





























Last Updated on mars 29, 2022
Le détaillant A réalise des ventes constamment plus élevées que le détaillant B pour le même produit, au même prix. Les deux détaillants ont des notes de 4,5+ étoiles et des avis positifs, mais le détaillant B a un taux de rebond plus élevé sur le site Web et ne semble pas pouvoir convertir son trafic en clients. Une observation attentive révèle que le site de commerce électronique du détaillant A est plus élaboré. Il contient des informations détaillées sur chaque produit. Par exemple, le site web du détaillant A possède des hiérarchies et des catégories bien définies qui permettent aux utilisateurs de rechercher facilement leurs produits. Il dispose également d’informations complètes sur les produits, avec des mots-clés forts et une catégorisation plus profonde et plus précise. Le site web du détaillant B présente des catégories mal définies, avec des fautes de frappe, des informations incomplètes et des catégories où il manque des produits. Dans l’ensemble, le détaillant A maîtrise les données relatives à ses produits, même si son site web n’est pas aussi sophistiqué que celui du détaillant B.
Selon Forrester Research, les sites de vente au détail dont la structure est mal organisée peuvent voir leurs
ventes réduites jusqu’à 50
par rapport aux sites bien structurés.
Le détaillant B est aux prises avec la qualité des données sur les produits et l’absence d’une taxonomie de produits bien définie. Nous vous conseillons de vous renseigner sur les taxonomies de produits ici.
Dans cet article, nous allons vous présenter le cadre de base de la qualité des données produit. Il couvrira des points importants comme :
- Défis liés aux données sur les produits
- Définir ce qui constitue des données produit de haute qualité
- La technologie d’apprentissage automatique comme solution
- Comment la correspondance des produits de Data Ladder peut être utile
Commençons.
Les défis liés aux données sur les produits que vous avez rencontrés
Les données relatives aux produits sont par nature des données textuelles non structurées. Elles ne peuvent donc pas être facilement classées ou catégorisées en lignes et colonnes, à moins que chacun des attributs ne soit extrait et saisi manuellement dans une feuille de calcul.
Voici un exemple de la manière dont la description d’un produit est décomposée en attributs et stockée dans des tables qui seront ensuite utilisées pour déterminer la catégorie et la classification du produit sur un site web.
Les multiples classifications d’attributs garantissent que votre produit est consultable et visible pour un consommateur lorsqu’il tape un terme de recherche.
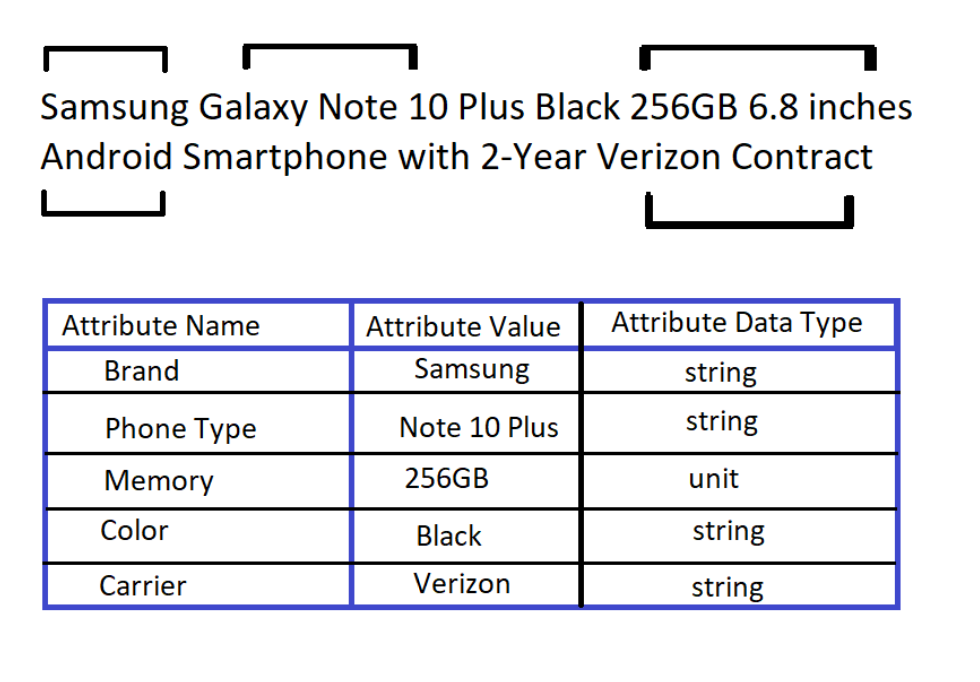
Il s’agit d’un exemple idéal, c’est-à-dire qu’il n’y a pas de défaut structurel, pas de faute d’orthographe, pas de problème de normalisation, pas d’information manquante.
