





























Last Updated on April 14, 2022
Adressdaten sind halbstrukturiert, was sie zu einer der schwierigsten Komponenten bei einem Datenabgleich macht. Lange Zeit wurden manuelle Datenabgleichsmethoden mit umfangreicher SQL-Programmierung und Tabellenkalkulationsformeln zum Abgleich von Adresslisten verwendet. Dies mag zwar in der Vergangenheit praktikabel und effektiv gewesen sein, ist aber heute keine praktikable Methode mehr, um komplexe Daten aus Drittquellen zu verarbeiten.
In diesem kurzen Beitrag gehe ich auf die wichtigsten Herausforderungen beim manuellen Abgleich von Adressdaten ein und zeige, wie Ihr Team mit einer Self-Service-Lösung per Mausklick seine Produktivität und Effizienz steigern und gleichzeitig genaue Ergebnisse erzielen kann.
P.S. Wir haben uns in unseren früheren Leitfäden ausführlich mit der Standardisierung und Validierung von Adressen beschäftigt. Für diejenigen, die mit dem Konzept und dem Prozess nicht vertraut sind, wird der folgende Beitrag von großem Nutzen für das Verständnis dieses Artikels sein.
Einige der wichtigsten Fragen, die in diesem Beitrag behandelt werden, sind:
- Was ist der Datenabgleich im Prozess der Adressstandardisierung und -validierung?
- Welche Funktionen und Komponenten sind am Adressdatenabgleich beteiligt?
- Die größten Herausforderungen beim Datenabgleich für Adressdaten
- Fallstudie Cabarrus
Schauen wir genauer hin.
Was ist der Datenabgleich im Prozess der Adressstandardisierung und -validierung?
Angenommen, Sie haben zwei Kundendatensätze A und B, wobei Satz A die Kunden der Altersgruppe 20 – 35 repräsentiert, während Satz B zur Altersgruppe 35 – 50 gehört. Die meisten Personen in diesen Listen haben die gleiche (Mitglieder der gleichen Familie) oder eine ähnliche Adresse (z. B. Mitglieder einer Wohngemeinschaft). Sie möchten die beiden Listen konsolidieren, damit Sie nur ein Rundschreiben anstelle von drei Briefen an drei Mitglieder derselben Familie verschicken können.
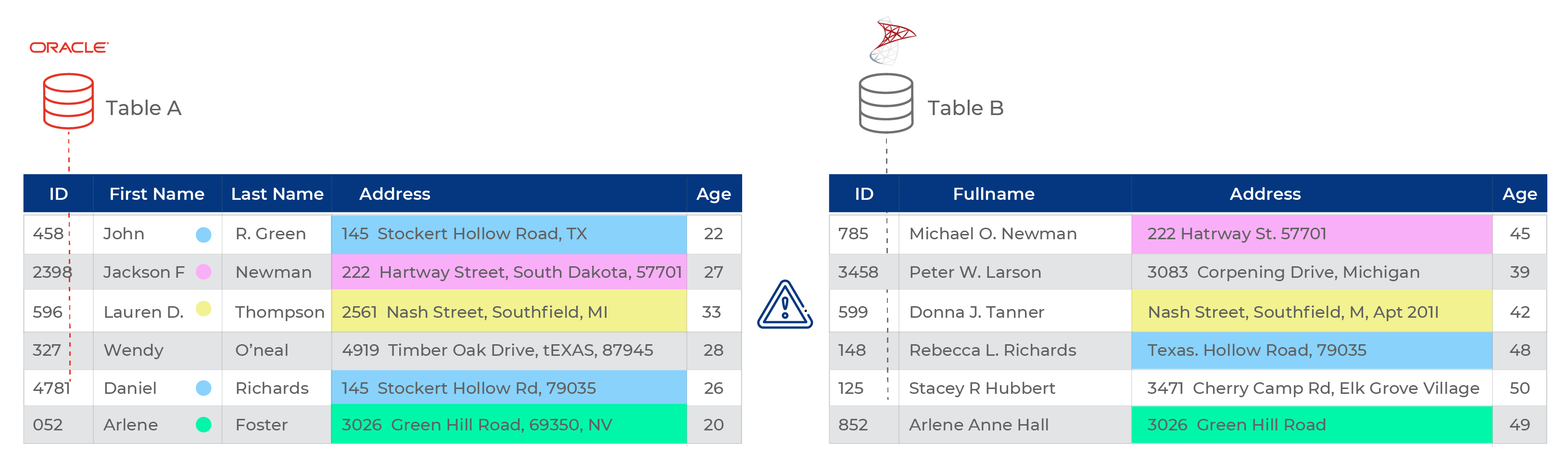
DerDatenabgleich ist der Prozess, der es Ihnen ermöglicht, diese beiden Gruppen auf der Grundlage ihrer Adressdaten abzugleichen und zu konsolidieren, um eine endgültige Liste der Kunden zu erhalten, die dieselbe Adresse haben.
