





























Last Updated on mars 22, 2022
Le couplage d’enregistrements est souvent un élément nécessaire à l’exécution efficace de différentes initiatives éducatives. Qu’il s’agisse de mesurer les performances des élèves et des enseignants au fil du temps et dans plusieurs écoles ou d’évaluer l’efficacité des programmes éducatifs au niveau de l’État.
Cependant, certains défis industriels existent et nuisent à l’intégrité des données. Comme les organismes d’enseignement doivent s’appuyer sur les systèmes longitudinaux à l’échelle de l’État (SLDS) pour comprendre la portée des données, la présence de données en double, manquantes et autres données erronées peut conduire à des conclusions inexactes et entraver les mesures politiques.
Une solution pour résoudre ces problèmes consiste à utiliser un logiciel de couplage d’enregistrements de haute précision. Dans ce billet, nous examinerons les défis et les limites de l’exactitude des données dans le secteur de l’éducation et nous vous éclairerons sur la manière d’améliorer l’exactitude et la qualité des données.
Qu’est-ce que le SLDS et pourquoi est-il important pour le secteur de l’éducation ?
Les systèmes SLDS sont des bases de données qui regroupent des données sur les élèves collectées à partir de plusieurs systèmes de données et qui suivent les données clés de l’école maternelle au lycée, à l’université et au marché du travail. L’objectif sous-jacent est d’aider les enseignants, les administrateurs, les départements d’éducation des États, etc. à évaluer les politiques liées à l’éducation en analysant les données sur les élèves recueillies sur plusieurs années, programmes et écoles.
L’importance des systèmes SLDS est apparue lorsque les données éducatives stockées dans des ensembles de données disparates et cloisonnés dans différentes agences ont posé des problèmes pour obtenir une vue d’ensemble des données sur les étudiants dans tout l’État. Actuellement, les États sont mandatés au niveau fédéral pour construire et diffuser des systèmes SLDS afin que toutes les parties prenantes puissent analyser, affiner et améliorer l’ensemble de l’écosystème éducatif.
Grâce à un système SLDS, les différentes parties prenantes peuvent répondre à diverses questions, repérer les tendances et évaluer les décisions de nombreuses manières. Il s’agit notamment de :
- Enseignants et administrateurs de l’éducation : ils peuvent vouloir évaluer l’efficacité des programmes d’éducation de la petite enfance, de la maternelle à la douzième année et d’autres programmes éducatifs ; les caractéristiques des élèves les plus performants par rapport aux élèves les moins performants, la durée d’inscription des élèves au collège et dans l’enseignement supérieur, etc.
- Lesdécideurs politiques et les législateurs d’État : la supervision, l’évaluation et la réforme des programmes d’éducation pour qu’ils puissent bénéficier de subventions seront une préoccupation majeure des décideurs politiques et des législateurs en matière d’éducation. Par exemple, à la lumière de la subvention de 13 milliards de dollars accordée dans le cadre de la loi CARES, les chercheurs et les décideurs pourraient vouloir évaluer l’impact des outils d’apprentissage en ligne sur les performances des étudiants par rapport à l’enseignement en classe, afin de vérifier le succès de programmes similaires dans les situations d’urgence.
- Agences et départements de l’éducation des États : les départements des États doivent s’appuyer sur des données longitudinales pour faire des inférences sur les caractéristiques qui ont un impact sur la progression dans le système éducatif au sein d’un État, la recherche sur l’éducation technique et les résultats professionnels, ainsi que l’impact sur l’emploi et le chômage.
Les défis des données éducatives
1. Les systèmes SLDS contiennent des données en silo
Les systèmes SLDS peuvent contenir de nombreux éléments de données mais ne sont pas suffisamment cohérents pour présenter un compte rendu fidèle des performances d’un élève à travers plusieurs programmes d’enseignement et des heures supplémentaires. En bref, ils ne sont pas conçus pour l’intégration ou l’établissement de rapports, mais surtout pour le stockage.
2. Manque d’uniformité des rapports
Les données relatives à l’éducation (résultats des tests des élèves, jours d’absence, dates d’inscription) sont généralement collectées en réponse aux exigences spécifiques d’un programme individuel. Par exemple, les bases de données du National Reporting System (NRS) peuvent contenir de nombreuses données sur l’éducation des adultes. Cependant, les chercheurs auront du mal à tirer des conclusions sur les résultats de l’éducation des adultes en raison des programmes d’éducation de la petite enfance.
3. Limites de l’interconnexion des données entre agences
Les informations personnellement identifiables (PII) telles que le numéro de sécurité sociale, le numéro de compte bancaire, le numéro d’immatriculation du véhicule, le numéro de passeport, etc. sont cruciales pour l’identification de contacts uniques et précis.
Cependant, de nombreuses agences d’éducation de l’État (SEA) et agences d’éducation locales (LEA) peuvent être réticentes à partager des données vitales sur les étudiants avec des tiers, au risque d’enfreindre la loi sur les droits et la confidentialité en matière d’éducation familiale (FERPA).
