






Ingestion
Rassemblez les données en un seul endroit, car elles sont dispersées dans des sources disparates, et résolvez tout changement conflictuel dans les schémas de base de données pour permettre un traitement ultérieur.

Normalisation des données
Résoudre les problèmes de normalisation des données mis en évidence à l'étape précédente, notamment le remplissage de données vides, le remplacement d'informations inexactes ou invalides, la normalisation des valeurs par rapport aux modèles et formats définis, etc.


Découverte de données
Découvrir et mettre en évidence toute anomalie statistique pouvant être présente sous la forme de valeurs de données manquantes, incomplètes ou invalides.

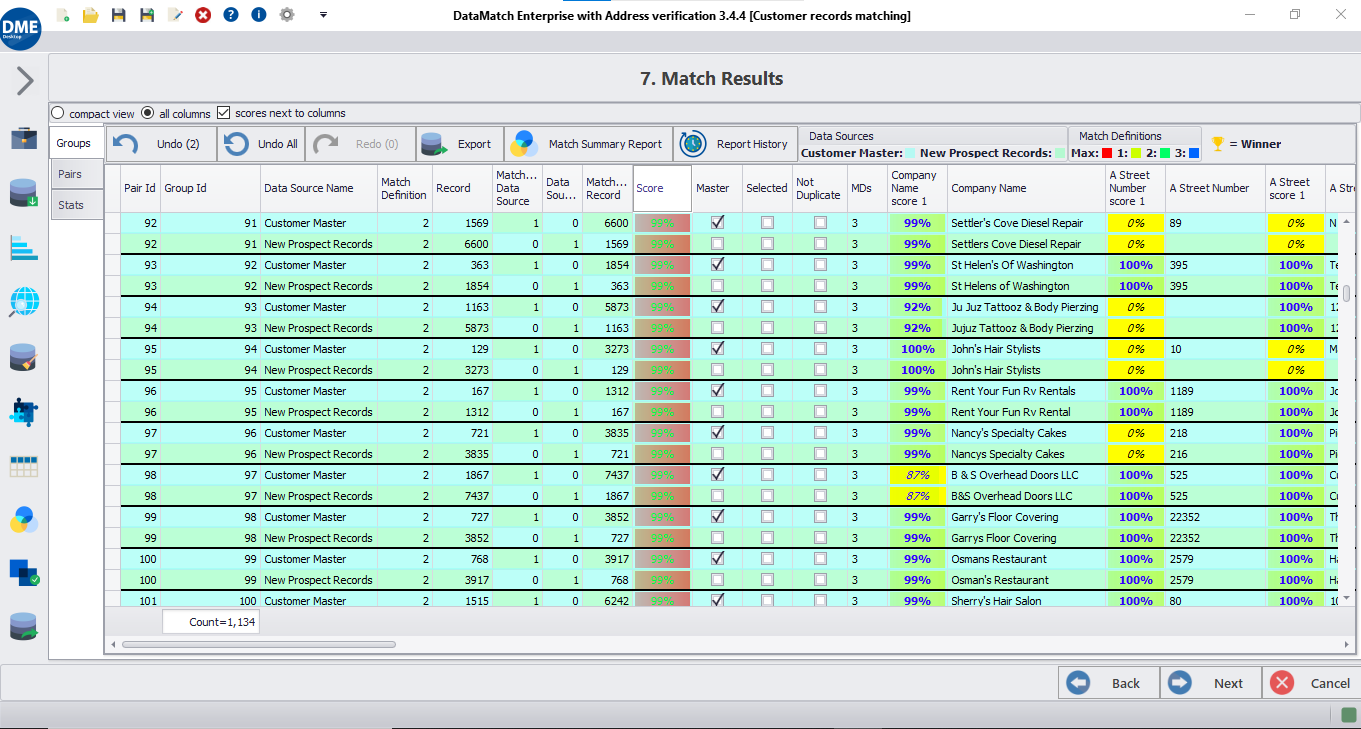
Liaison d'enregistrements d'entité
Faites correspondre les enregistrements dans et entre les bases de données et identifiez les enregistrements potentiels liés à la même entité. Les ensembles de données manquent généralement d'attributs d'identification unique standardisés, et une combinaison d' algorithmes de correspondance floue intelligents peut donc être nécessaire pour augmenter la précision.