




























Last Updated on marzo 10, 2022
El minorista A realiza sistemáticamente más ventas que el minorista B para el mismo producto, al mismo precio. Ambos minoristas tienen valoraciones de más de 4,5 estrellas con reseñas positivas, pero el minorista B tiene una mayor tasa de rebote en el sitio web y no parece poder convertir su tráfico en clientes. Una observación detallada revela que el sitio de comercio electrónico del minorista A es más elaborado. Dispone de amplia información sobre cada producto. Por ejemplo, el sitio web del minorista A tiene jerarquías y categorías bien definidas que permiten a los usuarios buscar fácilmente sus productos. También cuenta con una completa información de productos con fuertes palabras clave con una categorización más profunda y precisa. El sitio web del minorista B tiene categorías mal definidas, con errores tipográficos, información incompleta y categorías en las que faltan productos. En general, el minorista A tiene los datos de sus productos bajo control, aunque su sitio web no sea tan elegante como el del minorista B.
Según Forrester Research, los sitios de venta al por menor con una estructura mal organizada pueden ver sus
ventas se reducen hasta un 50%
en comparación con los sitios bien estructurados.
El minorista B tiene problemas con la calidad de los datos de los productos y la falta de una taxonomía de productos bien definida. Le recomendamos que lea sobre las taxonomías de los productos aquí.
En este artículo, le explicaremos el marco básico de la calidad de los datos de los productos. Cubrirá puntos importantes como:
- Desafíos con los datos de los productos
- Definir qué es lo que hace que los datos de los productos sean de alta calidad
- La tecnología de aprendizaje automático como solución
- Cómo puede ayudar la correspondencia de productos de Data Ladder
Comencemos.
Desafíos con los datos de los productos que se han encontrado
Los datos de los productos son intrínsecamente datos textuales no estructurados, por lo que no se pueden clasificar o categorizar fácilmente en filas y columnas a menos que se extraiga cada uno de los atributos y se introduzca manualmente en una hoja de cálculo.
Este es un ejemplo de cómo la descripción de un producto se desglosa en atributos y se almacena en tablas que luego se utilizarán para determinar la categoría y la clasificación del producto en un sitio web.
Las múltiples clasificaciones de los atributos garantizan que su producto se pueda buscar y sea visible para un consumidor siempre que escriba un término de búsqueda.
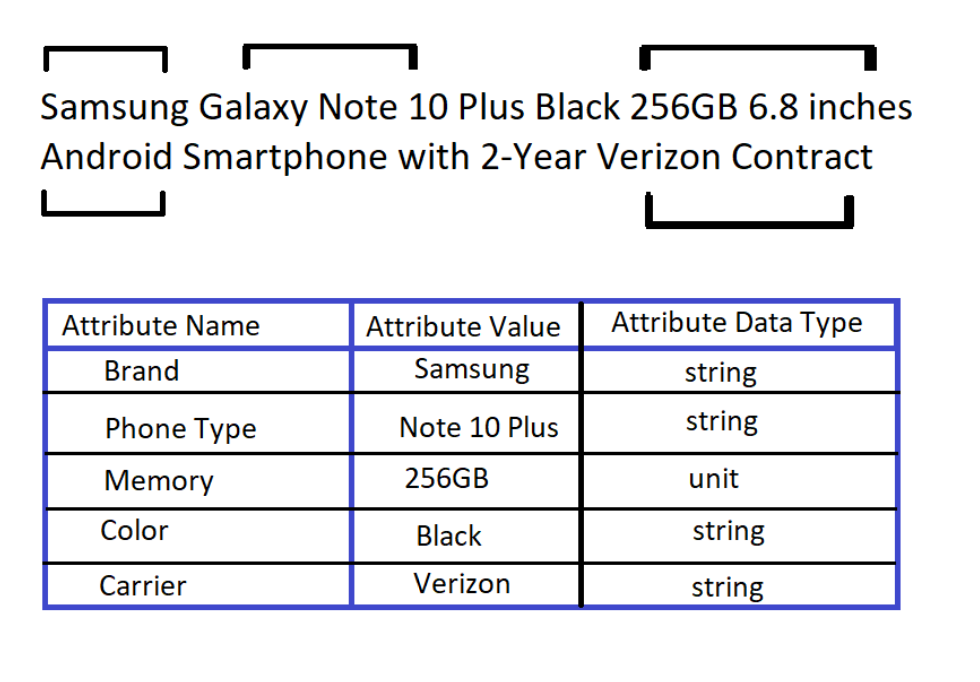
Ahora bien, este era un ejemplo ideal, es decir, no hay ningún fallo estructural, ni errores ortográficos, ni problemas de normalización, ni falta de información.
