































Last Updated on December 23, 2025
Address data is semi-structured, making it one of the most challenging components in a data matching activity. For long now, manual data matching methods including extensive SQL programming and spreadsheet formulas have been used to match address lists. While this may have been workable and effective in the past, it is no longer a viable method to handle complex data from third-party sources.
In this quick post, I cover key challenges to manual address data matching and how a point-to-click, self-service solution may be what your team needs to increase productivity and efficiency while obtaining accurate results.
P.S We’ve covered address standardization and validation extensively in our previous guides. For those unfamiliar with the concept and process, the following post will be hugely beneficial to understanding this article.
Some of the key questions covered in this post include:
- What is Data Matching in the Address Standardization and Validation Process?
- What are the Functions and Components Involved in Address Data Matching?
- Key Challenges with Data Matching for Address Data
- Cabarrus Case Study
Let’s dig in.
What is Data Matching in the Address Standardization and Validation Process?
Supposing you have two sets of customer data A and B, with Set A representing customers belonging to age group 20 – 35 while Set B belongs to 35 – 50. Most of the people within these lists share an exact (members of the same family) or a similar address (members of a condo for instance). You want to consolidate the two list so you can send out just one newsletter mail instead of 3 letters to 3 members of the same family.
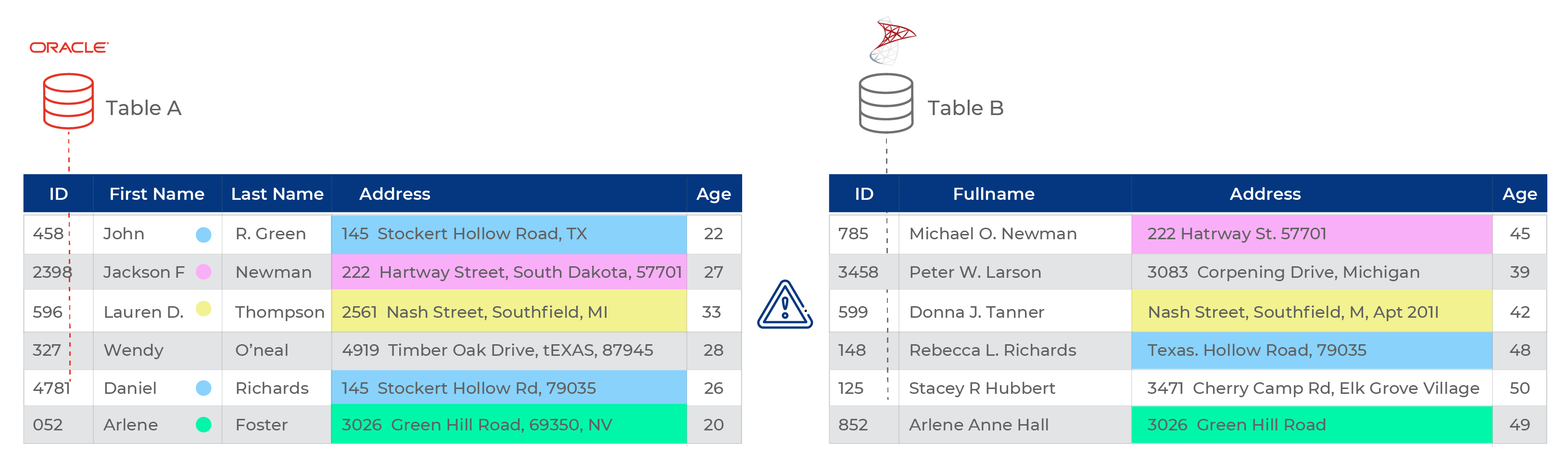
Data matching is the process that allows you to match these two sets on the basis of their address data and consolidate it to give you a final list of customers who share the same address.
Sounds easy?
Only if it were!
For instance, the data in Set A may consist of similar or exact addresses within the same list. This means you will first have to match records within Set A, dedupe, get a list of unique records and save it as a new record. You will need to repeat the same process with Set B.
Next, you may discover that several records of the new derivatives of Set A and B are similar. So you again run a data match between the two records to create a third record that holds consolidated information of Set A and B. But what about the original records? You might need to match them too!
The process is mind-boggling and iterative in nature. Imagine having to do all this manually.
