































Data Ladder vs. Databricks for Data Matching
Organizations dealing with vast amounts of data require reliable, transparent, and efficient data matching solutions to ensure data integrity and accuracy. While Databricks serves as a powerful data repository and processing platform, it lacks native data matching and entity resolution capabilities. To achieve data matching within Databricks, users must integrate third-party solutions such as Zingg.
In contrast, Data Ladder’s DataMatch Enterprise (DME) is a purpose-built, comprehensive data matching solution that offers transparency, high accuracy, and deep control over data processing.

 53% higher matches during simulated tests with true-matching algorithms.
53% higher matches during simulated tests with true-matching algorithms.
US-based focus – custom detection patterns like valid SSN recognition.
Built-in Pattern Designer & Builder for proprietary records validation.
Decades of industry experience to tailor fine-tuned matching solutions for any industry.
Understanding Your Data: Transparency & Clarity
Data Ladder’s DataMatch Enterprise (DME) outperforms competitors in data matching accuracy, primarily due to its unmatched transparency and clarity in the data matching process. Organizations need to not only understand their data but also have visibility into what is happening to their data, including:
What matched to what – Detailed audit trails andexplainable matching logic, ensuring organizations knowexactly which records were linked and why.
Why records matched – Transparent scoring, confidencelevels, and matching percentages provide actionableinsights, eliminating the guesswork in decision-making.
Golden record management – Users can define, track, andconsolidate the most accurate version of a record througha structured, transparent process.
Comprehensive data profiling – Instant insights into dataquality issues with one-click profiling, enabling proactivedata cleansing and enhancement.
Version control & audit trails – Maintain a historicalrecord of matches, updates, and changes, ensuring fullaccountability and compliance.
Unlike black-box AI solutions, DME provides full visibility into matching logic, offering businesses complete control over their dataprocessing workflows. This means organizations can trust their matching results, fine-tune their processes based on real insights,and make informed decisions that improve overall data quality.
Key Features Comparison: Data Ladder vs. Databricks
| Native Data Matching | Yes | No (Requires Zingg) |
| Understanding Your Data | Full transparency in matches, audit trails, and clear data profiling. | Black-box AI approach with limited visibilityinto matching decisions. |
| Match Accuracy | Superior, with clear percentage scores and explainability. | ML-driven, requiring iterative training with less control over the process. |
| Address Standardization | Built-in address verification and cleansing. | Requires third-party integrations. |
| Pattern Matching & AI | Advanced pattern recognition and AI enhanced matching. | Machine learning-based, but requires ongoing model training. |
| Data Cleansing & Standardization | Out-of-the-box cleansing, transformation, and standardization. | Requires custom workflows and scripts. |
| Deployment Flexibility | Subscription & perpetual licensing options. | Subscription-only model. |
| Ease of Use | Drag-and-drop UI, no coding required. | Requires scripting and ML expertise. |
| Launch Year | 2008 | 2021 (Zingg) |
Why Data Ladder Wins

 Transparency & Control
Transparency & Control
 Transparency & Control
Transparency & ControlDME provides full visibility into what is happening to your data, how it is being matched, and why records are considered duplicates. The audit trail, version control, and detailed match reports ensure unmatched clarity, giving users full confidence in their data.
 Higher Accuracy with Explainability
Higher Accuracy with Explainability
 Higher Accuracy with Explainability
Higher Accuracy with ExplainabilityUnlike Databricks + Zingg, which operates as a black-box machine learning model, DME ensures accuracy by combining exact, fuzzy, phonetic (Soundex, Metaphone), and pattern-based matching algorithms with clear percentage-based scoring.