Klingt einfach?
Nur wenn es so wäre!
Die Daten in Satz A können zum Beispiel aus ähnlichen oder genauen Adressen innerhalb derselben Liste bestehen. Das bedeutet, dass Sie zunächst die Datensätze in Satz A abgleichen, ableiten, eine Liste eindeutiger Datensätze erhalten und diese als neuen Datensatz speichern müssen. Sie müssen den gleichen Vorgang mit Set B wiederholen.
Als Nächstes stellen Sie vielleicht fest, dass mehrere Datensätze der neuen Ableitungen von Satz A und B ähnlich sind. Sie führen also erneut einen Datenabgleich zwischen den beiden Datensätzen durch, um einen dritten Datensatz zu erstellen, der die konsolidierten Informationen von Satz A und B enthält. Vielleicht müssen Sie sie auch anpassen!
Der Prozess ist verblüffend und iterativ. Stellen Sie sich vor, Sie müssten all dies manuell erledigen.
Dieser scheinbar einfache Abgleich würde Tage in Anspruch nehmen. Die Benutzer müssten die Daten zunächst entweder aus einer Datenquelle extrahieren, bei der es sich um ein CRM, ein ERP oder ein Data Warehouse handeln könnte. Die Daten werden dann in Form von Tabellenkalkulationsdateien an die Geschäftsanwender weitergegeben, und dann beginnt die eigentliche Arbeit. Geschäftsanwender müssten die Daten auf häufige Fehler analysieren, die Informationen jeder Spalte überprüfen, Tippfehler bereinigen und Excel-Formeln verwenden, um leere oder doppelte Felder zu erkennen. Dieser Vorgang wird für jeden Datensatz, der abgeglichen werden muss, wiederholt. Sobald der Benutzer mit der Qualität des Datensatzes zufrieden ist, beginnt er mit dem Abgleich.
In Situationen, in denen Geschäftsanwender nicht involviert sind, wird der Datenabgleich durch umfangreiche SQL-Abfragen durchgeführt. Der Nachteil dabei ist, dass die Geschäftsanwender die Daten nicht wirklich analysieren und verstehen können. Was ist, wenn sie zusätzliche Daten in Bezug auf Geschlecht und Beruf erhalten möchten? Sie müssen diesen Prozess an die IT-Abteilung weiterleiten, und der ganze langwierige Prozess wird überarbeitet oder wiederholt, um eine Übereinstimmung zu erzielen.
Herausforderungen beim Datenabgleich für Adressen
Der Datenabgleich ist eine notwendige Funktion bei der Arbeit mit tabellarischen Daten, aber er ist nicht einfach.
Einige der wichtigsten Herausforderungen, denen sich unsere Kunden beim Datenabgleich stellen müssen, sind:
- Sicherstellung der Genauigkeit der Daten: Die meisten Unternehmen verfügen entweder nicht über ein Datenbereinigungssystem oder haben Datenverwalter, die komplexe Abfragen verwenden, um eine grundlegende Datenbereinigung durchzuführen. Dennoch sind Probleme wie negative Abstände, Fettfinger-Tippfehler, versehentliche Verwendung von Interpunktionszeichen usw. sind nicht leicht zu erkennen. Außerdem dauert es lange, Adressdaten zu normalisieren und zu standardisieren, zumal sie am fehleranfälligsten sind.