This seemingly simple matching process would take days to accomplish. Users would first have to extract the data either from data source, which could be a CRM, an ERP or a data warehouse. The data would then be handed over to business users in the form of spreadsheet files and that’s when the real work starts. Business users would have to analyze the data for common errors, validate information of each column, clean typos and use Excel formulas to identify null or duplicated fields. This process is repeated for every data set that needs to be matched. Once the user is satisfied with the quality of the data set, they then start the matching process.
In situations where business users are not involved, data matching is performed through extensive SQL queries. The downside of this is the limited ability for business users to truly analyze and understand the data. What if they want to get additional data in terms of gender and occupation? They will have to communicate this process to IT and the whole tedious process is revised or repeated to get a match.
Challenges with Data Matching for Addresses
Data matching is a needed function when working with tabular data, but it’s not an easy process.
Some of the key challenges our customers face with data matching include:
- Ensuring the accuracy of the data: Most companies either do not have a data cleansing system in place or have data managers using complex queries to perform basic data cleansing. Yet, issues like negative spacing, fat-finger typos, accidental use of punctuation marks etc are not easily detected. Moreover, it takes ages to normalize and standardize address data especially since it’s the most prone to errors.

- Collecting data from disparate sources: Data isn’t usually readily available for matching. It usually has to be collected from several disparate sources, making it even more challenging to ensure accuracy. For instance, many companies have to collect data from vendors and third-party apps for analysis, but because these data sources differ from each other in terms of structure, it can be difficult to match them. This problem isn’t just limited to instances of external data. Businesses that are connected to multiple apps or use multiple platforms often find it difficult to consolidate their data for analysis or intelligence.
- Failing to measure data match scores: Unfortunately, companies usually do not measure data match scores. There are two common issues with data matching – false positives and false negatives. Both are detrimental to the company’s time and effort.
For instance, two data sources are matched to determine duplicate addresses within a specific block. 8 out of 20 addresses are a match indicating duplication as well as the use of one address for multiple people (such as members in a family). However, 4/20 matches are false positives – meaning, the addresses are predicted to match but they are not of the same person. A missing value such as a house number may be the cause of a false positive match. 6/20 are false negatives meaning the addresses do match and do belong to the same person but the system completely missed it based on variables like a missing or incomplete middle name, or missing ZIP postal codes etc.
In both cases, teams will have to spend time manually verifying and validating information. Manual address data matching efforts work best only when there are no inconsistencies in the data. But as we know it, data, especially modern data is anything but consistent.
