






Combine and profile data
Bring data together at one place and build quick data summary report to highlight missing, incomplete, or invalid values present and identify potential data cleansing opportunities.

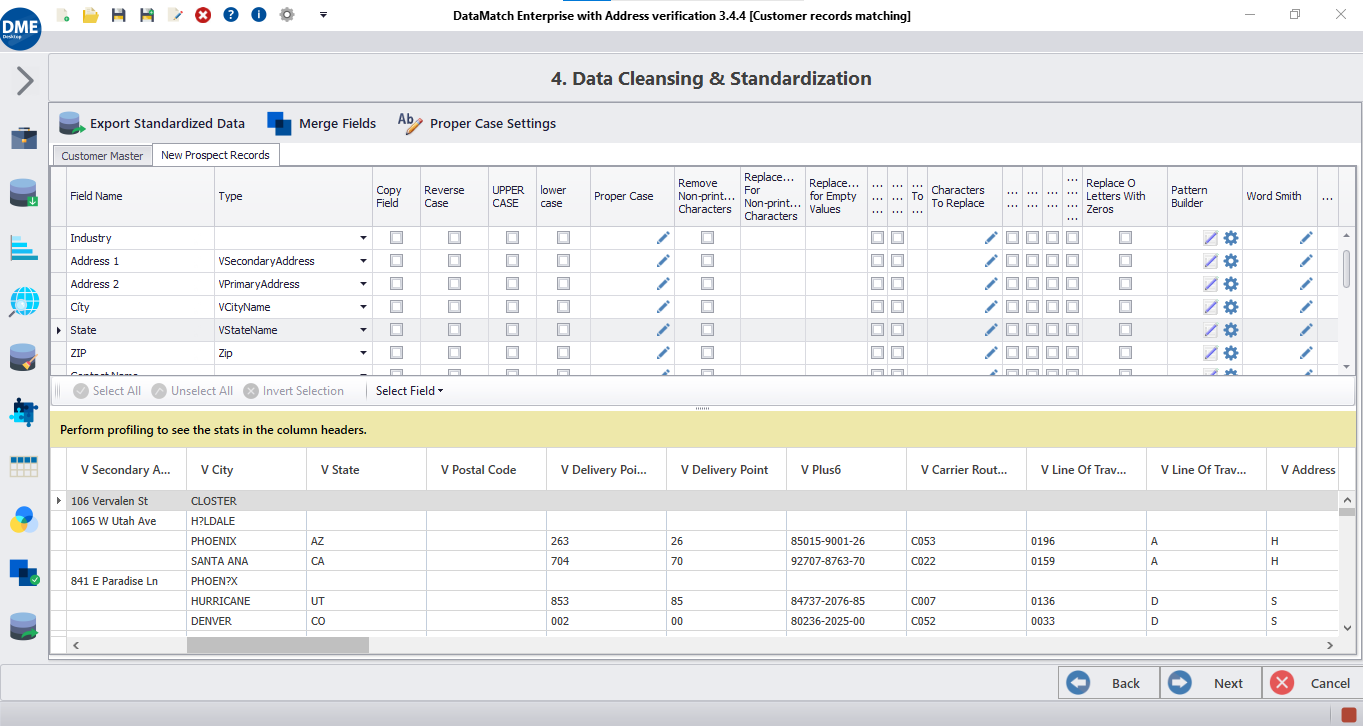
Parse and merge columns
Run data fields against a dictionary of words to identify sub-data elements (such as Street Name and Street Number for Address), and merge columns to follow custom-created formats.



Remove and replace characters
Remove and replace leading and trailing spaces, specific letters or numbers, non-printable characters, and more.

Transform letter cases
Transform cases of letters in strings to ensure a consistent and standardized view across all data records.