Par conséquent, toute initiative de liaison de données inter-agences visant à créer des entrepôts de données SLDS peut présenter des problèmes de localisation d’identifiants uniques permettant de suivre les étudiants de l’école maternelle à la vie active et dans plusieurs États.
Améliorer le lien entre les enregistrements pour les enregistrements Golden
Correspondance déterministe et correspondance probabiliste
Lecouplage d’enregistrements ou la résolution d’entités fait référence au processus d’identification et de comparaison de deux ou plusieurs enregistrements similaires pour s’assurer qu’ils se rapportent ou non à la même entité. En général, une correspondance est identifiée lorsque les ensembles de données comparés sont normalisés et que des identifiants uniques sont présents ou cohérents. Dans ce cas, la correspondance déterministe, ou correspondance exacte, est idéale.
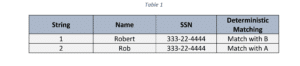
Mais que faire en l’absence d’identifiant unique ou lorsque les formats de données sont incohérents et varient ? C’est là que la correspondance probabiliste doit être utilisée. Il fonctionne en évaluant la mesure dans laquelle deux ou plusieurs enregistrements similaires se situent entre 0 et 1 pour identifier une correspondance. Dans ce cas, il n’est pas nécessaire que des identifiants uniques soient présents pour classer une correspondance en vue du couplage d’enregistrements.
Pourquoi la correspondance probabiliste est essentielle pour améliorer les données SLDS
- Ladisparité des champs peut créer des problèmes pour trouver des dossiers d’étudiants uniques: Dans le cas de la fusion de bases de données SLDS disparates, il n’est pas rare de trouver le nom, l’adresse et d’autres champs existant dans deux formats ou plus. Par exemple, un ensemble de données peut stocker les données relatives au nom en tant que « Nom complet », tandis qu’un autre peut avoir « Prénom » et « Nom ».
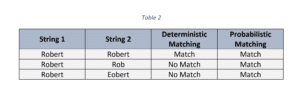
- Manque d’identifiants uniques : Étant donné que les données PII peuvent facilement être égarées ou perdues après la consolidation des données sur les étudiants provenant de différentes bases de données, la mise en relation des enregistrements par le biais d’une correspondance déterministe ou exacte peut conduire à des résultats manquants et à des faux positifs plus élevés. La correspondance probabiliste, quant à elle, a la capacité de classer les correspondances lorsque deux enregistrements comparables ne sont pas exacts et en l’absence d’un identifiant commun.

Comme le montre le tableau 3, la correspondance probabiliste peut identifier une correspondance avec un enregistrement similaire même sans la présence d’un identifiant unique (dans ce cas – SSN).
Les moyens d’améliorer l’exactitude des données
Un couplage efficace des enregistrements va de pair avec des données propres et cohérentes. Plus la qualité des données SLDS est bonne – absence de valeurs nulles, d’entrées mal formatées et de fautes de casse et d’orthographe – plus il sera facile pour les utilisateurs finaux de trouver des correspondances et de déterminer les enregistrements dorés dans plusieurs agences.
Voici quelques moyens d’y parvenir.
1. Identifier toutes les sources de données
Tout d’abord, identifiez tous les points d’entrée des données pour votre projet. Cela dépendra en grande partie de vos objectifs et résultats en matière de données.
La mise en œuvre d’initiatives SLDS à grande échelle pour le K12 ou le P-20W nécessite souvent de consolider des systèmes SLDS disparates afin d’améliorer l’intégrité des infrastructures de données existantes.
Le projet financé par l’État du département de l’éducation de Géorgie (GDOE), qui vise à améliorer les données SLDS en intégrant les données des organismes suivants, en est un exemple :
- Le département de la justice juvénile
- Département des services à l’enfance et à la famille
- Tribunal des mineurs et
- PeachNet (réseau éducatif de la Géorgie)
Il est également important de reconnaître la variété des sources de données pour l’ingestion ; alors que les districts et les départements d’éducation de l’État peuvent avoir des données agrégées dans des bases de données relationnelles, les écoles et les collèges peuvent avoir des résultats de tests et des performances mises à jour plus facilement dans des fichiers Excel ou des applications web. Une fois que toutes les sources de données sont identifiées pour l’ingestion, une stratégie claire pour l’ensemble de l’écosystème de données et les objectifs peuvent être atteints.
2. Réaliser un profil de données approfondi
L’établissement d’un bilan de santé convaincant des données avant toute préparation ou nettoyage des données peut permettre d’améliorer considérablement la qualité des données. Le profilage des données peut aider à révéler des statistiques importantes sur les sources de données, depuis le pourcentage de données manquantes et le type de champs jusqu’à l’étendue des erreurs de formatage et d’orthographe. Cela peut aider à établir des protocoles standard de qualité des données et à améliorer la précision du couplage des enregistrements.