The Solution – How Do You Get Accurate Address Data Matches?
I could simply tell you to get a top-in-line data matching tool and that would be the solution to all your problems (manual effort, lack of SQL resources etc), but that’s not how it works.
There is a whole process to matching address data.
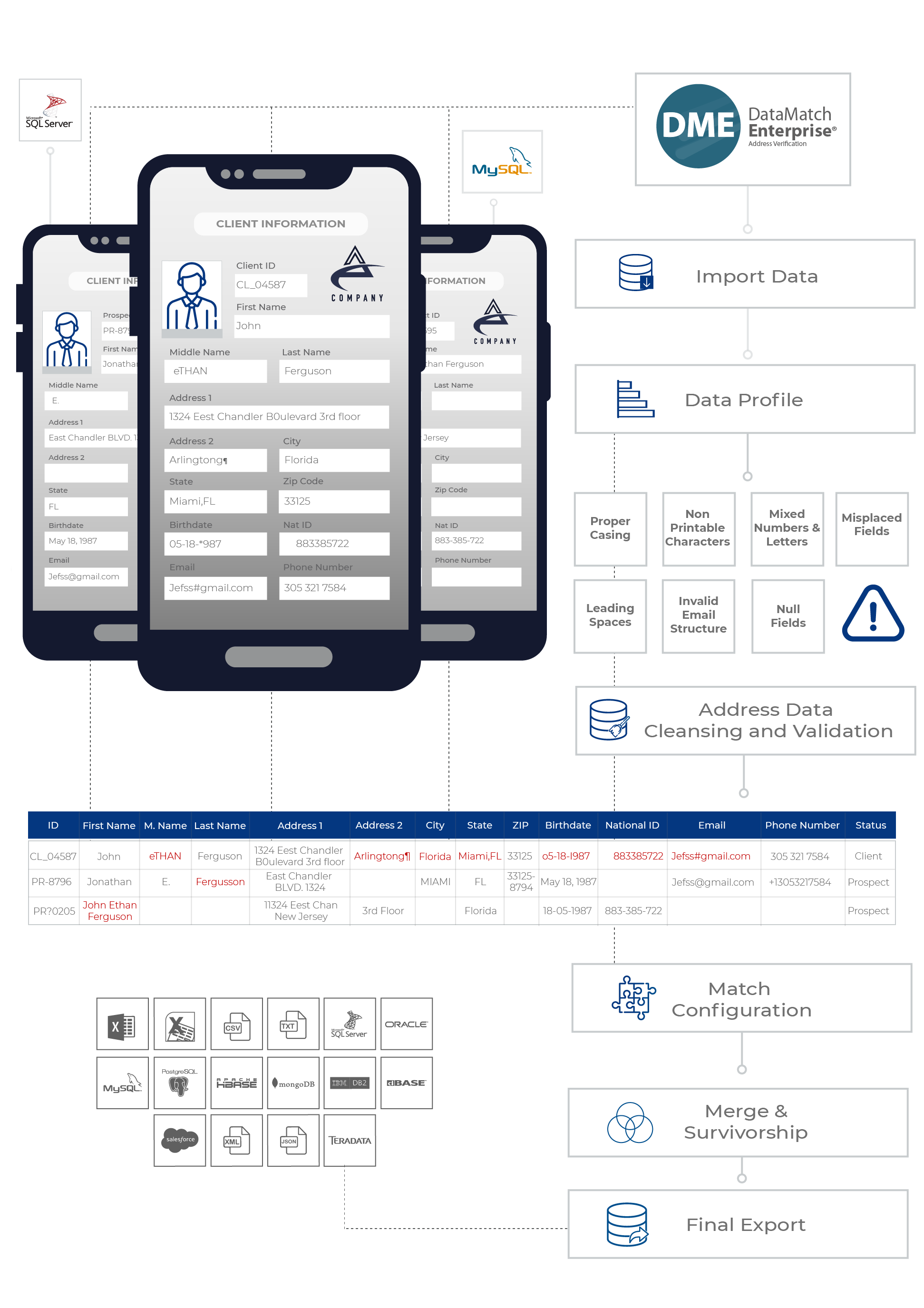
- Integrating your data sources: If you’re collecting data from multiple sources, you’ll need to integrate in within a platform to initiate the matching activity. Integrating data though isn’t easy. You’ll have to extract the data and transform it into a CSV file or your database. In either case you’ll need to prepare the data before you can move it around.
- Profiling the data: When you’re preparing the data, you’re basically profiling it to see if it contains errors, typos or missing values. If you skip this step, your matching process will fail. You need accurate data to perform an effective match.
- Normalizing & cleansing the data: Should all cities be written as NY, NYC or ny? Should all addresses have ZIP codes? Should any – marks be removed between numbers? These are all minor instances that degrade the quality of your data. To perform an effective match, you’ll need to clean up these inconsistencies. That’s a challenging task in itself. Data scientists/analysts spend 80% of their time just cleaning up this data.
- Validating address data: And this is the tricky part. Did you know most of the addresses you have is probably not even valid? People tend to enter incomplete, incorrect or even fake addresses. If you’re going all out with your mailing activities without first validating and verifying your address data, you’ll be losing hundreds of thousands of dollars in mailing costs. This is why you need CASS certified solution (this is a USPS certified vendor) to help with address validation and ensure your address list follows USPS guidelines.
- Finally the matching: Now that your address data is clean and validated, it’s time to match. If you’re using a data match solution like DataMatch Enterprise, the process is simple and easy. You select columns you want to match – whether across, between or within data sources, adjust the match criteria and that’s it! You get results within minutes.
And now here’s the part I tell you why you need a self-service data match solution like DataMatch to pull of this process. Put simply, with this solution you can:
-
- Save up on time which is nearly 80% of manual effort
-
- Improve efficiency and let your team have more time to analyze the data instead of cleaning it
-
- Validate your address. We are a CASS Certified solution and can validate the addresses of the US, Canada and the UK.
-
- Perform data matching with a high accuracy score. In multiple studies and reports, Data Ladder out beat SAS and IBM in terms of accuracy score. We are the only solution that offers a 96% accuracy match (at the least). With complex data, you will need a data match solution that returns highly accurate results. Anything lower will mean increased manual effort in sorting out false positives and negatives.
This is how we helped several US government and public education institutions not only match address data but also improve the overall quality of the data.
How Cabarrus Education Saved Weeks of Manual Labor in Matching Address Data
Read this case study to see how we helped a school district improve productivity through data parsing, cutting down the cleaning time of raw data from two weeks to just 16 hours!

