




























Last Updated on marzo 9, 2022
Los datos de direcciones están semiestructurados, lo que los convierte en uno de los componentes más difíciles de la actividad de cotejo de datos. Durante mucho tiempo, se han utilizado métodos manuales de cotejo de datos que incluían una extensa programación SQL y fórmulas de hojas de cálculo para cotejar las listas de direcciones. Aunque esto puede haber sido viable y efectivo en el pasado, ya no es un método viable para manejar datos complejos de fuentes de terceros.
En esta rápida publicación, cubro los principales desafíos de la comparación manual de datos de direcciones y cómo una solución de autoservicio de punto a clic puede ser lo que su equipo necesita para aumentar la productividad y la eficiencia mientras obtiene resultados precisos.
P.D. En nuestras guías anteriores hemos tratado ampliamente la estandarización y validación de direcciones. Para aquellos que no estén familiarizados con el concepto y el proceso, el siguiente post será enormemente beneficioso para entender este artículo.
Algunas de las cuestiones clave que se tratan en este post son:
- ¿Qué es la concordancia de datos en el proceso de normalización y validación de direcciones?
- ¿Cuáles son las funciones y los componentes que intervienen en el cotejo de datos de direcciones?
- Retos clave de la comparación de datos para los datos de direcciones
- Estudio de caso de Cabarrus
Vamos a profundizar.
¿Qué es la concordancia de datos en el proceso de normalización y validación de direcciones?
Supongamos que tiene dos conjuntos de datos de clientes A y B, en los que el conjunto A representa a los clientes que pertenecen al grupo de edad de 20 a 35 años, mientras que el conjunto B pertenece a 35 a 50 años. La mayoría de las personas de estas listas comparten una dirección exacta (miembros de una misma familia) o similar (miembros de un condominio, por ejemplo). Quiere consolidar las dos listas para poder enviar un solo correo del boletín en lugar de 3 cartas a 3 miembros de la misma familia.
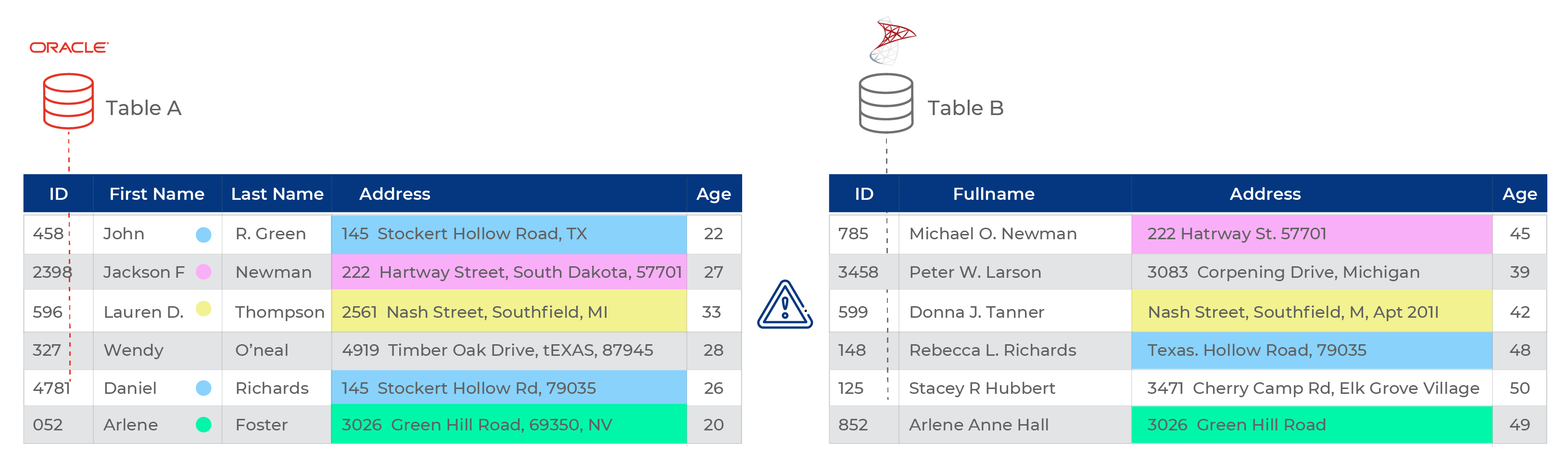
Elcotejo de datos es el proceso que le permite cotejar estos dos conjuntos sobre la base de sus datos de dirección y consolidarlos para obtener una lista final de clientes que comparten la misma dirección.