Dans des circonstances moins idéales, ces données peuvent être dupliquées plusieurs fois dans un inventaire de produits. Pire encore, si des commis à la saisie des données entrent manuellement les données, vous risquez de vous retrouver avec des NUP incorrects ou incomplets. Même si l’UPN est correct, les données du produit lui-même peuvent être erronées. Par exemple, Samsung peut être écrit comme SMSG en abrégé ou le champ de la couleur peut être laissé vide. De mauvaises données sur les produits ont un impact non seulement sur les clients, mais aussi sur les processus dorsaux qui impliquent la gestion des produits et la liste des stocks, en particulier si vous voulez faire correspondre des listes de produits avec des vendeurs ou des fournisseurs.
…Mais qu’est-ce qu’une donnée produit de qualité ou de haute qualité ?
Comment déterminer ce que sont des données de produit bonnes, acceptables ou de haute qualité ? Il existe un référentiel commun de qualité des données largement utilisé, mais ce cadre est plus adapté à d’autres formes de données telles que les données clients ou transactionnelles. Pour les données relatives aux produits, vous devrez utiliser un système qui tient compte de leur nature complexe. Idéalement, les données sur les produits doivent être de haute qualité :
- Structuré :Le critère le plus important est la transformation de données non structurées en données structurées. Ceci est nécessaire pour que les produits puissent être classés dans une hiérarchie.
- Unique : Coke, Coca Cola ou Cola ? Lequel est-ce ? Il existe de multiples variantes d’un nom de produit, ce qui pose un problème important lors du processus de regroupement des produits. Ce sera un défi de faire correspondre les données quand il y a autant de variations d’un même produit.
- Normalisé :SAMSUNG ou samsung? GALAXY ou GLXY ? 10 Plus ou 10+ ? Les données non normalisées détériorent la qualité des données et les rendent moins utilisables. A critères clés pour les données relatives aux produits est sa cohérence en termes de format et de normalisation. Si la moitié de votre liste de produits comporte « 10+ » et l’autre moitié « 10 Plus », vous aurez du mal à trier ces données. Ce défaut sera reporté sur votre site web et affectera les résultats de recherche. Si un utilisateur tape 10 Plus et que vous avez 10+, votre produit n’apparaîtra tout simplement pas dans les résultats de recherche.
- Complète avec des attributs définis : Les données relatives aux produits dont les informations sur les attributs sont incomplètes ne sont pas utilisables. Il est nécessaire de disposer d’attributs bien définis qui peuvent ensuite être utilisés pour créer des catégories et des hiérarchies pour le produit, sans quoi votre utilisateur ne sera jamais en mesure de trouver le produit qu’il recherche.
- Sans doublons : Un duplicata est un produit qui apparaît plus d’une fois au même endroit. Il s’agit de produits distincts, mais avec des informations correspondantes. Les doublons sont généralement causés lorsqu’un produit qui existe déjà est créé à nouveau. Cela se produit pour de multiples raisons – lors de la saisie des données ou lorsqu’on est interconnecté avec plusieurs comptes marchands. Par exemple, un produit provenant de deux vendeurs ou fournisseurs différents peut figurer deux fois dans la liste d’inventaire s’il a les mêmes caractéristiques.
La gestion de votre catalogue de commerce électronique peut devenir un véritable défi si les données relatives à vos produits ne sont pas à la hauteur. Cela est particulièrement important si les données relatives à vos produits sont fournies par des fournisseurs qui soumettent souvent le contenu dans un format incorrect ou avec des fautes d’orthographe. Vous devrez mettre en place une gouvernance des données ou une solution de qualité des données produit pour faire face à ces défis qui peuvent prendre des semaines, voire des mois, à votre équipe pour faire le ménage.
Comment résoudre ces problèmes et garantir des données de produits propres ?
