





























Last Updated on mars 29, 2022
Les données d’adresses sont semi-structurées, ce qui en fait l’un des éléments les plus difficiles à mettre en œuvre dans une activité de rapprochement de données. Depuis longtemps, des méthodes manuelles de rapprochement des données, comprenant une programmation SQL poussée et des formules de tableur, sont utilisées pour rapprocher les listes d’adresses. Si cette méthode a pu être viable et efficace par le passé, elle ne l’est plus pour traiter des données complexes provenant de sources tierces.
Dans ce billet rapide, je présente les principaux défis que pose le rapprochement manuel des données d’adresses et j’explique comment une solution en libre-service de type « point-to-click » peut être ce dont votre équipe a besoin pour accroître sa productivité et son efficacité tout en obtenant des résultats précis.
P.S. Nous avons largement couvert la normalisation et la validation des adresses dans nos guides précédents. Pour ceux qui ne sont pas familiers avec le concept et le processus, le post suivant sera extrêmement utile pour comprendre cet article.
Voici quelques-unes des questions clés abordées dans ce billet :
- Qu’est-ce que le rapprochement des données dans le processus de normalisation et de validation des adresses ?
- Quelles sont les fonctions et les composantes impliquées dans la correspondance des données d’adresse ?
- Principaux défis de la mise en correspondance des données d’adresses
- Étude de cas Cabarrus
Allons-y.
Qu’est-ce que le rapprochement des données dans le processus de normalisation et de validation des adresses ?
Supposons que vous disposiez de deux ensembles de données clients A et B, l’ensemble A représentant les clients appartenant à la tranche d’âge 20 – 35 ans tandis que l’ensemble B appartient à la tranche 35 – 50 ans. La plupart des personnes figurant sur ces listes partagent une adresse exacte (membres de la même famille) ou similaire (membres d’une copropriété par exemple). Vous voulez consolider les deux listes pour pouvoir envoyer une seule lettre d’information au lieu de 3 lettres à 3 membres de la même famille.
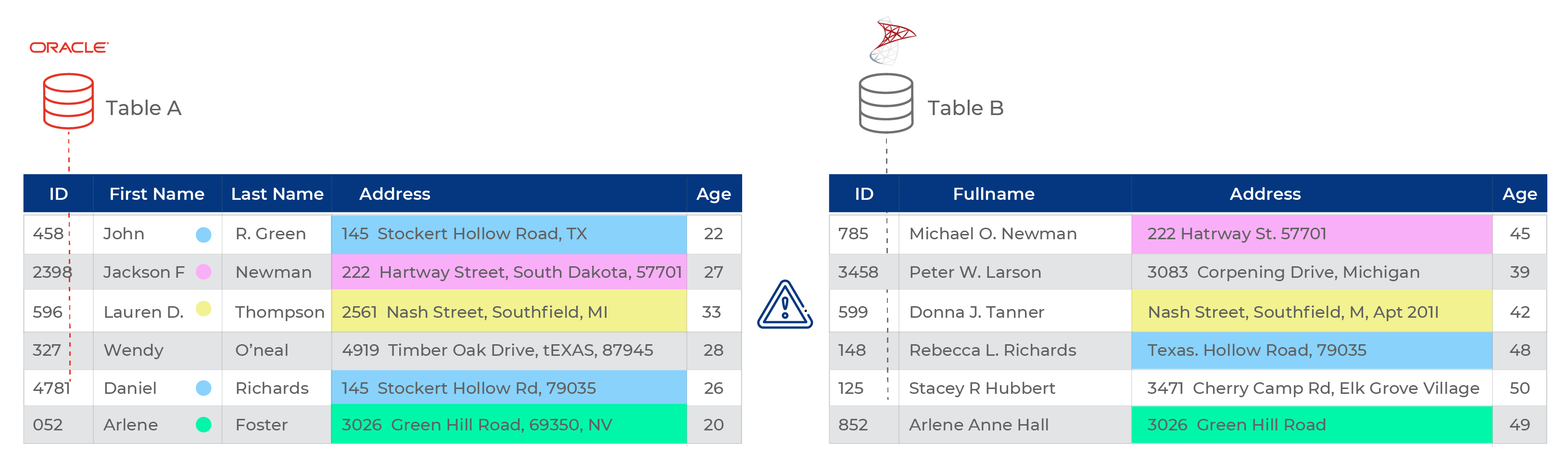
Lerapprochement des données est le processus qui vous permet de faire correspondre ces deux ensembles sur la base de leurs données d’adresse et de les consolider pour vous donner une liste finale des clients qui partagent la même adresse.