¿Suena fácil?
¡Sólo si lo fuera!
Por ejemplo, los datos del conjunto A pueden consistir en direcciones similares o exactas dentro de la misma lista. Esto significa que primero tendrá que hacer coincidir los registros dentro del Conjunto A, desduplicar, obtener una lista de registros únicos y guardarla como un nuevo registro. Deberá repetir el mismo proceso con el conjunto B.
A continuación, puede descubrir que varios registros de los nuevos derivados del conjunto A y B son similares. Así que vuelve a ejecutar una coincidencia de datos entre los dos registros para crear un tercer registro que contenga información consolidada del conjunto A y B. Pero, ¿qué pasa con los registros originales? Puede que también tengas que emparejarlos.
El proceso es alucinante y de naturaleza iterativa. Imagina tener que hacer todo esto manualmente.
Este proceso de cotejo, aparentemente sencillo, tardaría días en llevarse a cabo. Los usuarios tendrían que extraer primero los datos de la fuente de datos, que podría ser un CRM, un ERP o un almacén de datos. A continuación, los datos se entregan a los usuarios de la empresa en forma de archivos de hoja de cálculo y es entonces cuando comienza el verdadero trabajo. Los usuarios empresariales tendrían que analizar los datos en busca de errores comunes, validar la información de cada columna, limpiar los errores tipográficos y utilizar fórmulas de Excel para identificar los campos nulos o duplicados. Este proceso se repite para cada conjunto de datos que deba cotejarse. Una vez que el usuario está satisfecho con la calidad del conjunto de datos, comienza el proceso de cotejo.
En las situaciones en las que los usuarios de la empresa no están implicados, el cotejo de datos se realiza mediante amplias consultas SQL. La desventaja de esto es la capacidad limitada de los usuarios de la empresa para analizar y comprender realmente los datos. ¿Y si quieren obtener datos adicionales en términos de género y ocupación? Tendrán que comunicar este proceso a TI y todo el tedioso proceso se revisa o se repite para conseguir una coincidencia.
Desafíos de la concordancia de datos para las direcciones
El cotejo de datos es una función necesaria cuando se trabaja con datos tabulares, pero no es un proceso fácil.
Algunos de los principales retos a los que se enfrentan nuestros clientes con el cotejo de datos son:
- Garantizar la exactitud de los datos: La mayoría de las empresas no disponen de un sistema de limpieza de datos o tienen gestores de datos que utilizan consultas complejas para realizar una limpieza de datos básica. Sin embargo, problemas como el espaciado negativo, las erratas, el uso accidental de los signos de puntuación etc. no son fáciles de detectar. Además, se tarda mucho en normalizar y estandarizar los datos de las direcciones, sobre todo porque son los más propensos a los errores.

- Recogida de datos de fuentes dispares: Los datos no suelen estar disponibles para su cotejo. Por lo general, hay que recopilarla de varias fuentes dispares, lo que hace aún más difícil garantizar su exactitud. Por ejemplo, muchas empresas tienen que recopilar datos de proveedores y aplicaciones de terceros para su análisis, pero como estas fuentes de datos difieren entre sí en cuanto a su estructura, puede ser difícil hacerlas coincidir. Este problema no se limita a los casos de datos externos. Las empresas que están conectadas a varias aplicaciones o utilizan varias plataformas suelen tener dificultades para consolidar sus datos para el análisis o la inteligencia.
- No medir las puntuaciones de coincidencia de datos: Desgraciadamente, las empresas no suelen medir las puntuaciones de coincidencia de datos. Hay dos problemas comunes en la comparación de datos: los falsos positivos y los falsos negativos. Ambas cosas son perjudiciales para el tiempo y el esfuerzo de la empresa.
Por ejemplo, se cotejan dos fuentes de datos para determinar las direcciones duplicadas dentro de un bloque específico. 8 de cada 20 direcciones coinciden, lo que indica una duplicación y el uso de una dirección para varias personas (como los miembros de una familia). Sin embargo, 4/20 coincidencias son falsos positivos, es decir, se predice que las direcciones coinciden pero no son de la misma persona. Un valor que falta, como el número de la casa, puede ser la causa de un falso positivo. 6/20 son falsos negativos, lo que significa que las direcciones sí coinciden y pertenecen a la misma persona, pero el sistema no las ha tenido en cuenta debido a variables como la falta de un segundo nombre o un nombre incompleto, o la falta de códigos postales, etc.
