






Combiner et profiler les données
Rassemblez les données en un seul endroit et créez un rapport de synthèse rapide des données pour mettre en évidence les valeurs manquantes, incomplètes ou invalides présentes et identifier les opportunités potentielles de nettoyage des données.

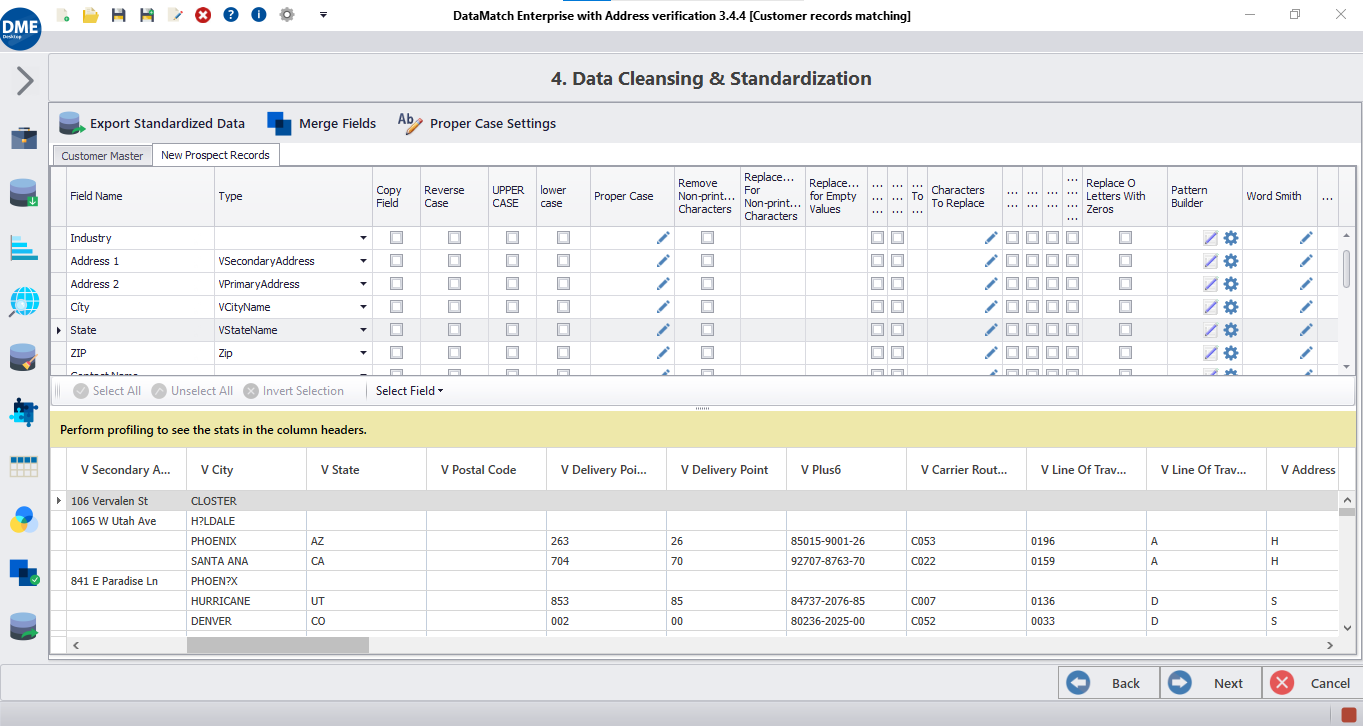
Analyser et fusionner des colonnes
Exécutez les champs de données avec un dictionnaire de mots pour identifier les éléments de sous-données (tels que le nom de la rue et le numéro de la rue pour l'adresse) et fusionnez les colonnes pour suivre des formats personnalisés.



Supprimer et remplacer des caractères
Supprimez et remplacez les espaces de début et de fin , des lettres ou des chiffres spécifiques, des caractères non imprimables, etc.

Transformer la casse des lettres
Transformez les cas de lettres en chaînes pour garantir une vue cohérente et standardisée de tous les enregistrements de données.