Ça semble facile ?
Seulement si c’était le cas !
Par exemple, les données de l’ensemble A peuvent consister en des adresses similaires ou exactes dans la même liste. Cela signifie que vous devrez d’abord faire correspondre les enregistrements du jeu A, les déduire, obtenir une liste d’enregistrements uniques et la sauvegarder en tant que nouvel enregistrement. Vous devrez répéter le même processus avec l’ensemble B.
Ensuite, vous pouvez découvrir que plusieurs enregistrements des nouveaux dérivés des ensembles A et B sont similaires. Vous effectuez donc une nouvelle comparaison de données entre les deux enregistrements pour créer un troisième enregistrement qui contient des informations consolidées sur les ensembles A et B. Mais qu’en est-il des enregistrements originaux ? Vous pourriez avoir besoin de les assortir aussi !
Le processus est époustouflant et itératif par nature. Imaginez devoir faire tout cela manuellement.
Ce processus d’appariement apparemment simple prendrait des jours à accomplir. Les utilisateurs doivent d’abord extraire les données de la source de données, qui peut être un CRM, un ERP ou un entrepôt de données. Les données sont ensuite transmises aux utilisateurs professionnels sous la forme de feuilles de calcul et c’est là que le vrai travail commence. Les utilisateurs professionnels devront analyser les données pour détecter les erreurs courantes, valider les informations de chaque colonne, éliminer les fautes de frappe et utiliser des formules Excel pour identifier les champs nuls ou dupliqués. Ce processus est répété pour chaque ensemble de données qui doit être mis en correspondance. Une fois que l’utilisateur est satisfait de la qualité de l’ensemble de données, il lance le processus de mise en correspondance.
Dans les situations où les utilisateurs professionnels ne sont pas impliqués, le rapprochement des données est effectué au moyen de requêtes SQL étendues. L’inconvénient de cette situation est la capacité limitée des utilisateurs professionnels à analyser et à comprendre réellement les données. Et s’ils veulent obtenir des données supplémentaires en termes de sexe et de profession ? Ils devront communiquer ce processus au service informatique et tout le processus fastidieux est révisé ou répété pour obtenir une correspondance.
Défis liés à la correspondance des données pour les adresses
Le rapprochement des données est une fonction nécessaire lorsqu’on travaille avec des données tabulaires, mais ce n’est pas un processus facile.
Parmi les principaux défis auxquels nos clients sont confrontés en matière de rapprochement des données, citons les suivants
- Garantir l’exactitude des données : La plupart des entreprises n’ont pas mis en place de système de nettoyage des données ou bien les gestionnaires de données utilisent des requêtes complexes pour effectuer un nettoyage de base des données. Pourtant, des problèmes tels que l’espacement négatif, les fautes de frappe avec le gros doigt, l’utilisation accidentelle de signes de ponctuation, etc. etc. ne sont pas faciles à détecter. En outre, la normalisation et la standardisation des données d’adresses prennent du temps, d’autant plus qu’elles sont les plus sujettes aux erreurs.

- Collecte de données à partir de sources disparates : Les données ne sont généralement pas facilement disponibles pour le rapprochement. Elles doivent généralement être collectées auprès de plusieurs sources disparates, ce qui rend encore plus difficile la garantie de leur exactitude. Par exemple, de nombreuses entreprises doivent collecter des données auprès de fournisseurs et d’applications tierces à des fins d’analyse, mais comme ces sources de données diffèrent les unes des autres en termes de structure, il peut être difficile de les faire correspondre. Ce problème ne se limite pas aux instances de données externes. Les entreprises qui sont connectées à plusieurs applications ou qui utilisent plusieurs plateformes ont souvent du mal à consolider leurs données à des fins d’analyse ou de renseignement.
- Ne pas mesurer les scores de correspondance des données : Malheureusement, les entreprises ne mesurent généralement pas les scores de concordance des données. Le rapprochement des données pose deux problèmes courants : les faux positifs et les faux négatifs. Les deux sont préjudiciables au temps et aux efforts de l’entreprise.
