































Last Updated on December 26, 2025
Retailer A makes consistently higher sales than Retailer B for the same product, at the same price. Both retailers have 4.5+ star ratings with positive reviews, but Retailer B has a higher bounce rate on the website and can’t seem to convert their traffic into customers. A close observation reveals that Retailer A’s e-commerce site is more elaborate. It has extensive information on each product. For instance, Retailer A’s website has well-defined hierarchies and categories that enable users to easily search for their products. It also has complete product information with strong keywords with categorization that is deeper and more precise. Retailer B’s website has poorly defined categories, with typos, incomplete information and categories with missing products. Overall, Retailer A has their product data in control even though their website is not as fancy as Retailer B’s.
According to Forrester Research, retail sites with a wrongly organized structure can see their sales reduced to 50% compared to well-structured sites.
Retailer B is struggling with product data quality and the lack of a well-defined product taxonomy. We recommend reading about product taxonomies here.
In this post, we’ll run you through the basic framework of product data quality. It will cover important pointers like:
- Challenges with product data
- Defining what makes high-quality product data
- Machine Learning technology as a solution
- How Data Ladder’s Product Match Can be of Help
Let’s begin.
Challenges with Product Data that You’ve Come Across
Product data is inherently unstructured, textual data, therefore, it cannot easily be classified or categorized into rows and columns unless each of the attributes is extracted and manually entered into a spreadsheet.
Here’s an example of how a product description is broken down into attributes and stored in tables which will later be used to determine the category and classification of the product on a website.
The multiple classifications of attributes ensure that your product is searchable and visible to a consumer whenever they type in a search term.
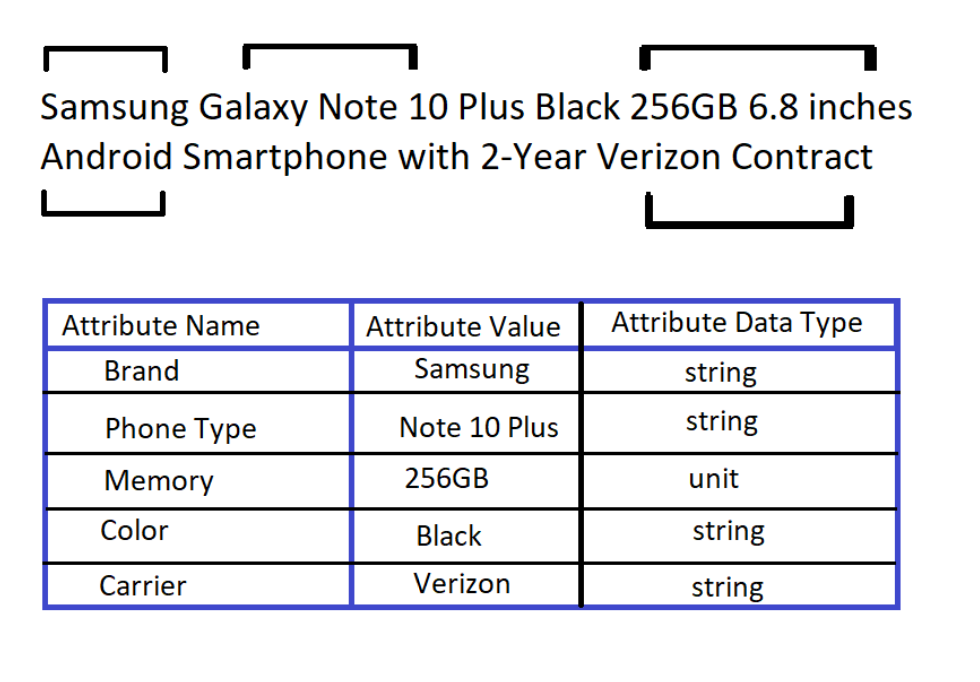
Now, this was an ideal example – meaning, there is no structural flaw here, no spelling mistakes, no standardization issues, no missing information.
In less ideal circumstances, this data may be duplicated multiple times in a product inventory. Worse, if there are data entry clerks manually keying in data, you could end up with incorrect or incomplete UPNs. Even with the correct UPN, the product data itself may be flawed. For instance, Samsung may be written as SMSG in short or the color field may be left blank. Poor product data not only impacts customers but also backend processes that involve product management and inventory listing, especially if you want to match product lists with vendors or suppliers.
…But What Exactly is Good or High-Quality Product Data?