La plupart des entreprises résolvent ce problème en faisant appel à plusieurs systèmes. Ils disposent d’un système de gestion des produits ou d’un système de gestion des stocks ainsi que d’une équipe d’experts en informatique qui rédigent des requêtes et utilisent des identifiants uniques tels que les numéros UPC, MPN, GTIN pour classer les données. Le système PMS est ensuite utilisé pour l’identification des produits et le suivi des commandes, des ventes et des livraisons. Mais ni l’une ni l’autre de ces solutions ne peut aider à obtenir des données propres. En outre, ils ne peuvent pas être utilisés pour faire correspondre des données ou pour construire des taxonomies. Pour les petites et moyennes entreprises, on s’appuie encore sur des feuilles de calcul pour créer des taxonomies, ce qui constitue une approche inefficace et inefficiente.
C’est là qu’intervient la nécessité d’une solution automatisée, basée sur l’apprentissage automatique.
Relever les défis avec une solution de qualité des données basée sur l’apprentissage machine
Il n’existe pas de système de classification global pour les données relatives aux produits, ce qui rend d’autant plus difficile pour les magasins de commerce électronique de nettoyer, d’analyser, de faire correspondre et de classer leurs données relatives aux produits. C’est là qu’interviennent les solutions basées sur le ML, comme ProductMatch de Data Ladder. La plupart de ces solutions utilisent des dictionnaires et des modèles linéaires basés sur des connaissances historiques et des modèles prédéfinis.
ProductMatch offre des capacités supplémentaires telles que l’utilisation d’algorithmes de correspondance floue pour faire correspondre des ensembles de données complexes tout en permettant à l’utilisateur de nettoyer, d’analyser et de normaliser les données. Mais il n’y a pas que cela.
ProductMatch offre principalement la possibilité d’extraire des attributs à partir de données non structurées et d’emmener l’utilisateur à travers un processus qui implique :
Nettoyage des données :
Nettoyage des données pour éliminer les incohérences, les fautes de frappe et les doublons.
- Interprétation des données :
Transformer ces données ou les interpréter en informations au niveau des attributs pour la classification et la catégorisation.
- Match : Utilisation d’algorithmes de correspondance floue exclusifs et établis pour faire correspondre des listes de données en vue de la déduplication et du regroupement des variations. Vous pouvez faire correspondre les données au sein de vos listes ou avec des listes intégrées provenant de vendeurs et de fournisseurs afin de vous assurer qu’il existe réellement une source unique de vérité pour servir efficacement l’organisation.
Standardisez :
Assurez-vous que vos données suivent un format cohérent en suivant une disposition systématique des descriptions selon les noms, le modificateur, le nom du fournisseur, le numéro de pièce, l’UOM, les attributs, etc.
Avec un taux de concordance des données de 80 % et un processus automatisé conçu pour les utilisateurs professionnels comme pour les experts en informatique, la solution vous permet d’économiser des mois et des semaines d’efforts manuels dans le nettoyage et la concordance des données. Oh, et cela améliore également votre efficacité opérationnelle. Gagnant, gagnant !
Ce que cela signifie pour votre commerce de détail ?
Vous faites partie d’un marché dynamique et concurrentiel. Chaque jour où vous perdez un client à cause de mauvaises données sur les produits est un pas en arrière. Pour vraiment progresser et faire partie de la concurrence, vous devrez investir dans des solutions capables de tirer parti de technologies puissantes comme l’IA et le ML pour faire le travail médiocre à votre place.
En utilisant un outil de qualité des produits comme ProductMatch, vous serez en mesure d’automatiser une part importante de votre charge de travail et d’éliminer les processus redondants entre les départements.
Plus important encore, vous serez en mesure d’accomplir une tâche qui prend
1 mois en littéralement 1 heure seulement.
Gérer les données relatives à vos produits, créer des taxonomies de produits et garantir la qualité de vos données est un processus important, voire redondant, que vous pouvez automatiser au lieu de dépenser des millions de dollars en embauchant des ressources pour construire des systèmes complexes qui nécessiteront des années d’essais et d’erreurs pour fonctionner – sans garantir aucune forme de succès.
Découvrez comment Data Ladder peut vous aider à nettoyer et à classer les données sur les produits.
Les données sur les produits sont différentes de toutes les autres formes de données. Vous avez besoin d’une solution capable d’extraire simplement vos données brutes et non structurées, de les analyser, de les nettoyer et de les intégrer dans une taxonomie.
Parlez-nous et voyez comment nous pouvons vous aider à utiliser notre solution pour atteindre vos objectifs.