En ambos casos, los equipos tendrán que dedicar tiempo a verificar y validar manualmente la información. Los esfuerzos de cotejo manual de datos de direcciones sólo funcionan mejor cuando no hay incoherencias en los datos. Pero como sabemos, los datos, especialmente los modernos, son cualquier cosa menos consistentes.
La solución – ¿Cómo se obtienen coincidencias precisas de los datos de las direcciones?
Podría decirte simplemente que consigas una herramienta de cotejo de datos de primera línea y eso sería la solución a todos tus problemas (esfuerzo manual, falta de recursos SQL, etc.), pero no es así.
Hay todo un proceso completo para cotejar los datos de las direcciones.
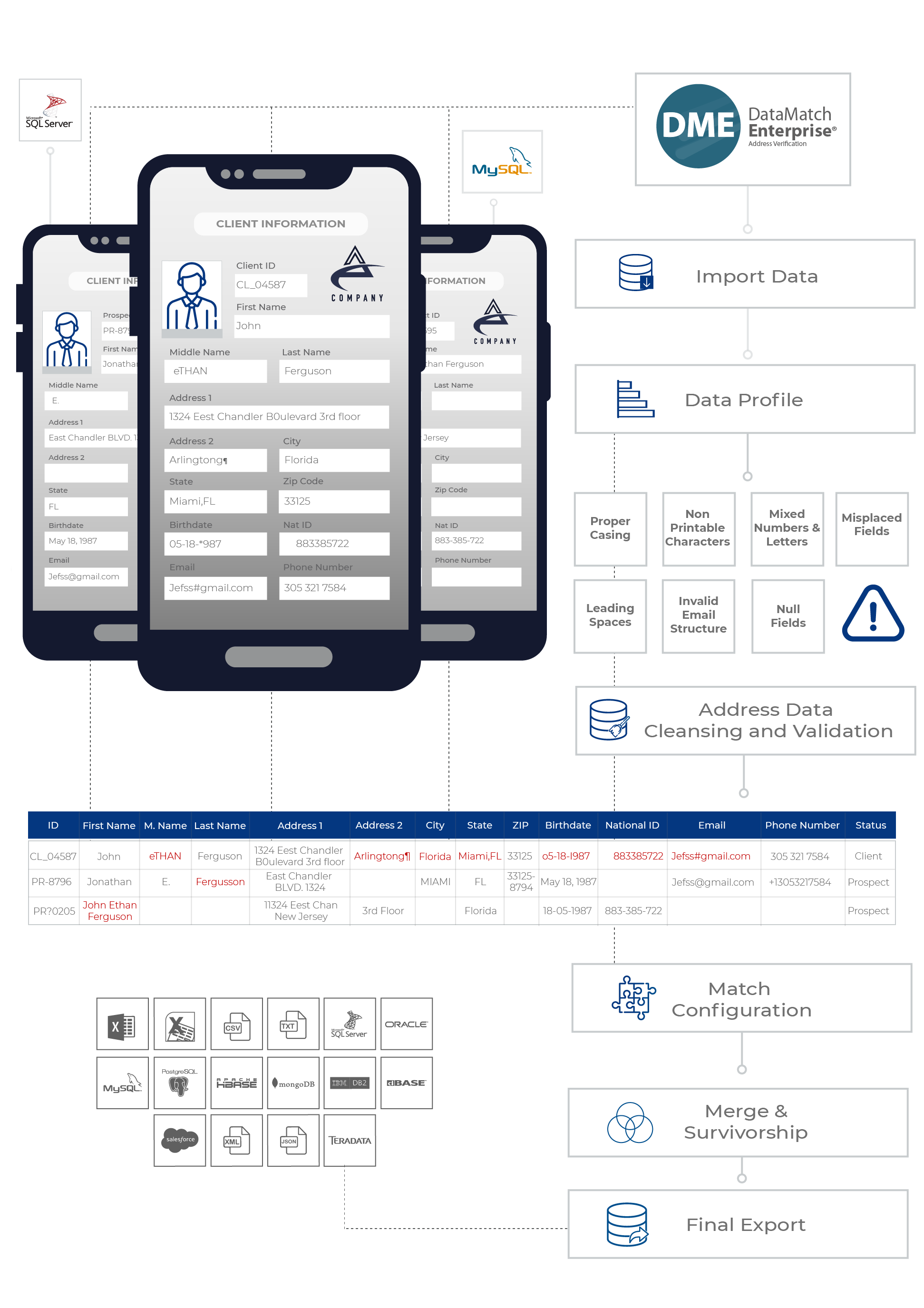
- Integrar sus fuentes de datos: Si está recopilando datos de varias fuentes, tendrá que integrarlos en una plataforma para iniciar la actividad de cotejo. Sin embargo, la integración de datos no es fácil. Tendrás que extraer los datos y transformarlos en un archivo CSV o en tu base de datos. En cualquiera de los casos, tendrás que preparar los datos antes de poder moverlos.
