| Native Data Matching | Yes | No (Requires Zingg) |
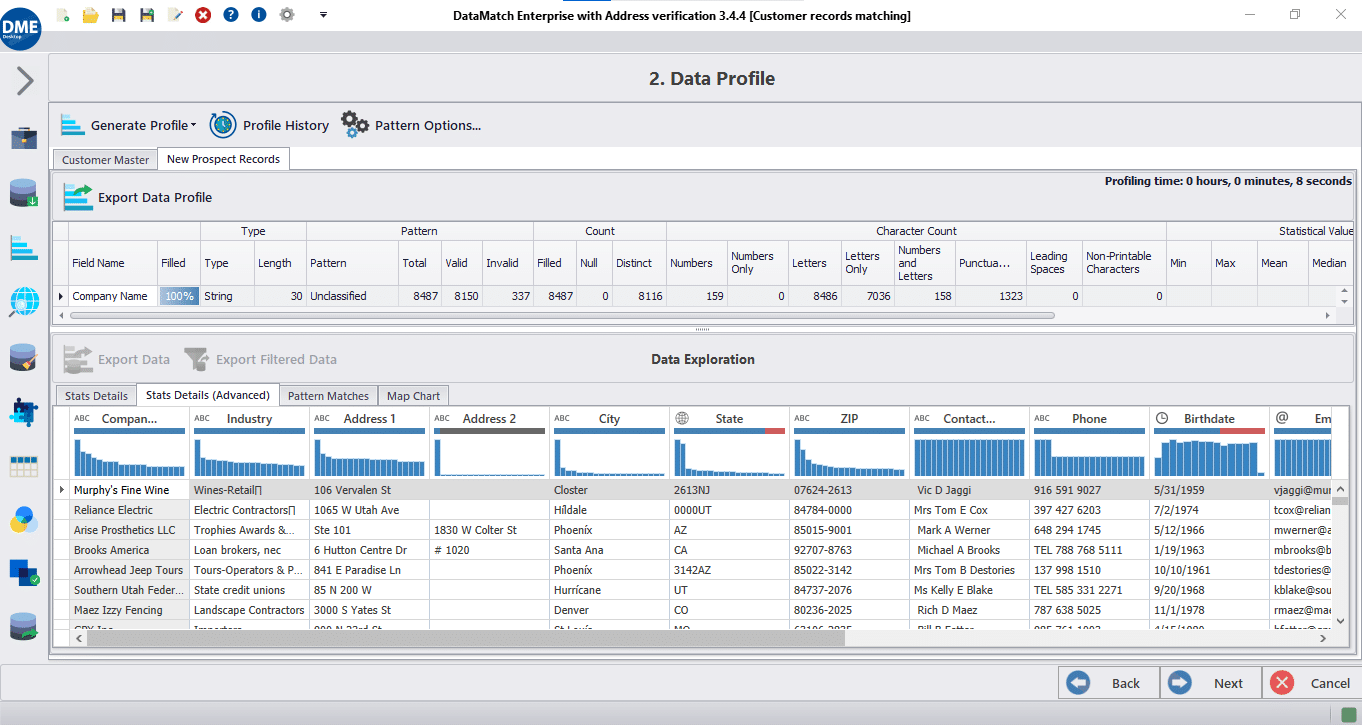
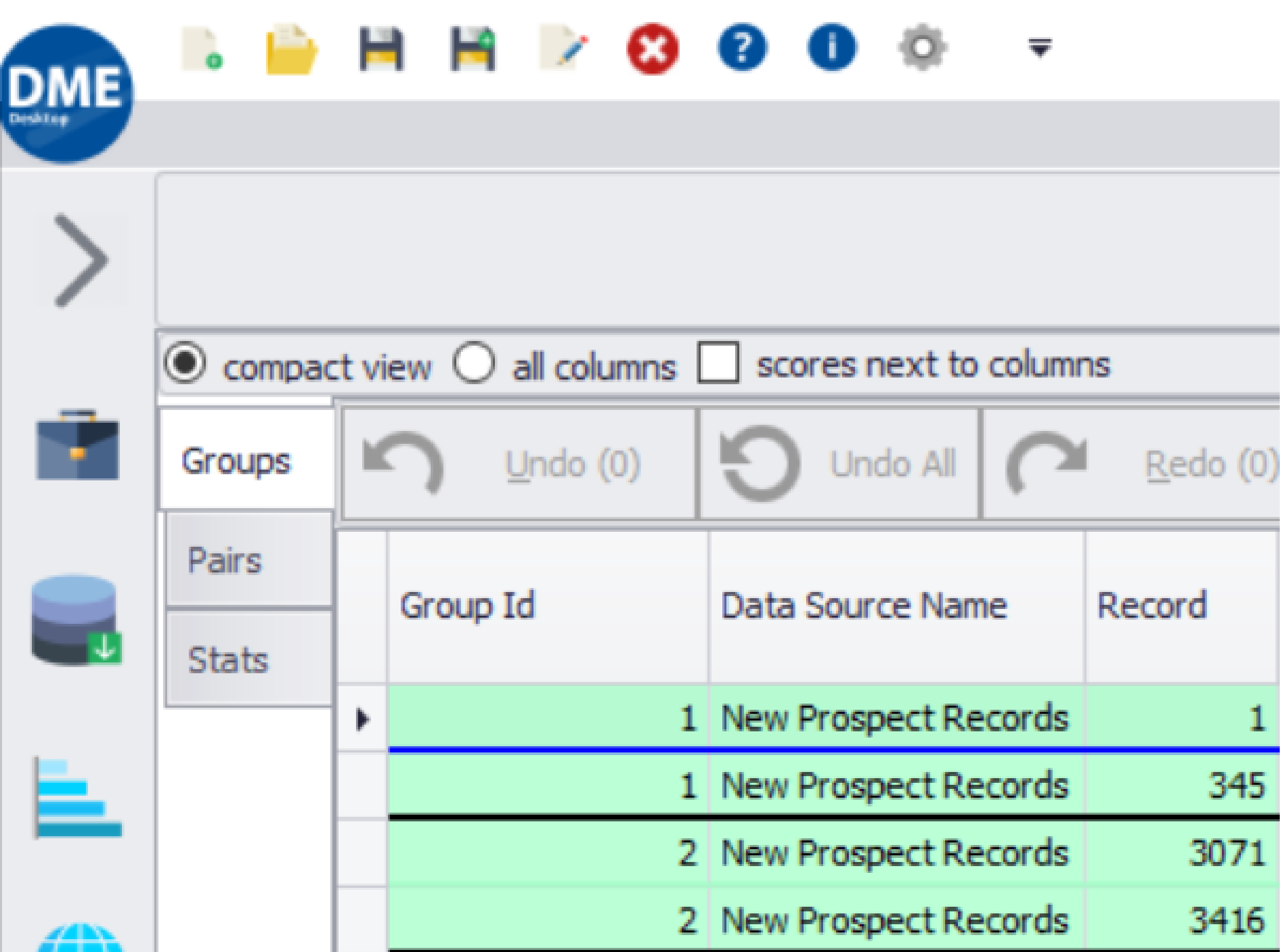
| Understanding Your Data | Full transparency in matches, audit trails, and clear data profiling | Black-box AI approach with limited visibilityinto matching decisions |
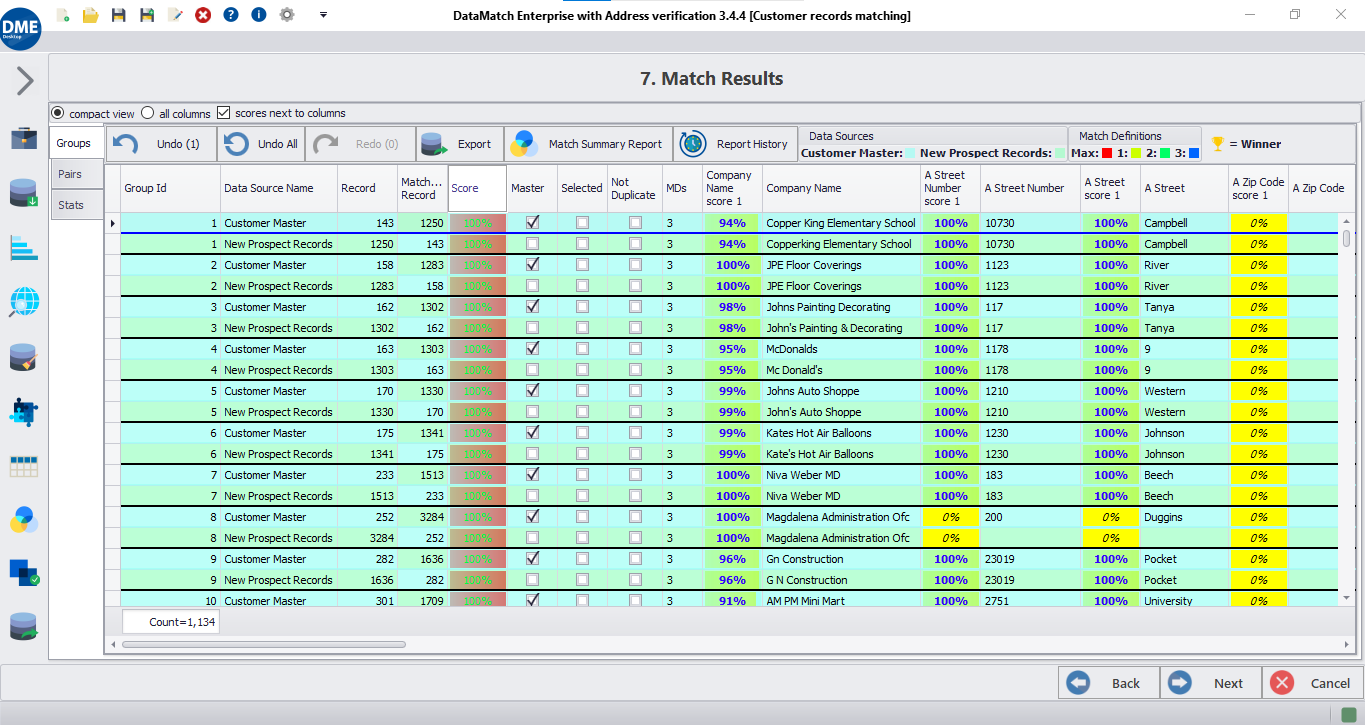
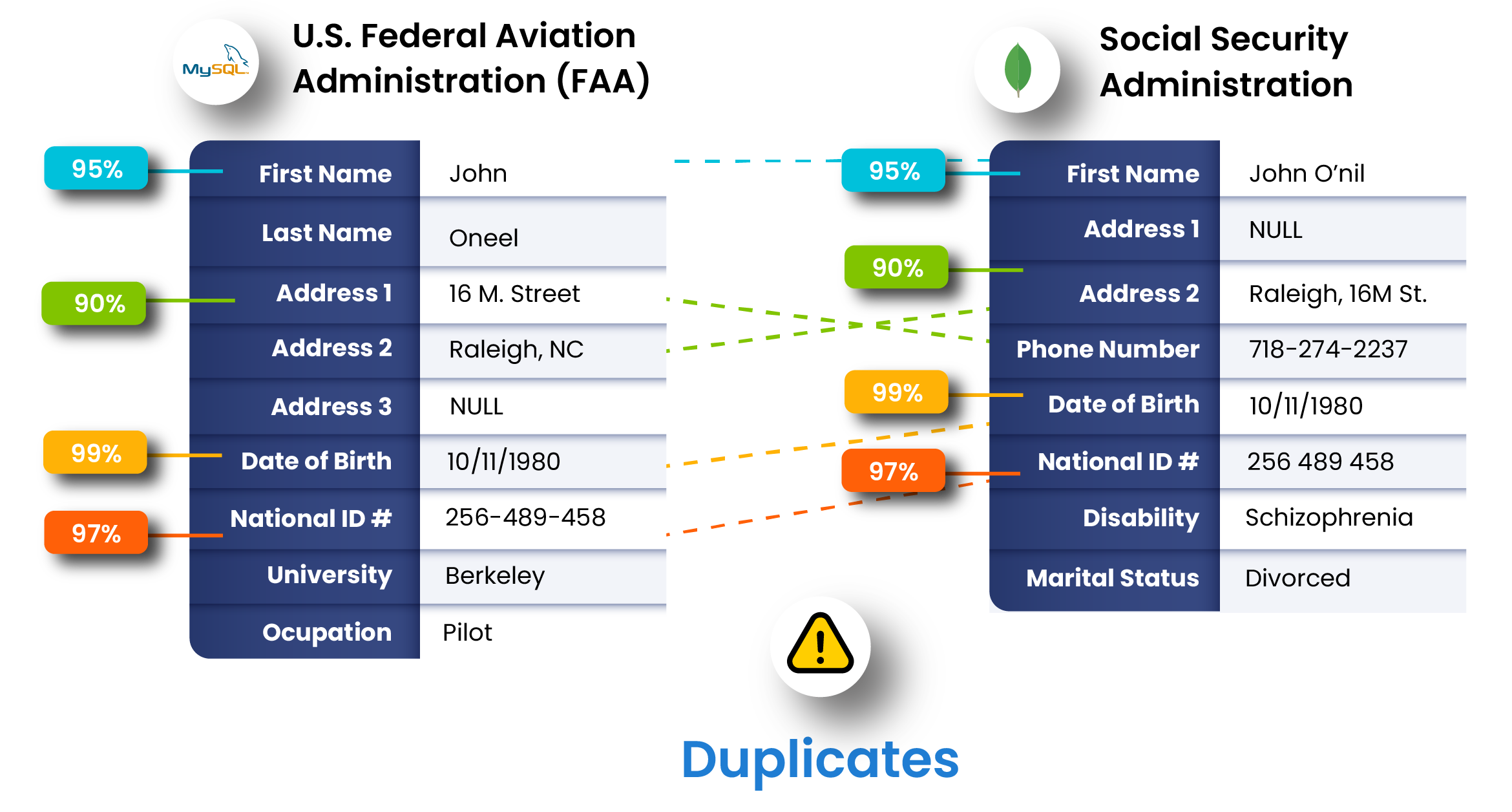
| Match Accuracy | Superior, with clear percentage scores and explainability | ML-driven, requiring iterative training with less control over the process |
| Address Standardization | Built-in address verification and cleansing | Requires third-party integrations |
| Pattern Matching & AI | Advanced pattern recognition and AI-enhanced matching | Machine learning-based, but requires ongoing model training |
| Data Cleansing & Standardization | Out-of-the-box cleansing, transformation, and standardization | Requires custom workflows and scripts |
| Deployment Flexibility | Subscription & perpetual licensing options | Subscription-only model |
| Ease of Use | Drag-and-drop UI, no coding required | Requires scripting and ML expertise |
| Launch Year | 2008 | 2021 |