































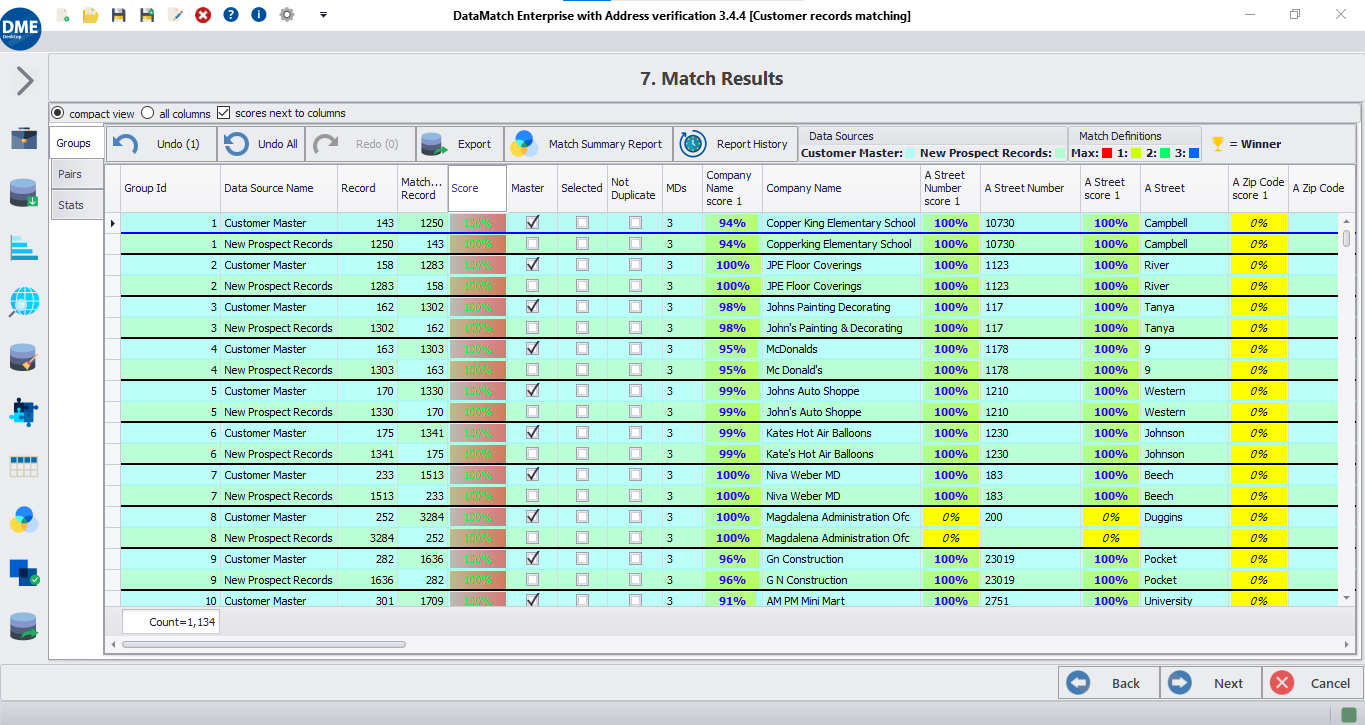






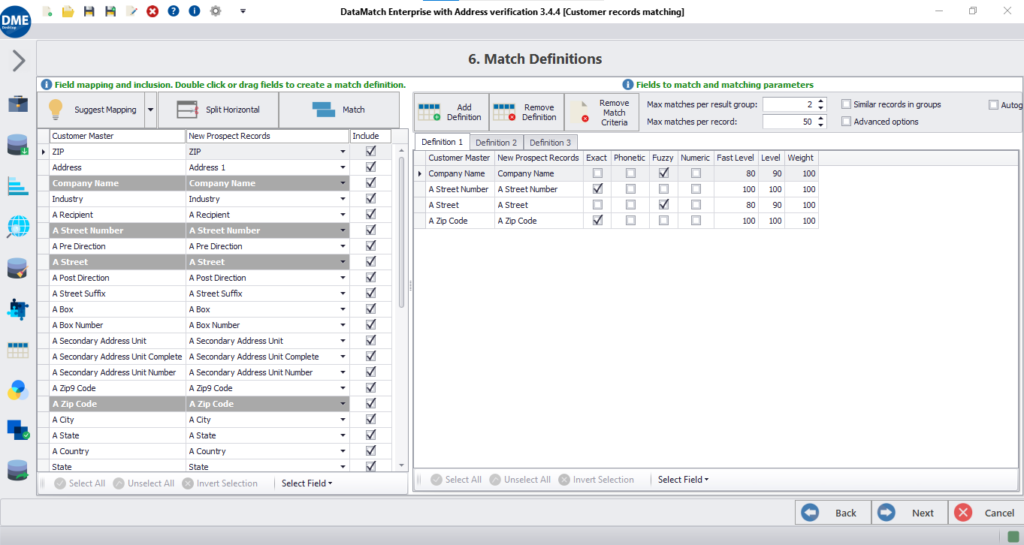

Machine learning and rules-based match algorithms for higher accuracy than either approach alone.
DME allows you to utilize the match results for subsequent steps of deduping , merging, and purging data records. You can also use the match results and scores to create survivorship rules or perform advanced data analysis – for example, merging records that show a high level of match confidence, or identify households where records have the same (or similar) residential address.

Data analysts

Business users

IT Professionals

Novice users


Merging Data from Multiple Sources – Challenges and Solutions

Data Deduplication API vs Batch Deduplication: When to Use Each
Last Updated on June 30, 2026 The right choice between a deduplication API and batch deduplication comes down to when deduplication needs to happen. If
Best Financial Data Quality Software: Features, Pricing, and Use Cases (2026)
Last Updated on June 2, 2026 In 2025, over a quarter of organizations reported losing more than $5 million annually from poor data quality, according
Data Deduplication API vs Batch Deduplication: When to Use Each
Last Updated on June 30, 2026 The right choice between a deduplication API and batch deduplication comes down to when deduplication needs to happen. If
Best Financial Data Quality Software: Features, Pricing, and Use Cases (2026)
Last Updated on June 2, 2026 In 2025, over a quarter of organizations reported losing more than $5 million annually from poor data quality, according
How to Build a Financial Data Quality Management Program (2026 Guide)
Last Updated on May 25, 2026 Financial data quality management is the set of processes, ownership structures, and controls that finance and IT teams use