- Perfilar los datos: Cuando se preparan los datos, básicamente se hace un perfil de los mismos para ver si contienen errores, erratas o valores que faltan. Si se salta este paso, el proceso de emparejamiento fallará. Necesita datos precisos para realizar un cotejo eficaz.
Normalización y limpieza de los datos:
¿Deben escribirse todas las ciudades como
NY, NYC o ny?
¿Deben tener todas las direcciones códigos postales? ¿Hay que eliminar las marcas de – entre los números? Todos estos son casos menores que degradan la calidad de sus datos. Para llevar a cabo un partido eficaz, tendrá que limpiar estas incoherencias. Eso es un reto en sí mismo. Los científicos/analistas de datos pasan el 80% de su tiempo limpiando estos datos.- Validación de los datos de la dirección: Y esta es la parte complicada. ¿Sabía que la mayoría de las direcciones que tiene probablemente ni siquiera son válidas? La gente tiende a introducir direcciones incompletas, incorrectas o incluso falsas. Si va a por todas con sus actividades de correo sin validar y verificar primero sus datos de dirección, estará perdiendo cientos de miles de dólares en costes de envío. Por ello, necesita una solución certificada CASS (se trata de un proveedor certificado por USPS) que le ayude con la validación de direcciones y se asegure de que su lista de direcciones sigue las directrices de USPS.
- Por último, el emparejamiento: Ahora que los datos de su dirección están limpios y validados, es el momento de hacerlos coincidir. Si utiliza una solución de correspondencia de datos como DataMatch Enterprise, el proceso es sencillo y fácil. Seleccione las columnas que desea hacer coincidir, ya sea a través, entre o dentro de las fuentes de datos, ajuste los criterios de coincidencia y ¡ya está! Obtendrá resultados en cuestión de minutos.
Y ahora viene la parte en la que te cuento por qué necesitas una solución de autoservicio de correspondencia de datos como DataMatch de este proceso. En pocas palabras, con esta solución puedes:
-
- Ahorro de tiempo que supone casi el 80% del esfuerzo manual
-
- Mejore la eficiencia y deje que su equipo tenga más tiempo para analizar los datos en lugar de limpiarlos
-
- Valide su dirección. Somos una solución certificada por CASS y podemos validar las direcciones de Estados Unidos, Canadá y el Reino Unido.
-
- Realiza el cotejo de datos con una alta puntuación de precisión. En múltiples estudios e informes, Data Ladder superó a SAS e IBM en términos de puntuación de precisión. Somos la única solución que ofrece una coincidencia de precisión del 96% (como mínimo). Con datos complejos, necesitará una solución de cotejo de datos que devuelva resultados muy precisos. Todo lo que sea inferior supondrá un mayor esfuerzo manual para eliminar los falsos positivos y negativos.
-
- Consolide sus datos y cree registros fácilmente. No tienes que estar moviendo los datos de un lado a otro. Compara, fusiona, desduplica y obtén una nueva lista que puedes utilizar y ampliar.
Así es como ayudamos a varias instituciones gubernamentales y de educación pública de Estados Unidos no sólo a cotejar los datos de las direcciones, sino también a mejorar la calidad general de los datos.
Cómo Cabarrus Education ahorró semanas de trabajo manual para cotejar los datos de las direcciones
Lea este estudio de caso para ver cómo ayudamos a un distrito escolar a mejorar la productividad mediante el análisis de datos, reduciendo el tiempo de limpieza de los datos brutos de dos semanas a sólo
16 horas.



