





























Last Updated on mars 22, 2022
Dans ce blog, nous allons discuter de ce qu’est le couplage de données et des avantages suivants qui aident les entreprises à améliorer la veille économique et à avoir un impact direct et significatif sur les résultats :
- Créer des enregistrements « en or » pour une utilisation en aval
- Travaillez avec des données propres et fiables
- Préparer les données pour la Business Intelligence
- Augmenter la précision des données
- Enrichir les données pour approfondir les connaissances
- Affiner la segmentation de la clientèle
- Assurer une meilleure conformité
- Automatiser la prévention des fraudes
Qu’est-ce que la comparaison de données ?
Le rapprochement des données – également connu sous le nom de couplage d’enregistrements et de résolution d’entités – est la tâche qui consiste à identifier et à attribuer deux enregistrements apparemment différents comme étant un seul et même enregistrement dans plusieurs sources de données.
En trouvant des correspondances plus précises, les organisations peuvent plus facilement identifier les enregistrements en double et choisir de les fusionner. Sélectionnez une fiche et écartez les autres fiches identiques. Identifiez également les correspondances possibles qui sont en fait des entités différentes.
Pour cette raison, le rapprochement des données est considéré comme la fonction la plus importante après les activités de profilage, de nettoyage et de normalisation.
De cette façon, le rapprochement des données permet aux organisations d’avoir une vue plus complète de chaque entité. Client, étudiant, patient, etc. – en éliminant les valeurs en double et en s’assurant que les données résidant dans leurs systèmes d’information sont propres et exactes.
Comment fonctionne la comparaison des données ?
Lerapprochement des données s’appuie sur plusieurs algorithmes pour analyser les enregistrements et trouver des correspondances avec des entrées similaires. Cependant, l’approche exacte de l’appariement des données varie selon que l’appariement est déterministe ou probabiliste.
Dans la correspondance déterministe, les correspondances sont identifiées en fonction de l’exactitude de deux ou plusieurs entrées ; sur une base de 0 ou 1. Les algorithmes utilisent des règles et des modèles définis pour déterminer les scores permettant d’établir une correspondance.
La correspondance probabiliste, quant à elle, identifie les correspondances sur la base d’un score de correspondance supérieur à un certain seuil compris entre 0 et 1.
Les algorithmes de logique floue, tels que Jaro-Wrinkler, déterminent les probabilités sur la base d’associations et de pondérations de données d’identification uniques (valeurs qui ne changent pas au fil du temps. Comme le numéro de sécurité sociale et la date de naissance). Et d’identifier dans quelle mesure un enregistrement particulier correspond à d’autres enregistrements.
Comment la comparaison des données est-elle appliquée dans différents secteurs ?
Bien que le résultat du rapprochement des données soit de trouver des enregistrements plus précis et uniques parmi plusieurs enregistrements similaires. L’application diffère d’un secteur à l’autre. Voici un aperçu de la manière dont le rapprochement des données est appliqué dans de multiples contextes :
- Gouvernement et secteur public : les agences fédérales et les institutions publiques s’appuient sur la résolution des entités en examinant les données PII telles que le SSN, le passeport et les numéros de licence pour détecter les fraudes et respecter les normes de conformité. Et effectuer des analyses politiques.
Le ministère de la justice (DOJ), qui traite plusieurs milliers de demandes de FOIA, en est un exemple. Chacune d’entre elles doit être correctement interprétée et communiquée au demandeur. Et des recherches approfondies.
Grâce au rapprochement des données, l’agence a pu identifier les doublons et réduire un champ de 4 millions à 3 millions d’enregistrements. Qui ont été encore réduits à 4 000 enregistrements après filtrage. L’ensemble de l’activité de déduplication n’a duré que quatre heures, ce qui aurait pris plusieurs semaines si elle avait été effectuée manuellement. - Éducation : rapprochement de données provenant de sources disparates, telles que les données démographiques des élèves et des enseignants, et d’autres sources, afin de mesurer les performances des élèves. Distinguer les méthodes d’enseignement réussies de celles qui ne le sont pas, analyser les changements de notes. Et identifier les initiatives politiques à partir des données SLDS.