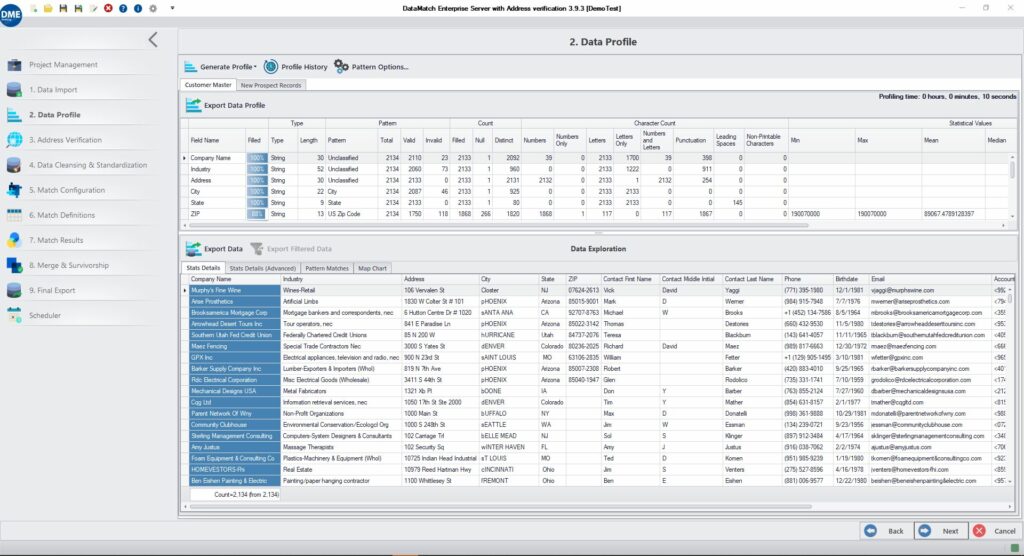
One-Click Profiling for Immediate Insights
 One-Click Profiling for Immediate Insights
One-Click Profiling for Immediate InsightsDME offers an instant data profiling feature that provides quick insights into data quality issues, enabling immediate action for data improvement.
Cost-Effective and User-Friendly
 Cost-Effective and User-Friendly
Cost-Effective and User-FriendlyWith flexible annual licensing options, DME is more cost-effective than a Databricks + Zingg subscription model, which scales with data volume. DME also features an intuitive drag-and drop interface, removing the need for extensive scripting or machine learning expertise.