Le Minnesota en est un bon exemple : les agences de l’État ont collaboré pour combiner leur système SLDS avec le système de données longitudinales sur la petite enfance (ECLDS), deux infrastructures informatiques gérées par les services informatiques du Minnesota (MNIT). Le MNIT a effectué un profilage approfondi des données afin de révéler les noms et les descriptions des fichiers de données ainsi que les formats attendus des données. À la suite de cette activité, le MNIT a été en mesure de déterminer les conventions de dénomination des fichiers pour assurer la cohérence des rapports et les éléments de données sur lesquels il faut se concentrer pour assurer l’exactitude des correspondances.
3. Nettoyer les erreurs et normaliser les formats de données
Il est également essentiel d’effectuer un nettoyage des données afin de nettoyer et d’éliminer les erreurs et les incohérences qui peuvent nuire à la précision des correspondances et affecter la santé générale du SLDS et des autres données sur les étudiants. Au cours de la phase de nettoyage des données, toutes les modifications attendues doivent être conformes aux exigences de toutes les parties prenantes – des enseignants et administrateurs des écoles aux chercheurs et aux responsables de la politique de l’éducation.
Pendant le nettoyage des données, les utilisateurs finaux peuvent effectuer diverses tâches telles que :
- Corriger les erreurs d’orthographe, de ponctuation, de casse et de formatage
- Supprimez ou remplacez les caractères spéciaux, les caractères avec des chiffres, les caractères avec des lettres pour les champs appropriés.
- Corriger les modèles de données en s’assurant qu’ils sont conformes aux modèles établis tels que RegEX
- Créer des modèles de champ propres et exclusifs
- Normaliser les champs de nom, d’adresse, de numéro de téléphone et de code postal pour éviter les problèmes de résolution d’identité, etc.
Après avoir éliminé toutes les erreurs connues, les données sont ensuite préparées pour être mises en correspondance avec différents ensembles de données.
4. Identifier les enregistrements en double et redondants
La recherche et la suppression des données redondantes et en double commencent par la création de règles de correspondance et de configurations adaptées aux différents champs. Lors de la liaison inter-agences, il est possible que les étudiants de l’éducation de la petite enfance SLDS aient un numéro de suivi d’identification distinct de celui trouvé dans les données K12 et de la main-d’œuvre.
Dans le cadre d’une correspondance déterministe, cela sera problématique car la présence d’identifiants de suivi et d’autres IPI variables ou manquants peut empêcher les correspondances. Avec la correspondance floue et phonétique, cependant, la probabilité de correspondance peut augmenter de manière significative ; les doublons et les données redondantes qui en résultent peuvent être éliminés ou enrichis en fonction des objectifs de l’organisation.
Comment DataMatch Enterprise de Data Ladder peut aider avec les données sur l’éducation
Un outil de couplage d’enregistrements tel que DataMatch Enterprise possède l’étendue des fonctionnalités et des solutions les mieux adaptées à la résolution de projets à grande échelle de SLDS et d’autres données sur l’éducation avec un taux de correspondance de 90 % et plus.
Une étude indépendante menée par le BOR Office of Policy a révélé que l’algorithme de comparaison probabiliste de Data Ladder était plus performant qu’un algorithme propriétaire interne. Dans le cadre de cette étude, le fichier de données sur les étudiants du Connecticut State Department of Education (SDE) a été mis en correspondance avec le National Student Clearinghouse (NSC) afin de déterminer le nombre de diplômés du secondaire qui se sont inscrits dans un établissement d’enseignement postsecondaire.
La solution interne a obtenu 15 570 correspondances, tandis que la solution de Data Ladder en a obtenu 16 600, soit 1 030 correspondances supplémentaires.
La grande précision de correspondance de DataMatch Enterprise peut être attribuée à des algorithmes de correspondance propriétaires et établis, ainsi qu’à diverses caractéristiques qui permettent d’identifier une précision de correspondance élevée. Ce sont :
- Fichiers Excel, SQL et connectivité des référentiels Hadoop pour traiter plus de 2 milliards d’enregistrements.
- Modèles RegEx intégrés pour la détection automatique et le profilage des erreurs d’orthographe, de ponctuation et autres erreurs de données.
- Une série de transformations pour nettoyer et normaliser les champs de nom, d’adresse et autres.
- Algorithmes de correspondance exacts, phonétiques propriétaires et flous établis, y compris Jaro-Wrinkler pour trouver des résultats de correspondance et plus encore.
Pour lire une histoire de réussite de LEA concernant DataMatch Enterprise, cliquez ici.
Conclusion
Le secteur de l’éducation est confronté à des problèmes de qualité des données, tels que le manque d’identifiants communs et le cloisonnement des données, qui peuvent entraver la mise en relation des données et l’obtention de résultats précis dans les projets SLDS financés par l’État. Si la correspondance exacte peut être utile dans certains contextes, un logiciel de couplage d’enregistrements avec correspondance probabiliste peut être bien plus efficace pour identifier les correspondances entre des ensembles de données disparates.
Pour plus d’informations sur la façon dont DataMatch Enterprise peut fonctionner pour votre K12, P-20W ou toute autre initiative de données SLDS, veuillez consulter nos
solutions pour le secteur de l’éducation
ou
contactez-nous
pour entrer en contact avec notre équipe de vente.