Un État a mené un programme de couplage d’enregistrements avec un échantillon et a évalué le nombre d’étudiants qui, au cours d’une année, ont suivi des études postsecondaires dans une ville donnée. Avec l’ancien programme existant, l’échantillon a révélé que 22 % des 5 344 étudiants de cette ville avaient poursuivi des études supérieures.
Après la solution de rapprochement des données de Data Ladder, ce chiffre est passé à près de 41 %. Près du double du premier chiffre. Pour plus d’informations, lisez l’étude de cas SLDS.
- Banque et finance : les banques et les institutions de services financiers utilisent le rapprochement de données pour identifier les coupables dans le cadre d’initiatives de lutte contre le blanchiment d’argent, pour répondre aux exigences de conformité KYC ou pour effectuer des évaluations de crédit FICO.
Bell Bank a effectué un rapprochement de données à l’aide de DataMatch Enterprise afin d’obtenir une vue unique et consolidée de ses clients et fournisseurs répartis sur plusieurs lignes de services. De la retraite à la gestion du patrimoine.
Grâce au matching, Bell Bank a pu trouver et suivre le parcours de chaque client à travers les différents services bancaires et réduire les coûts opérationnels. Pour plus d’informations, lisez l’étude de cas de Bell Bank.
- Soins de santé : les organismes de soins de santé utilisent la mise en correspondance des patients dans plusieurs dossiers de DSE et bases de données via des identifiants uniques tels que ONC, USPS et CAQH pour une vue unique du patient afin de déterminer le bon diagnostic et de corriger les prescriptions de médicaments.
St. John Associates a utilisé le nettoyage et la mise en correspondance des données pour augmenter la déduplication des enregistrements des candidats au recrutement. Cela leur permet d’économiser des centaines d’heures consacrées au nettoyage et à la comparaison des dossiers. Cliquez ici pour plus d’informations.
- Ventes et marketing : les entreprises ont souvent besoin de trouver des correspondances pour supprimer les contacts dupliqués et erronés dans les bases de données CRM et relationnelles. La vue unique du client qui en résulte permet aux entreprises d’améliorer les activités de vente incitative et de vente croisée, ainsi que les campagnes de marketing omni-canal. Et augmenter le retour sur investissement du marketing.
TurnKey Auto Events – une société de services marketing pour les concessionnaires automobiles – cherchait à rapprocher les ventes des partenaires de la concession avec les pistes des clients pour obtenir un crédit de vente.
Grâce à DataMatch Enterprise, ils ont fait correspondre des enregistrements provenant de diverses sources pour créer une vue consolidée et unique des ventes potentielles de voitures. Et en un minimum de temps, supprimez les doublons et les enregistrements nettoyés au cours du processus. Pour plus d’informations, lisez l’étude de cas TurnKey Auto Events.
Avantages de la comparaison des données
Le fait de disposer d’un outil robuste de rapprochement des données dans le cadre de votre gestion de la qualité des données peut présenter un large éventail d’avantages, tels que :
1. Créer des enregistrements « en or » pour une utilisation en aval

Rapprochement et nettoyage des données permet d’identifier, de faire correspondre et de fusionner les enregistrements stockés dans les systèmes d’information, de consolider les données et de créer une vue unique du client. Certains champs de données, comme le nom, le numéro de téléphone, l’adresse, etc., sont les mêmes dans la plupart des applications. Certains systèmes utilisent des technologies de suivi pour fournir des informations plus approfondies sur les clients.
Par exemple, les données recueillies par des outils d’automatisation du marketing comme Hubspot et Marketo sont généralement complètes. Fournir un historique complet de la manière dont un client potentiel a interagi avec votre entreprise sur Internet.
En revanche, si le même client se rend en personne dans le point de vente de l’entreprise. La quantité de données recueillies par le représentant et saisies dans le système CRM comprend moins de détails. Cela aussi avec un risque de divergence des informations dû à une erreur humaine.
