





























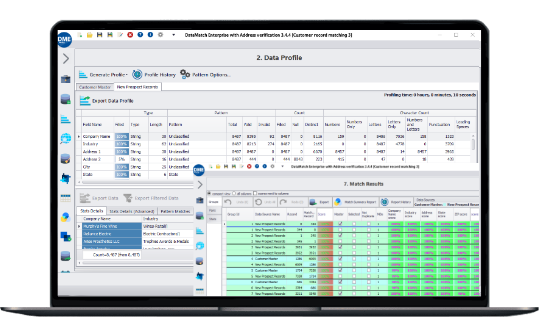







DataMatch Enterprise™ était beaucoup plus facile à utiliser que les autres solutions que nous avons examinées. Pouvoir automatiser le nettoyage et la correspondance des données nous a permis d'économiser des centaines d'heures-personnes chaque année.


Nous avons obtenu un taux de correspondance 24% supérieur en utilisant DataMatch Enterprise™ par rapport à notre fournisseur standard.

Nous avons apprécié la capacité du produit à catégoriser les données selon nos besoins et sa polyvalence.






Fusion de données provenant de sources multiples - Défis et solutions

Un guide rapide pour la normalisation et la vérification des adresses
Qu’est-ce que la normalisation des adresses ? La normalisation des adresses est le processus qui consiste à mettre à jour et à appliquer une norme

8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise
En février 2020, Facebook a remis un ensemble de données anonymes à Social Science One – dans le but d’obtenir des informations sur les communications
Un guide rapide pour la normalisation et la vérification des adresses
Qu’est-ce que la normalisation des adresses ? La normalisation des adresses est le processus qui consiste à mettre à jour et à appliquer une norme
8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise
En février 2020, Facebook a remis un ensemble de données anonymes à Social Science One – dans le but d’obtenir des informations sur les communications

Guide du filtrage : ce que cela signifie et comment le faire ?
Last Updated on septembre 13, 2022 Il est facile de trouver des modèles dans tout type d’environnement riche en données ; c’est ce que font
