






Data integration
Connect to data sources and load data from various sources, such as local files, relational database servers, CRMs, or other web applications.

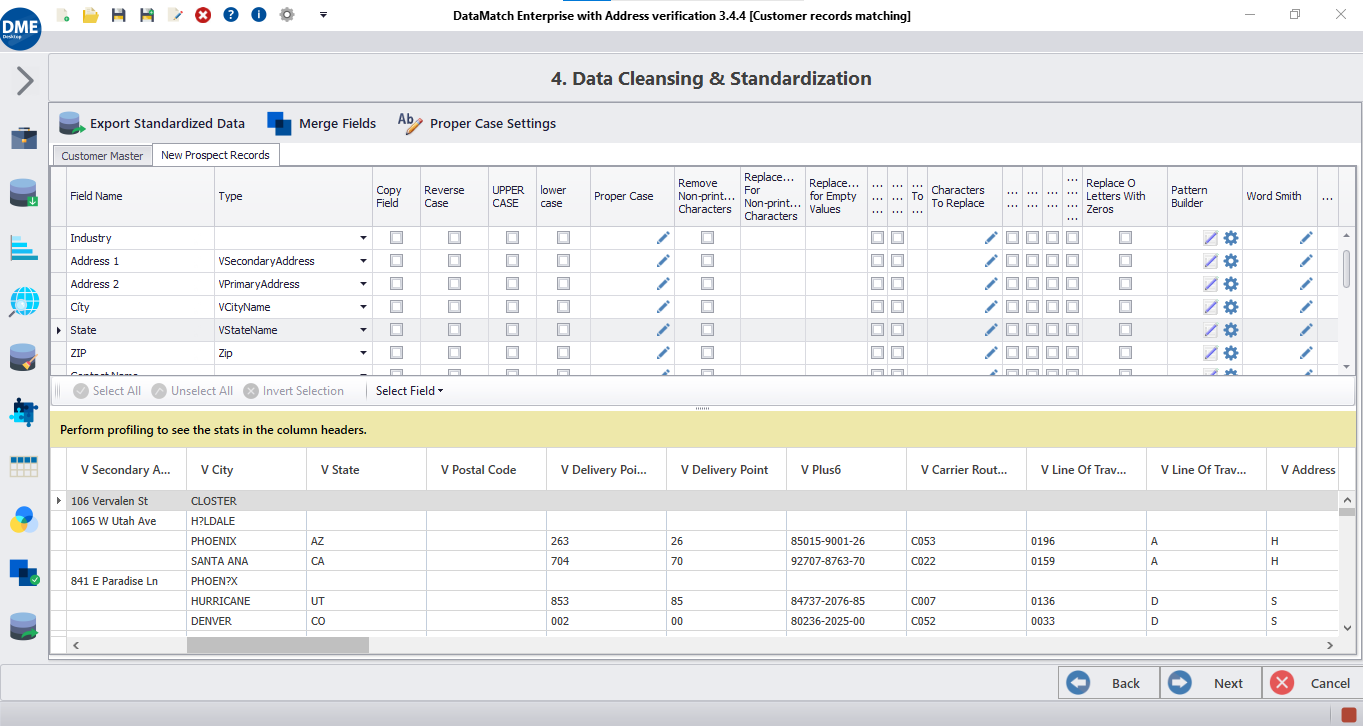
Data cleansing
Perform data cleansing activities to remove statistical and structural anomalies from data values, such as removing leading and trailing spaces, replacing null values, fixing punctuation errors, and more.




Data profiling
Run profiling and validity checks to assess data quality, build current data profile reports, and identify potential data cleaning opportunities.

Pattern recognition and validation
Recognize hidden patterns in your data columns, run validation checks, and transform invalid information so that all values follow the valid pattern.