Grâce au rapprochement des données, les entreprises peuvent disposer d’une source unique de vérité – les données disponibles dans différentes bases de données et ensembles de données seront comptées et consolidées. Et fusionnés pour former un enregistrement de données de base ou enregistrement « doré », contenant toutes les informations dont vous disposez sur un prospect, un client ou une piste particulière.
Avec une vue complète du client, vous pouvez mieux aligner vos stratégies de marketing et de vente. Avoir accès à des informations concrètes pour les rapports et les analyses. Et, en fin de compte, prendre des décisions commerciales bien fondées pour un meilleur retour sur investissement et une meilleure croissance de l’entreprise.
2. Travaillez avec des données propres et fiables
Les entreprises utilisent un vaste réseau de systèmes d’information et d’applications qui sont étroitement liés pour former l’infrastructure de données interne.
Les données sur les consommateurs étant collectées à partir de divers canaux de communication. Il existe un risque élevé de divergence entre les informations saisies par différents moyens.
Considérons un prospect, James O’Quinn, qui vit en Caroline du Nord et travaille chez Fiserv. Il clique sur l’une de vos annonces Google et visite une page de renvoi proposant un livre blanc. Il remplit le formulaire de contact avec les détails suivants :
| Nom | Courriel | Numéro de téléphone | Localisation |
| James O’Quinn | j.oquinn@fiserv.com | +184 222 483 | Caroline du Nord |
Ces informations sont stockées dans votre base de données CRM. Après avoir lu le livre blanc. Jacques décide de s’inscrire à votre lettre d’information mensuelle. Pour cela, il doit remplir un formulaire de contact distinct sur votre site web. Sous cette forme. Il saisit son adresse électronique personnelle plutôt que celle de son entreprise.
| Nom | Courriel | Numéro de téléphone | Localisation |
| James Quinn | jim.oq@gmail.com | +184 222 483 | N. Carolina |
Un nouvel enregistrement est créé dans votre CRM, indiquant que James est un nouveau prospect, car le nom et l’adresse électronique sont différents cette fois-ci.
Quelques semaines plus tard, James visite un salon professionnel et interagit avec votre entreprise. Il s’engage avec votre représentant et prend des informations sur les solutions que vous proposez. Il se montre intéressé et fournit à votre représentant les coordonnées de son entreprise. Votre représentant enregistre les informations suivantes :
| Nom | Courriel | Numéro de téléphone | Localisation |
| Jim Quinn | j.oquinn@fiser.com | +184 222 2482 | Caroline du Nord |
Voici un aperçu compilé de toutes les informations que James a fournies au cours de ses différentes interactions avec votre entreprise :
| Interaction | Nom | Courriel | Numéro de téléphone | Localisation |
| Inscription au livre blanc | James O’Quinn | j.oquinn@fiserv.com | +184 222 483 | Caroline du Nord |
| Inscription à la newsletter | James Quinn | james.oq@gmail.com | +184 222 483 | N. Carolina |
| Tradeshow | Jim Quinn | j.oquinn@fiserv.com | +184 222 2482 | Caroline du Nord |
Les variations dans les informations sont assez évidentes. Il existe maintenant trois enregistrements qui désignent la même entité, dans différents systèmes de l’organisation.
Le fait d’avoir plusieurs enregistrements pour une même personne peut entraîner plusieurs problèmes. Par exemple, l’envoi d’un même courriel plusieurs fois, et ce, avec une mauvaise orthographe du nom. Ce qui peut avoir un impact significatif sur l’expérience du client avant même qu’il ne se transforme en prospect potentiel.
Ce n’est qu’un exemple parmi les centaines de scénarios dans lesquels les enregistrements en double peuvent affecter votre entreprise.
C’est là que nettoyage des données et la déduplication entrent en jeu. Les outils de comparaison de données comme DataMatch Enterprise s’appuient sur la meilleure technologie de comparaison floue de sa catégorie. Pour identifier les enregistrements en double dispersés dans vos différents référentiels de données.
Attribuer des notes au degré de correspondance trouvé afin d’éviter les faux positifs.
La solution permet également d’établir le profil de vos données en quelques minutes afin de connaître les problèmes qui existent dans les données de l’entreprise, de les résoudre à l’aide de nos options de normalisation et de nettoyage, puis de les faire correspondre pour éliminer les doublons.