En circunstancias menos ideales, estos datos pueden estar duplicados varias veces en un inventario de productos. Y lo que es peor, si hay empleados que introducen los datos manualmente, podría terminar con UPNs incorrectos o incompletos. Incluso con el UPN correcto, los datos del producto en sí pueden ser defectuosos. Por ejemplo, Samsung puede escribirse como SMSG en corto o el campo de color puede dejarse en blanco. Los datos deficientes de los productos no sólo afectan a los clientes, sino también a los procesos de backend que implican la gestión de los productos y la elaboración de listas de inventario, sobre todo si se desea cotejar las listas de productos con los vendedores o proveedores.
…¿Pero qué es exactamente un dato de producto bueno o de alta calidad?
¿Cómo se determina lo que es un dato bueno, aceptable o de alta calidad del producto? Existe un punto de referencia común sobre la calidad de los datos que se utiliza ampliamente, sin embargo, ese marco es más adecuado para otras formas de datos, como los datos de los clientes o de las transacciones. Para los datos de los productos, tendrá que utilizar un sistema que incorpore su naturaleza compleja. Lo ideal es que los datos de los productos sean de alta calidad:
- Estructurado:El criterio más importante es convertir los datos no estructurados en datos estructurados. Esto es necesario para poder clasificar los productos en una jerarquía.
- Único: ¿Coca, Coca Cola o Cola? ¿Cuál es? Hay múltiples variaciones en el nombre de un producto, lo que supone un reto importante durante el proceso de agrupación de productos. Será un reto hacer coincidir los datos cuando haya tantas variaciones de un mismo producto.
- Normalizado:SAMSUNG o samsung? ¿GALAXY o GLXY? ¿10 Plus o 10+? Los datos no normalizados deterioran la calidad de los datos y los hacen menos utilizables. A criterios clave para los datos de los productos es su coherencia en términos de formato y estandarización. Si la mitad de su lista de productos tiene «10+» mientras que la otra mitad tiene «10 Plus», le resultará difícil clasificar estos datos. El fallo se trasladará a su sitio web, afectando a los resultados de búsqueda. Si un usuario escribe 10 Plus y usted tiene 10+, su producto simplemente no aparecerá en los resultados de búsqueda.
- Completa con atributos definidos: Los datos de productos con información incompleta de atributos no son utilizables. Es necesario tener atributos bien definidos que luego puedan ser utilizados para crear categorías y jerarquías para el producto, sin las cuales su usuario nunca podrá encontrar el producto que necesita.
- Libre de duplicados: Un duplicado es un producto que aparece más de una vez en el mismo lugar. Se trata de productos distintos, pero con información coincidente. Los duplicados suelen producirse cuando se vuelve a crear un producto que ya existe. Esto ocurre por múltiples razones: durante la introducción de datos o cuando se interconecta con varias cuentas comerciales. Por ejemplo, un producto que proviene de dos vendedores o proveedores diferentes puede aparecer dos veces en la lista de inventario si comparten las mismas especificaciones.
La gestión de su catálogo de comercio electrónico puede convertirse en un reto si los datos de sus productos no están a la altura. Esto es especialmente importante si los datos de sus productos son proporcionados por proveedores que a menudo pueden enviar el contenido en un formato incorrecto o lleno de errores ortográficos. Tendrá que implementar la gobernanza de datos o una solución de calidad de datos del producto para hacer frente a estos desafíos que pueden llevar semanas, si no meses, para que su equipo los limpie.
¿Cómo resolver estos retos y garantizar la limpieza de los datos de los productos?