How do you determine what is good, acceptable, or high-quality product data? There’s a common data quality benchmark used widely, however, that framework is more suited to other forms of data such as customer or transactional data. For product data, you will need to use a system that incorporates its complex nature. Ideally, high-quality product data should be:
- Structured:The most important criterion is turning unstructured data into structured data. This is necessary so that products can be classified into a hierarchy.
- Unique: Coke, Coca Cola or Cola? Which one is it? There are multiple variations to a product name which causes a significant challenge during the product grouping process. It will be a challenge to match data when there are so many variations of one product.
- Normalized:SAMSUNG or samsung? GALAXY or GLXY? 10 Plus or 10+? Non-normalized data deteriorates data quality and makes it less usable. A key criteria for product data is its consistency in terms of format and standardization. If half your product list has ‘10+’ while the other half has ‘10 Plus’, you’ll have a hard time sorting this data. The flaw will be carried forward onto your website, affecting search results. If a user types 10 Plus and you’ve got 10+, your product simply won’t appear in search results.
- Complete with Defined Attributes: Product data with incomplete attribute information is not usable. It’s necessary to have well-defined attributes that can later be used to create categories and hierarchies for the product, without which your user will never be able to find their required product.
- Free of Duplicates: A duplicate is a product that appears more than once in the same location. These are separate products, but with matching information. Duplicates are usually caused when a product that already exists is created again. This happens for multiple reasons – during data entry or when interconnected with multiple merchant accounts. For instance, a product that comes from two different vendors or suppliers may be listed twice in the inventory list if they share the same specs.
Managing your e-commerce catalog can become challenging if your product data is not up to the mark. This is especially important if your product data is provided by suppliers who may often submit content in the wrong format or rife with spelling errors. You will need to implement data governance or a product data quality solution to deal with these challenges which can take weeks, if not months for your team to clean up.
How Do You Resolve these Challenges and Ensure Clean Product Data?
Most companies resolve this problem by making use of multiple systems. They have a product management system or an inventory management system in place along with a team of IT experts who write queries and use unique identifiers such as UPC, MPN, GTIN numbers to classify data. The PMS system is then used for product identification and tracking of orders, sales, and deliveries. But neither of these solutions can help with clean data. Furthermore, they cannot be used to match data or to build taxonomies. For small and mid-level businesses, there is still a reliance on spreadsheets to create taxonomies which is an inefficient and ineffective approach.
This is where the need for an automated, machine learning-enabled solution comes in.
Facing Challenges with a Machine Learning Enabled Data Quality Solution
There is no global classification system or for product data, which makes it all the more challenging for e-commerce stores to clean, parse, match, and classify their product data. This is where ML-enabled solutions like Data Ladder’s ProductMatch come into play. Most of these solutions make use of dictionaries and linear models built on historical knowledge and pre-defined models.
ProductMatch offers additional capabilities such as the use of fuzzy matching algorithms to match complex data sets while allowing the user to clean, parse, and standardize data. But this is not all there is.
ProductMatch primarily offers the ability to extract attributes from unstructured data and taking the user through a process that involves:
- Data cleansing: Cleaning the data of inconsistencies, typos, duplicates
- Interpreting of data: Transforming this data or interpreting it into attribute-level information for classification and categorization
- Match: Using proprietary and established fuzzy matching algorithms to match data lists for deduplication and grouping of variations. You can match data within your lists or with integrated lists from vendors and suppliers to assure that a single source of truth truly exists to effectively serve the organization.
- Standardize: Ensure your data follows a consistent format by following a systematic arrangement of descriptions according to nouns, modifier, vendor name, part number, UOM, attributes etc.
With a data match rate accuracy at 80% and an automated process that is designed for business users and IT experts alike, the solution lets you save months and weeks of manual effort in data cleansing and data matching. Oh, and it also improves your operational efficiency. Win, win!
What this Means for Your Retail Business?
You’re part of a dynamic and competitive market. Every day you lose a customer to poor product data is a step backward. To truly move ahead and be part of the competition, you will need to invest in solutions that can leverage powerful technologies like AI and ML to do the mediocre work for you.
Using a product quality tool like ProductMatch, you will be able to automate a significant proportion of your workload and eliminate redundant processes between departments.
Most importantly, you’ll be able to accomplish a task that takes 1 month in literally just 1 hour. Managing your product data, creating product taxonomies and ensuring the quality of your data is an important, if not a redundant process that you can automate instead of spending millions of dollars in hiring resources to build complex systems that will require years of trials and error to work – without guaranteeing any form of success.
Learn How Data Ladder Can Help You Clean and Classify Product Data
Product data is a different ball game than any other data form out there. You need a solution that can simply pull in your raw, unstructured data, parse it, clean it and fit it into a taxonomy.
Speak to us and see how we can help you use our solution to accomplish your goals.