En plus d’améliorer l’expérience client, la déduplication réduit le nombre d’enregistrements dans une base de données. Cela permet de réduire la consommation d’espace et de diminuer la charge sur le client et le serveur lorsqu’une application appelle les données pour les traiter.
3. Préparer les données pour la Business Intelligence
Avant que les données puissent être utilisées pour un processus ou une application quelconque, on parle de prétraitement des données. Une étape importante de l’apprentissage automatique.
Il doit être préparé pour répondre aux exigences de cette opération particulière. Pour avoir une idée de l’importance de la préparation des données. Environ 22 000 dollars par analyste de données et par an sont dépensés pour préparer les données de l’entreprise à des fins de reporting et d’analyse.
Un projet typique d’analyse et d’apprentissage automatique implique l’utilisation de données provenant d’environ 6 sources ou plus . En raison de la disparité des formats de données entre les bases de données, il suffit de préparer les données – les nettoyer et les normaliser.
L‘analyse des données à des fins de veille stratégique représente 80 % du temps total consacré au processus, et seulement 20 % du temps consacré à l’analyse proprement dite.
Pour alléger la charge et réduire la dépendance à l’égard des ressources informatiques, les outils de rapprochement des données offrent de solides capacités de préparation des données en libre-service. S’assurer que chaque ensemble de données est constitué du même type de données.
Les outils de rapprochement des données automatisent le processus de filtrage des données brutes à travers plusieurs couches, en les profilant, en les nettoyant, en les dédupliquant et en les fusionnant pour obtenir des informations précises grâce à l’analyse.
Avec DataMatch Enterprise, vous pouvez normaliser et nettoyer des centaines de millions d’enregistrements dans et entre les sources de données afin de les normaliser. Convertissez les notations (numéro de maison, numéro de maison, numéro de maison en numéro de maison) en ce que votre système reconnaît, changez la casse, supprimez des caractères ou des mots spécifiques, fusionnez des champs, et des centaines d’autres choses.
Il s’agit également de convertir les données numériques, comme les numéros de téléphone, dans le format désigné.Et le même schéma est suivi pour le reste des champs.
Une fois ces étapes terminées, vous pouvez soumettre vos données au processus de rapprochement/dédoublonnage. Vous pouvez aussi les exporter vers votre entrepôt de données pour la création de rapports analytiques et d’autres analyses.
La préparation des données par le biais du rapprochement garantit que vos données ont une structure appropriée. Et il est prêt pour que les systèmes de BI puissent prélever des données avec précision et générer des informations de haute qualité.
4. Augmenter la précision des données
Pour réussir, les entreprises doivent utiliser leurs ressources limitées de la manière la plus efficace possible. Cependant, les ressources humaines et financières sont généralement gaspillées en raison de mauvaises décisions fondées sur des enregistrements et des données inexacts.
Grâce à la correspondance des données, les organisations peuvent optimiser les niveaux de précision dans toutes les unités commerciales. Cela permet d’améliorer la productivité de l’équipe et l’efficacité globale. Par exemple, si le département des ventes dispose de données précises sur les prospects..
Lesreprésentants disposeront de meilleures informations pour engager les prospects avec plus de chances de les convertir en clients.
Le rapprochement des données facilite la normalisation . Étant donné que les enregistrements sont stockés dans différents formats, les outils de rapprochement des données permettent de définir une norme..
Wqui peut être mis en œuvre de manière générale. Il est ainsi plus facile de trier les données en fonction de champs spécifiques, ce qui permet aux utilisateurs d’accéder à des données complètes et précises à chaque fois.
5. Enrichir les données pour approfondir les connaissances
Le rapprochement des données permet de tirer parti des avantages de l’enrichissement des données. Ce qui implique la fusion de données provenant de sources tierces faisant autorité avec la base de données interne existante.
L’amélioration de la qualité et de la cohérence des données sur les consommateurs peut permettre aux entreprises de mieux rationaliser leurs processus de marketing, de vente, de production et autres.
Le scoring et le profilage sont généralement les étapes initiales avant toute valorisation des données en aval.