La mayoría de las empresas resuelven este problema utilizando varios sistemas. Disponen de un sistema de gestión de productos o de un sistema de gestión de inventarios junto con un equipo de expertos en informática que redactan consultas y utilizan identificadores únicos como los números UPC, MPN, GTIN para clasificar los datos. El sistema PMS se utiliza entonces para la identificación de los productos y el seguimiento de los pedidos, las ventas y las entregas. Pero ninguna de estas soluciones puede ayudar con los datos limpios. Además, no pueden utilizarse para cotejar datos ni para construir taxonomías. En el caso de las pequeñas y medianas empresas, se sigue recurriendo a las hojas de cálculo para crear taxonomías, lo que constituye un enfoque ineficiente e ineficaz.
Aquí es donde entra en juego la necesidad de una solución automatizada y basada en el aprendizaje automático.
Cómo afrontar los retos con una solución de calidad de datos basada en el aprendizaje automático
No existe un sistema de clasificación global ni para los datos de los productos, lo que hace aún más difícil para las tiendas de comercio electrónico limpiar, analizar, cotejar y clasificar los datos de sus productos. Aquí es donde entran en juego las soluciones de ML como ProductMatch de Data Ladder. La mayoría de estas soluciones utilizan diccionarios y modelos lineales construidos a partir de conocimientos históricos y modelos predefinidos.
ProductMatch ofrece funciones adicionales, como el uso de algoritmos de concordancia difusa para cotejar conjuntos de datos complejos, al tiempo que permite al usuario limpiar, analizar y normalizar los datos. Pero esto no es todo.
ProductMatch ofrece principalmente la capacidad de extraer atributos de datos no estructurados y llevar al usuario a través de un proceso que implica:
Limpieza de datos:
Limpiar los datos de incoherencias, errores tipográficos y duplicados
Interpretación de los datos:
Transformar estos datos o interpretarlos en información a nivel de atributos para su clasificación y categorización
- Partido: Utilización de algoritmos de concordancia difusa propios y establecidos para cotejar listas de datos para la deduplicación y la agrupación de variaciones. Puede cotejar los datos dentro de sus listas o con las listas integradas de los vendedores y proveedores para asegurarse de que existe una única fuente de verdad para servir eficazmente a la organización.
Estandarizar:
Asegúrese de que sus datos siguen un formato coherente siguiendo una disposición sistemática de las descripciones según los nombres, el modificador, el nombre del proveedor, el número de pieza, la UOM, los atributos, etc.
Con un índice de coincidencia de datos del 80% y un proceso automatizado diseñado tanto para los usuarios de la empresa como para los expertos en TI, la solución le permite ahorrar meses y semanas de esfuerzo manual en la limpieza y la coincidencia de datos. Ah, y también mejora su eficacia operativa. ¡Gana, gana!
¿Qué significa esto para su negocio minorista?
Usted forma parte de un mercado dinámico y competitivo. Cada día que se pierde un cliente por los malos datos del producto es un paso atrás. Para avanzar de verdad y formar parte de la competencia, tendrás que invertir en soluciones que puedan aprovechar potentes tecnologías como la IA y el ML para hacer el trabajo mediocre por ti.
Con una herramienta de calidad de productos como ProductMatch, podrá automatizar una parte importante de su carga de trabajo y eliminar los procesos redundantes entre departamentos.
Y lo que es más importante, podrá realizar una tarea que lleva
1 mes en, literalmente, sólo 1 hora.
La gestión de los datos de sus productos, la creación de taxonomías de productos y la garantía de la calidad de sus datos es un proceso importante, si no redundante, que puede automatizar en lugar de gastar millones de dólares en la contratación de recursos para construir sistemas complejos que requerirán años de pruebas y errores para funcionar, sin garantizar ningún tipo de éxito.
Descubra cómo Data Ladder puede ayudarle a limpiar y clasificar los datos de los productos
Los datos de los productos son diferentes a cualquier otra forma de datos que exista. Necesita una solución que pueda extraer sus datos brutos y desestructurados, analizarlos, limpiarlos y ajustarlos a una taxonomía.
Hable con nosotros y vea cómo podemos ayudarle a utilizar nuestra solución para lograr sus objetivos.