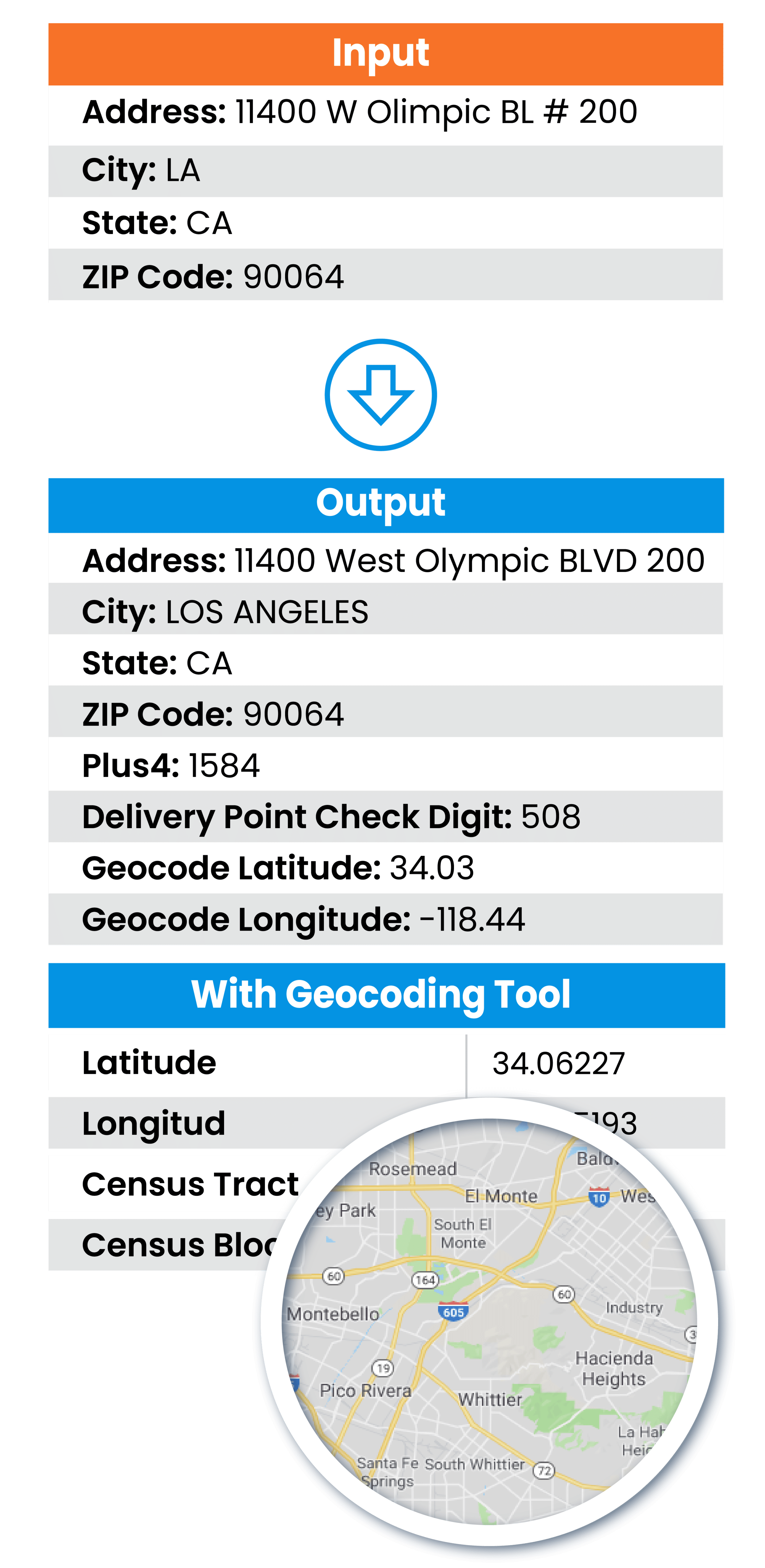
Built-in Address Standardization & Cleansing
DME includes robust address cleansing and standardization capabilities, ensuring accurate location-based data without requiring additional tools.
1. Data Integrity and Profiling

SSN and Profiling: Incorporates comprehensive SSN logic based on the US Social Security Administration recommendations, enhancing its capability to handle US-specific data such as SSNs and ZIP+4 codes.

Data Integrity: High, as it tracks manual data overwrites, preventing unauthorized changes that could compromise data integrity.

Profiling Depth: Offers deep and comprehensive data profiling, allowing for detailed analysis and cleaning of datasets before matching. Supports profiling patterns using Regular Expressions (RegEx) for a deeper dive into data types.

Cleansing Patterns: Allows parsing data into multiple columns, providing greater flexibility in data cleansing.