Par exemple, deux sources de données sont mises en correspondance pour déterminer les adresses en double dans un bloc spécifique. 8 adresses sur 20 correspondent, ce qui indique une duplication ainsi que l’utilisation d’une adresse pour plusieurs personnes (comme les membres d’une famille). Cependant, 4/20 correspondances sont des faux positifs – ce qui signifie que les adresses sont censées correspondre mais qu’elles ne sont pas celles de la même personne. Une valeur manquante, telle qu’un numéro de maison, peut être à l’origine d’une correspondance faussement positive. 6/20 sont des faux négatifs, ce qui signifie que les adresses correspondent et appartiennent bien à la même personne, mais que le système est passé complètement à côté en raison de variables telles qu’un deuxième prénom manquant ou incomplet, ou des codes postaux ZIP manquants, etc.
Dans les deux cas, les équipes devront passer du temps à vérifier et valider manuellement les informations. Les efforts manuels de rapprochement des données d’adresses ne fonctionnent mieux que lorsqu’il n’y a pas d’incohérences dans les données. Mais comme nous le savons, les données, surtout les données modernes, sont tout sauf cohérentes.
La solution – Comment obtenir une correspondance précise des données d’adresses ?
Je pourrais simplement vous dire de vous procurer un outil de rapprochement de données haut de gamme et ce serait la solution à tous vos problèmes (effort manuel, manque de ressources SQL, etc.), mais ce n’est pas ainsi que cela fonctionne.
Il y a un processus complet pour faire correspondre les données d’adresse.
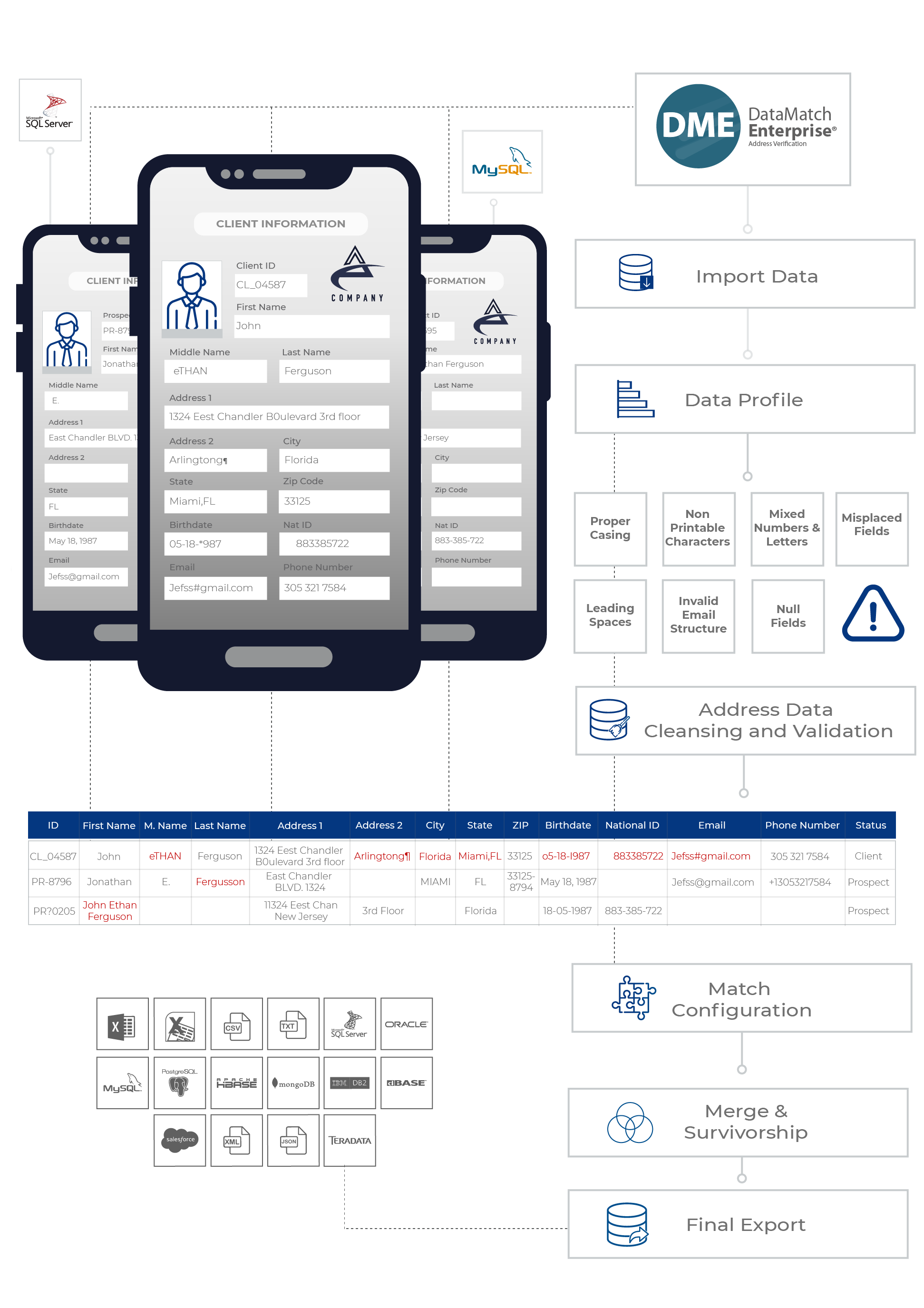
- Intégrer vos sources de données : Si vous collectez des données provenant de plusieurs sources, vous devrez les intégrer dans une plateforme pour lancer l’activité de rapprochement. L’intégration des données n’est cependant pas facile. Vous devrez extraire les données et les transformer dans un fichier CSV ou dans votre base de données. Dans les deux cas, vous devrez préparer les données avant de pouvoir les déplacer.