Les coordonnées des consommateurs sont vérifiées, les données douteuses sont signalées. De plus, les informations relatives aux adresses sont normalisées afin que les données inexactes n’affectent pas la veille économique.
L’étape suivante consiste à collecter des informations supplémentaires auprès de ressources externes afin de créer un profil de consommateur plus complet et riche en données.
Les données provenant de sources tierces peuvent inclure des données financières, des intérêts sociaux, des données automobiles et des événements de la vie. Lesquelles peuvent être recueillies sur la base des informations supplémentaires disponibles sur les canaux de communication les plus fiables et les plus privilégiés.
Lesdonnées enrichies comblent toutes les lacunes des données sur les consommateurs, vous fournissant ainsi une fiche de données complète sur le « quoi » et le « comment » de votre public cible. Cela vous permet d’améliorer vos processus commerciaux afin d’améliorer l’expérience globale du client.
6. Affiner la segmentation de la clientèle
Pour toute campagne de marketing et de vente, la segmentation des clients joue un rôle essentiel, en particulier dans les entreprises de big data. En fait, on sait que les campagnes de marketing fondées sur la segmentation de la clientèle enregistrent un taux de réussite moyen de 10 %. Augmentation du retour sur investissement de 760 %.
Les spécialistes du marketing de la génération de la demande ont généralement du mal à définir les limites qui font dérailler les efforts de personnalisation de leurs campagnes de marketing. Le coupable ? Données inexactes et incomplètes.
Offrir une combinaison de capacités d’enrichissement et de vérification des données. Des outils de rapprochement des données vous aident à identifier et à classer votre public cible en fonction de plusieurs facteurs démographiques. Comme le revenu, l’état civil, l’âge, le lieu de résidence, etc.
Disposer d’informations précises et complètes sur les clients vous aide à définir clairement les intérêts, les comportements et autres facteurs socio-économiques pour créer des segments.
AVous pouvez ainsi ajouter une touche de personnalisation à vos messages. Avec le bon type de personnalisation, vous pouvez maximiser l’efficacité de vos campagnes de vente et de marketing en élaborant des messages plus pertinents pour vos clients.
7. Assurer une meilleure conformité
Avec le GDPR, les entreprises doivent réfléchir soigneusement à leurs stratégies de marketing pour les marchés européens. Le rapprochement des données peut jouer un rôle important pour garantir la conformité à cette réglementation.
Avant que les entreprises puissent contacter un client, le GDPR leur impose de demander la permission d’utiliser les adresses électroniques et autres informations personnelles d’un client dans leurs campagnes de marketing.
L’interaction avec les clients étant omnicanale, il devient difficile d’obtenir la permission des clients. Lorsque les données sont incohérentes et varient selon les plateformes en ligne. Ce qui augmente le risque d’encourir des pénalités.
Mais avec le couplage des données, les entreprises peuvent affiner et savoir exactement à quel client elles ont affaire. En leur donnant la possibilité de demander une autorisation explicite.
Lacorrespondance OFAC est un autre cas d’utilisation de la correspondance de données que nous voyons de plus en plus chez Data Ladder. L’Office of Foreign Asset and Control (OFAC), une division du département du Trésor américain. Cela crée des listes noires d’individus et de pays faisant l’objet de sanctions économiques ou commerciales afin de protéger les intérêts fédéraux.
Pour des raisons de conformité, les organisations doivent comparer les listes de fournisseurs, y compris les transactions individuelles, aux listes noires de l’OFAC avant de faire des affaires, sous peine de lourdes sanctions.
Le problème est que vous n’aurez pas toujours des correspondances exactes. Les fournisseurs figurant sur la liste noire peuvent utiliser des pseudonymes, les données peuvent avoir été mal saisies dans votre base de données des fournisseurs.. En d’autres termes, votre logiciel de rapprochement des données peut manquer des correspondances et enfreindre les réglementations.
Grâce à nos solutions, vous pouvez vous assurer que les paiements et les fournisseurs sont vérifiés par rapport aux bases de données de l’OFAC. Que ce soit en temps réel ou en chargements par lots.