- Sammeln von Daten aus unterschiedlichen Quellen: Daten sind in der Regel nicht ohne weiteres für den Abgleich verfügbar. Die Daten müssen in der Regel aus verschiedenen Quellen zusammengetragen werden, was es noch schwieriger macht, die Genauigkeit zu gewährleisten. So müssen viele Unternehmen beispielsweise Daten von Anbietern und Drittanbieter-Apps für die Analyse sammeln. Da sich diese Datenquellen jedoch in ihrer Struktur voneinander unterscheiden, kann es schwierig sein, sie abzugleichen. Dieses Problem ist nicht nur auf Instanzen externer Daten beschränkt. Unternehmen, die mit mehreren Anwendungen verbunden sind oder mehrere Plattformen nutzen, haben oft Schwierigkeiten, ihre Daten für Analysen oder Erkenntnisse zu konsolidieren.
- Fehlende Messung der Datenübereinstimmungsergebnisse: Leider messen die Unternehmen in der Regel nicht, wie gut die Daten übereinstimmen. Beim Datenabgleich gibt es zwei häufige Probleme: falsch positive und falsch negative Ergebnisse. Beides geht zu Lasten der Zeit und des Aufwands des Unternehmens.
So werden beispielsweise zwei Datenquellen abgeglichen, um doppelte Adressen innerhalb eines bestimmten Blocks zu ermitteln. 8 von 20 Adressen stimmen überein, was auf eine Doppelung sowie auf die Verwendung einer Adresse für mehrere Personen (z. B. Familienmitglieder) hinweist. Allerdings sind 4/20 Übereinstimmungen falsch-positiv, d.h. die Adressen werden als übereinstimmend vorhergesagt, gehören aber nicht zur selben Person. Ein fehlender Wert, z. B. eine Hausnummer, kann die Ursache für einen falsch positiven Treffer sein. 6/20 sind falsch negativ, d. h. die Adressen stimmen zwar überein und gehören zu derselben Person, aber das System hat sie aufgrund von Variablen wie einem fehlenden oder unvollständigen zweiten Vornamen oder einer fehlenden Postleitzahl usw. völlig übersehen.
In beiden Fällen müssen die Teams Zeit aufwenden, um die Informationen manuell zu überprüfen und zu validieren. Der manuelle Abgleich von Adressdaten funktioniert nur dann am besten, wenn es keine Unstimmigkeiten in den Daten gibt. Aber wie wir wissen, sind Daten, insbesondere moderne Daten, alles andere als konsistent.
Die Lösung – Wie erhalten Sie exakte Adressdatenabgleiche?
Ich könnte Ihnen einfach sagen, dass Sie sich ein Spitzenwerkzeug für den Datenabgleich besorgen sollen, und das wäre die Lösung für alle Ihre Probleme (manueller Aufwand, fehlende SQL-Ressourcen usw.), aber so funktioniert es nicht.
Es gibt einen ganzes Verfahren zum Abgleich von Adressdaten.