- Profilage des données : Lorsque vous préparez les données, vous les profilez pour voir si elles contiennent des erreurs, des fautes de frappe ou des valeurs manquantes. Si vous sautez cette étape, votre processus de rapprochement échouera. Vous avez besoin de données précises pour effectuer un rapprochement efficace.
Normalisation et nettoyage des données :
Toutes les villes doivent-elles être écrites comme
NY, NYC ou ny ?
Toutes les adresses devraient-elles avoir un code postal ? Faut-il supprimer les signes – entre les chiffres ? Ce sont tous des cas mineurs qui dégradent la qualité de vos données. Pour réaliser un match efficace, vous devrez nettoyer ces incohérences. C’est un défi en soi. Les scientifiques/analystes de données passent 80 % de leur temps à nettoyer ces données.- Validation des données d’adresse : Et c’est la partie délicate. Saviez-vous que la plupart des adresses que vous avez ne sont probablement même pas valides ? Les gens ont tendance à saisir des adresses incomplètes, incorrectes ou même fausses. Si vous vous lancez dans des activités de mailing sans avoir au préalable validé et vérifié vos données d’adresse, vous perdrez des centaines de milliers de dollars en frais de mailing. C’est pourquoi vous avez besoin d’une solution certifiée CASS (il s’agit d’un fournisseur certifié par l’USPS) pour vous aider à valider les adresses et vous assurer que votre liste d’adresses respecte les directives de l’USPS.
- Enfin, la correspondance : Maintenant que vos données d’adresse sont propres et validées, il est temps de procéder au rapprochement. Si vous utilisez une solution de comparaison de données comme DataMatch Enterprise, le processus est simple et facile. Vous sélectionnez les colonnes que vous voulez faire correspondre – que ce soit entre les sources de données, entre elles ou à l’intérieur de celles-ci, vous ajustez les critères de correspondance et c’est tout ! Vous obtenez des résultats en quelques minutes.
Et maintenant, voici la partie où je vous explique pourquoi vous avez besoin d’une solution de comparaison de données en libre-service telle que DataMatch pour tirer de ce processus. En bref, avec cette solution, vous pouvez :
-
- Gagner du temps, soit près de 80 % des efforts manuels.
-
- Améliorez l’efficacité et laissez votre équipe avoir plus de temps pour analyser les données au lieu de les nettoyer.
-
- Validez votre adresse. Nous sommes une solution certifiée CASS et pouvons valider les adresses des États-Unis, du Canada et du Royaume-Uni.
-
- Effectuez la mise en correspondance des données avec un score de précision élevé. Dans de multiples études et rapports, Data Ladder a devancé SAS et IBM en termes de précision. Nous sommes la seule solution qui offre une correspondance d’une précision de 96 % (au moins). Avec des données complexes, vous aurez besoin d’une solution de rapprochement de données qui renvoie des résultats très précis. Toute valeur inférieure implique un effort manuel accru pour éliminer les faux positifs et négatifs.
C’est ainsi que nous avons aidé plusieurs institutions du gouvernement américain et de l’enseignement public à non seulement faire correspondre les données d’adresses mais aussi à améliorer la qualité globale des données.
Comment Cabarrus Education a économisé des semaines de travail manuel pour faire correspondre les données d’adresse.
Lisez cette étude de cas pour voir comment nous avons aidé un district scolaire à améliorer sa productivité grâce à l’analyse des données, en réduisant le temps de nettoyage des données brutes de deux semaines à seulement
16 heures !