2. Accuracy and Grouping Quality
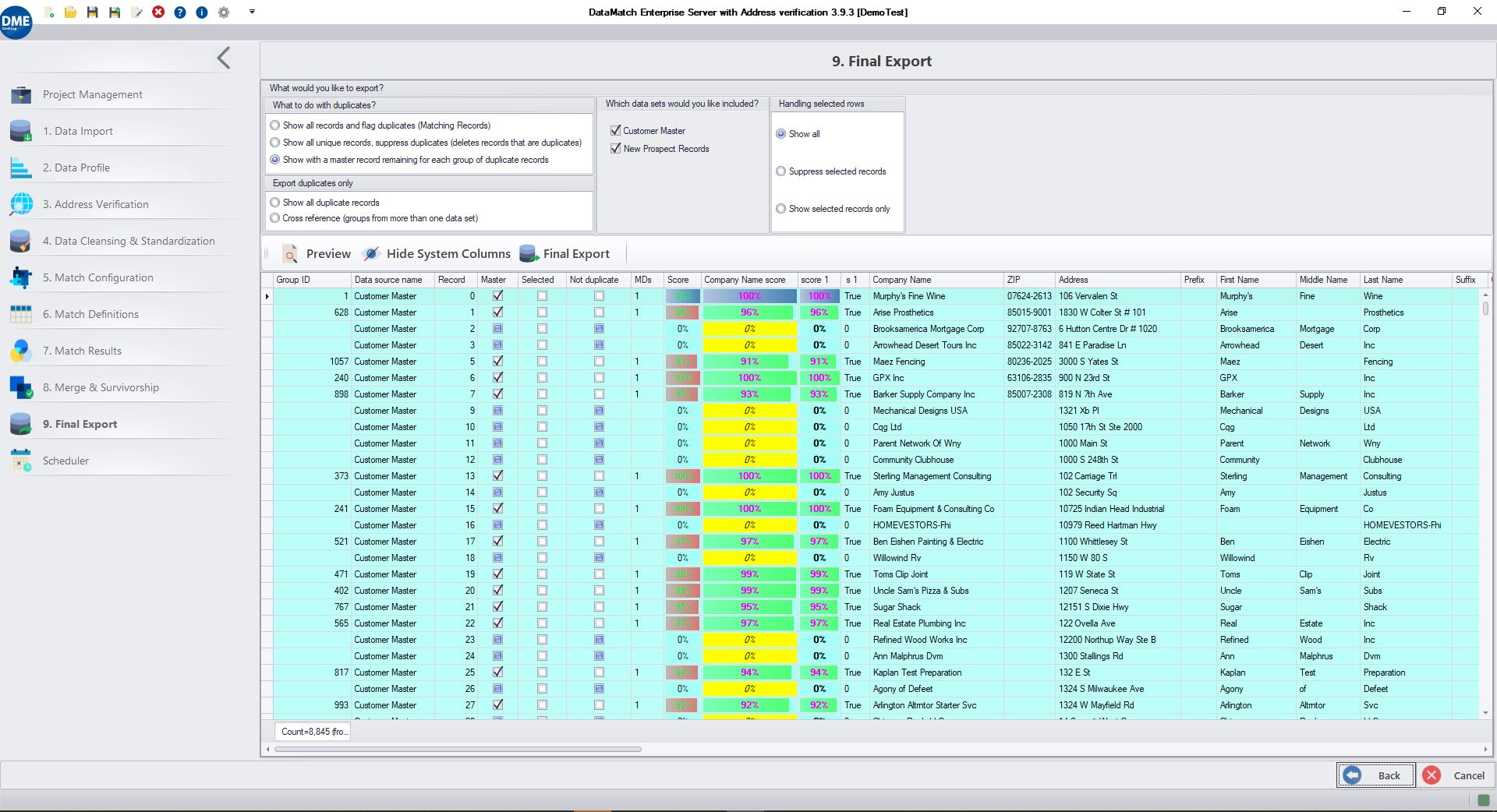
Accuracy: Demonstrates superior accuracy in matching records. For example, it found 98,430 matches and grouped them into 2,038 groups in one of the tests.
Group Quality: Better grouping accuracy, ensuring that related records are grouped correctly, which is crucial for data analysis and reporting.
Match Results Sorting and Scoring: Sorts results from highest to lowest overall score and shows scores even if the definition was not matched. Provides an option to place scores next to columns for better visibility.