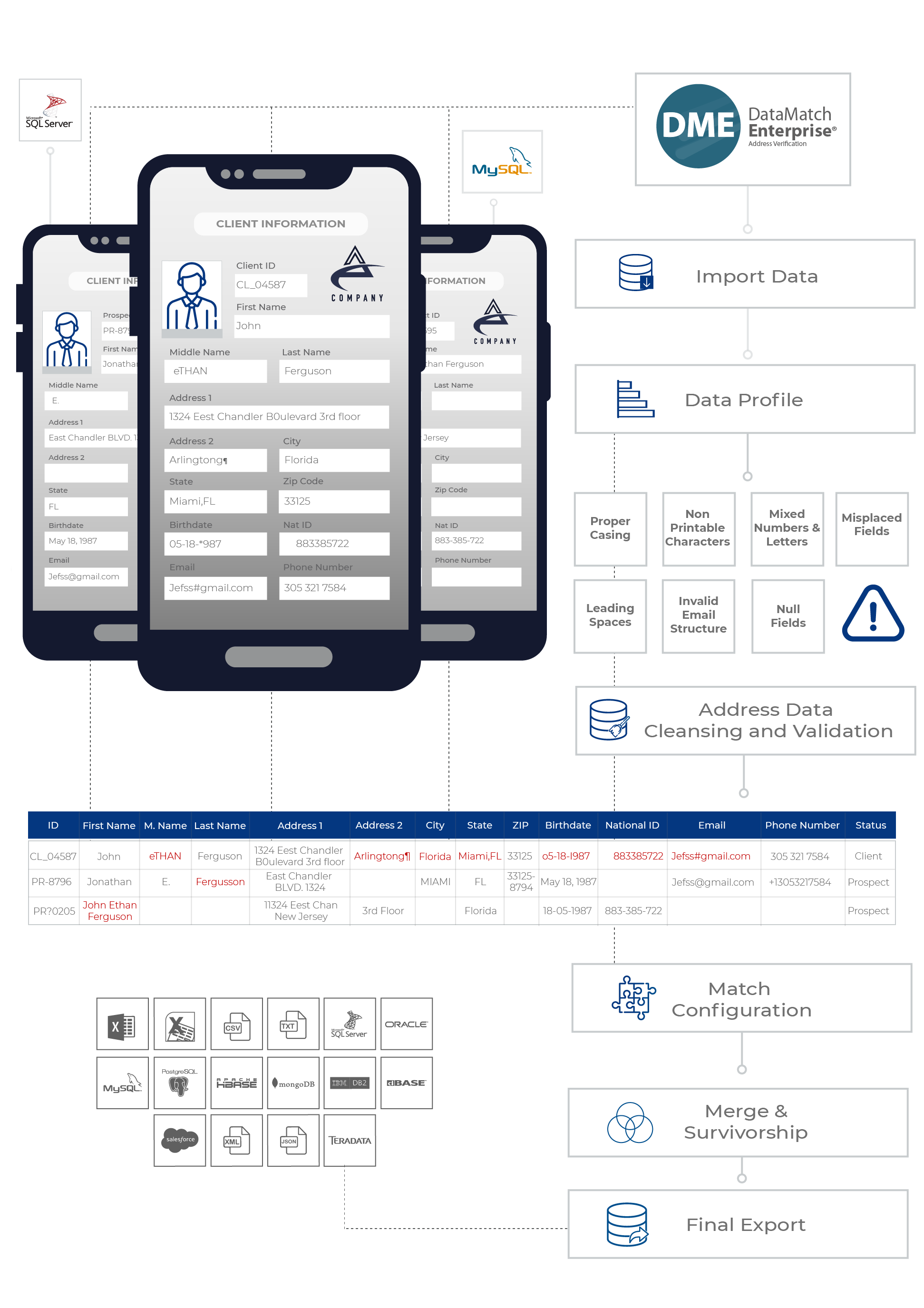
- Integrieren Sie Ihre Datenquellen: Wenn Sie Daten aus mehreren Quellen sammeln, müssen Sie diese in eine Plattform integrieren, um den Abgleich zu initiieren. Die Integration von Daten ist jedoch nicht einfach. Sie müssen die Daten extrahieren und in eine CSV-Datei oder Ihre Datenbank übertragen. In jedem Fall müssen Sie die Daten aufbereiten, bevor Sie sie verschieben können.
- Profiling der Daten: Bei der Aufbereitung der Daten wird im Grunde ein Profil erstellt, um festzustellen, ob sie Fehler, Tippfehler oder fehlende Werte enthalten. Wenn Sie diesen Schritt auslassen, wird der Abgleich fehlschlagen. Sie benötigen genaue Daten, um einen effektiven Abgleich durchführen zu können.
Normalisierung und Bereinigung der Daten:
Sollten alle Städte geschrieben werden als
NY, NYC oder ny geschrieben werden?
