos, como RegEX
- Cree patrones de campo propios y patentados
- Estandarice los campos de nombre, dirección, número de teléfono y código postal para evitar problemas de resolución de identidades y mucho más
Una vez eliminados todos los errores conocidos, los datos se preparan para su cotejo en diferentes conjuntos de datos.
4. Identificar los registros duplicados y redundantes
La búsqueda y eliminación de datos redundantes y duplicados comienza con la creación de reglas de concordancia y configuraciones más adecuadas para los campos individuales. Durante la vinculación interinstitucional, es posible que los estudiantes del SLDS de educación infantil tengan un número de seguimiento de identificación distinto del que se encuentra en los datos de K12 y de la mano de obra.
En el caso de las coincidencias deterministas, esto será problemático, ya que la presencia de ID de seguimiento variables o ausentes y otras IIP pueden inhibir las coincidencias. Sin embargo, con la concordancia difusa y fonética, la probabilidad de coincidencias puede aumentar considerablemente; los duplicados y datos redundantes resultantes pueden descartarse o enriquecerse en función de los objetivos de la organización.
Cómo puede ayudar DataMatch Enterprise de Data Ladder con los datos educativos
Una herramienta de vinculación de registros como DataMatch Enterprise tiene la amplitud de funciones y soluciones más adecuadas para resolver proyectos de SLDS a gran escala y otros proyectos de datos educativos con una tasa de coincidencia superior al 90%.
Un estudio independiente realizado por la Oficina de Política del BOR descubrió que el algoritmo de comparación probabilística de Data Ladder superaba a un algoritmo propio. En el estudio, el archivo de datos de los estudiantes del Departamento de Educación del Estado de Connecticut (SDE) se cotejó con el National Student Clearinghouse (NSC) para determinar el número de graduados de la escuela secundaria que se inscribieron en la institución postsecundaria.
La solución interna obtuvo 15.570 coincidencias, mientras que la solución de Data Ladder dio 16.600 coincidencias, es decir, 1.030 coincidencias más.
La alta precisión de coincidencia de DataMatch Enterprise puede atribuirse a algoritmos de coincidencia propios y establecidos y a varias características que ayudan a identificar la precisión de coincidencia de alta precisión. Estos son:
- Archivos Excel, SQL y conectividad de repositorios basados en Hadoop para procesar más de 2.000 millones de registros
- Patrones RegEx incorporados para autodetectar y perfilar errores de ortografía, puntuación y otros datos
- Conjunto de transformaciones para limpiar y estandarizar el nombre, la dirección y otros campos
- Algoritmos de concordancia exactos, fonéticos propios y difusos establecidos, incluyendo Jaro-Wrinkler para encontrar resultados coincidentes y más.
Para leer un caso de éxito de DataMatch Enterprise, haga clic aquí.
Conclusión:
El sector educativo se ve afectado por problemas de calidad de los datos, como la falta de identificadores comunes y los silos de datos, que pueden dificultar la vinculación de los datos y los resultados de precisión en los proyectos de SLDS financiados por el Estado. Aunque la concordancia exacta puede ser útil en determinados contextos, un software de vinculación de registros con concordancia probabilística puede ser mucho más eficaz para identificar coincidencias entre conjuntos de datos dispares.
Para obtener más información sobre cómo DataMatch Enterprise puede trabajar para su K12, P-20W o cualquier otra iniciativa de datos SLDS, por favor, vea nuestras
soluciones para la industria de la educación
o
póngase en contacto con nosotros
para ponerse en contacto con nuestro equipo de ventas.