3. US-Based Optimization and Fine-tuning Features for Match Accuracy
US-Based Features: Optimized for handling US-specific data, including SSNs and ZIP+4 codes. This makes it particularly suitable for US-based clients who need precise and accurate data handling.
Match Configuration: Allows one-to-many (custom config) or within-only configurations, providing flexibility in matching setups.
Mapping Rules: Conserves defined rules during remapping and supports auto-mapping for matching or merging.
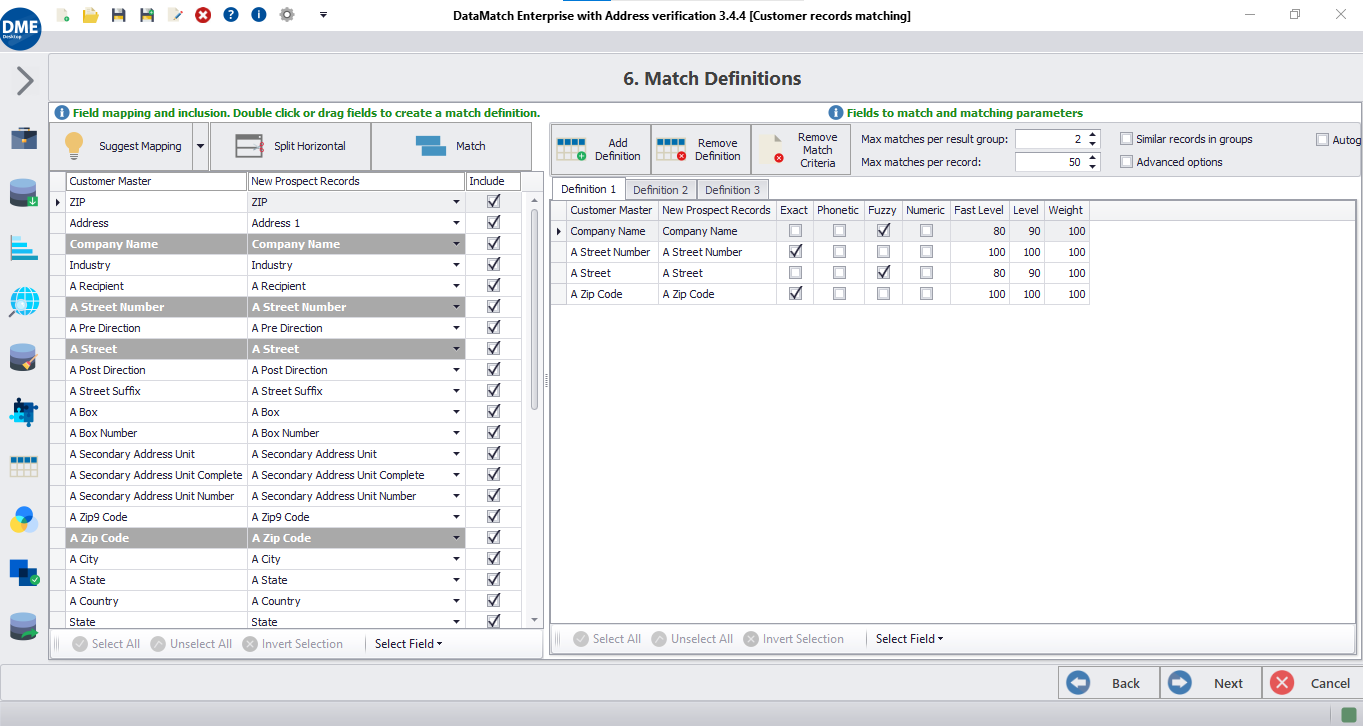
4. US-Based Optimization and Fine-tuning Features for Match Accuracy
Merge and Overwrite: Supports merging coalescence to merge the first N non-empty columns, and offers various options for overwrite/enrich (longest, shortest, max, min, merge all values).

Export Options: Includes a deduplication option (Master + Uniques) for exporting.

Match Summary Report: Includes data from the entire project, providing a comprehensive project audit.
Conclusion
For organizations prioritizing clarity, accuracy, and control over their data matching processes, Data Ladder’s DataMatch Enterprise is the superior choice. While Databricks serves as a strong data repository, it lacks built-in entity resolution and relies on third-party tools like Zingg, which introduces limitations in transparency, explainability, and flexibility. DME delivers a complete, transparent, and cost effective solution—out of the box.
Choose DataMatch Enterprise for unparalleled data matching accuracy, transparency, and ease of use.