Sollten alle Adressen eine Postleitzahl haben? Sollten etwaige -Zeichen zwischen den Zahlen entfernt werden? Dies sind alles Kleinigkeiten, die die Qualität Ihrer Daten beeinträchtigen. Um einen effektiven Abgleich durchzuführen, müssen Sie diese Unstimmigkeiten beseitigen. Das ist an sich schon eine anspruchsvolle Aufgabe. Datenwissenschaftler/Analysten verbringen 80 % ihrer Zeit damit, diese Daten zu bereinigen.- Validierung von Adressdaten: Und das ist der schwierige Teil. Wussten Sie, dass die meisten Adressen, die Sie haben, wahrscheinlich nicht einmal gültig sind? Die Menschen neigen dazu, unvollständige, falsche oder sogar gefälschte Adressen anzugeben. Wenn Sie bei Ihren Mailing-Aktivitäten aufs Ganze gehen, ohne zuvor Ihre Adressdaten zu validieren und zu überprüfen, können Sie Hunderttausende von Dollar an Mailing-Kosten verlieren. Aus diesem Grund benötigen Sie eine CASS-zertifizierte Lösung (dies ist ein von USPS zertifizierter Anbieter), die Sie bei der Adressvalidierung unterstützt und sicherstellt, dass Ihre Adressliste den USPS-Richtlinien entspricht.
- Schließlich das Matching: Jetzt, da Ihre Adressdaten bereinigt und validiert sind, ist es Zeit für den Abgleich. Wenn Sie eine Datenabgleichslösung wie DataMatch Enterprise verwenden, ist der Prozess einfach und leicht. Sie wählen die Spalten aus, die Sie abgleichen möchten – egal ob über, zwischen oder innerhalb von Datenquellen -, passen die Abgleichskriterien an und das war’s! Sie erhalten innerhalb von Minuten Ergebnisse.
Und jetzt kommt der Teil, in dem ich Ihnen sage, warum Sie eine Self-Service-Datenabgleichslösung wie DataMatch um diesen Prozess durchzuziehen. Einfach ausgedrückt, mit dieser Lösung können Sie:
-
- Zeitersparnis, die fast 80 % des manuellen Aufwands ausmacht
-
- Verbessern Sie die Effizienz und lassen Sie Ihrem Team mehr Zeit für die Analyse der Daten, anstatt sie zu bereinigen.
-
- Bestätigen Sie Ihre Adresse. Wir sind eine CASS-zertifizierte Lösung und können die Adressen in den USA, Kanada und Großbritannien überprüfen.
-
- Führen Sie den Datenabgleich mit einer hohen Trefferquote durch. In mehreren Studien und Berichten übertraf Data Ladder SAS und IBM in Bezug auf die Trefferquote. Wir sind die einzige Lösung, die eine Trefferquote von 96 % (mindestens) bietet. Bei komplexen Daten benötigen Sie eine Lösung für den Datenabgleich, die äußerst genaue Ergebnisse liefert. Alles, was darunter liegt, bedeutet einen höheren manuellen Aufwand beim Aussortieren von falsch positiven und negativen Ergebnissen.
-
- Konsolidieren Sie Ihre Daten und erstellen Sie einfach Datensätze. Sie müssen nicht ständig Daten hin- und herschieben. Durch Abgleich, Zusammenführung und Deduktion erhalten Sie eine neue Liste, die Sie verwenden und ausbauen können.
Auf diese Weise haben wir mehreren US-amerikanischen Regierungs- und Bildungseinrichtungen geholfen, nicht nur Adressdaten abzugleichen, sondern auch die Gesamtqualität der Daten zu verbessern.
Wie Cabarrus Education beim Abgleich von Adressdaten wochenlange manuelle Arbeit einsparte
In dieser Fallstudie erfahren Sie, wie wir einem Schulbezirk geholfen haben, seine Produktivität durch Datenanalyse zu steigern und die Bereinigungszeit von Rohdaten von zwei Wochen auf nur
16 Stunden!