8. Automatiser la prévention des fraudes
La plupart des établissements de santé et des organismes de réglementation supportent des pertes énormes dues à des paiements et des demandes frauduleux en raison des relations cachées entre les entités.
Les données se présentent généralement sous la forme d’enregistrements informatiques qui ont été saisis dans différents systèmes à travers les départements ou les branches.
Les escrocs et les fraudeurs tirent parti de la multiplicité des enregistrements stockés à différents endroits d’une organisation. Créer des divergences qui rendent difficile la recherche de l’enregistrement original.
Dans certains cas, les employés utilisent des tactiques frauduleuses pour falsifier des documents, comme des rapports financiers, des reçus d’achats, etc. pour leur bénéfice personnel.
Le logiciel de rapprochement des données utilise des algorithmes de rapprochement flous de classe mondiale pour identifier les relations entre différents enregistrements. Ce qui peut aider à découvrir la vérité derrière la fraude.
Cette technique permet aux entreprises de retracer les étapes, facilitant ainsi les enquêtes pour aller à la source du problème.
Une majorité d’organismes gouvernementaux au Royaume-Uni participent à la Initiative nationale contre la fraude. Ce qui les oblige à s’engager dans un exercice de comparaison de données informatisées.
DataMatch Enterprise – Le logiciel de comparaison de données le plus rapide et le plus précis qui soit
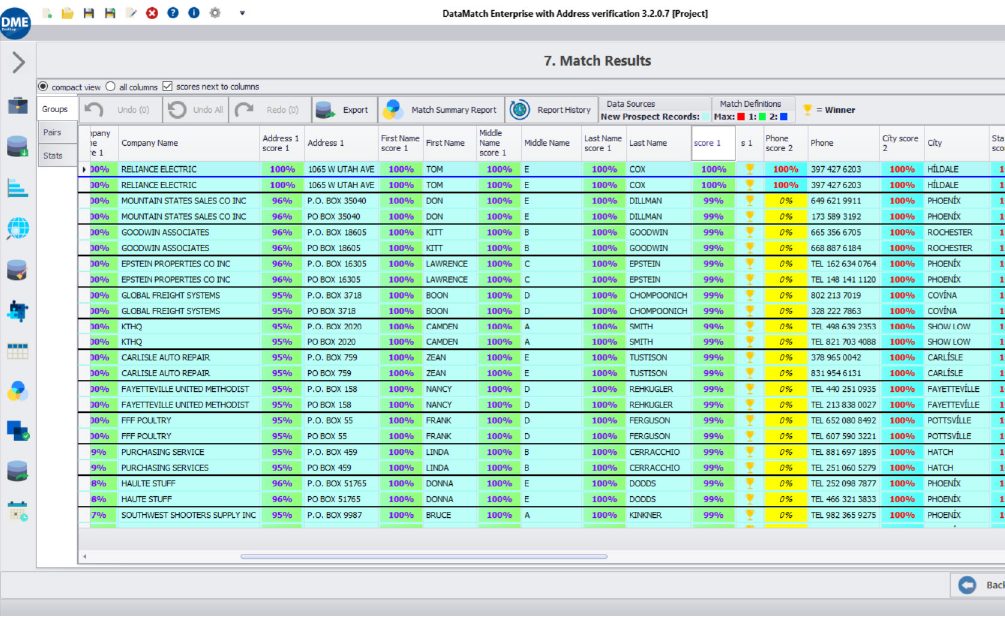
DataMatch Enterprise est une application de nettoyage de données très visuelle, spécialement conçue pour résoudre les problèmes de qualité des données des clients et des contacts. La plateforme exploite plusieurs algorithmes propriétaires et standard pour identifier les variations phonétiques, floues, mal saisies, abrégées et spécifiques à un domaine.
Créez des configurations évolutives pour la déduplication et le couplage d’enregistrements, la suppression, l’enrichissement, l’extraction et la normalisation des données commerciales et clients. Et créez une source unique de vérité pour maximiser l’impact de vos données dans toute l’entreprise.
Téléchargez la fiche technique et découvrez comment nous pouvons aider votre entreprise à se développer !



