





























En février 2020, Facebook a remis un ensemble de données anonymes à Social Science One – dans le but d’obtenir des informations sur les communications et le comportement des médias sociaux. L’ensemble de données contenait des informations sur 38 millions d’URL qui ont été partagées publiquement plus de 100 fois.
Le 20 septembre 21, Facebook a reconnu auprès de trois douzaines de chercheurs que l’ensemble de données comportait de graves erreurs et s’est excusé pour l’impact négatif qu’il a eu sur leurs recherches. Il s’avère que Facebook a omis d’inclure les données de la moitié de ses utilisateurs américains – car ils étaient moins polarisés politiquement par rapport à l’ensemble des utilisateurs. La porte-parole de Facebook a précisé que cet incident était dû à une erreur technique survenue dans son ensemble de données URL Shares.
Aujourd’hui, les données constituent sans aucun doute l’un des principaux atouts d’une organisation. Il est utilisé partout, qu’il s’agisse des opérations quotidiennes d’une entreprise, du renforcement de ses initiatives de veille stratégique ou, dans le cas de Facebook, de la facilitation de plus de 100 recherches. Mais en l’absence de techniques et de meilleures pratiques en matière de qualité des données (qui permettent de suivre et de résoudre les problèmes de qualité des données à temps), une entreprise peut perdre beaucoup d’argent et risquer de se retrouver à la traîne.
Dans ce blog, nous examinerons un certain nombre de bonnes pratiques et de processus de qualité des données qui peuvent contribuer à une qualité élevée des données au niveau de l’entreprise. En plus de souligner ce qui est nécessaire, je mentionnerai également les éléments réalisables qui peuvent vous aider à atteindre cet état.
En outre, les pratiques mentionnées ci-dessous donneront les meilleurs résultats si elles sont effectuées de manière cohérente à intervalles réguliers dans une entreprise. Les données (dans leur définition et leur utilisation) sont susceptibles de changer. Ainsi, si votre entreprise revoit constamment ces pratiques, vous pouvez certainement obtenir des résultats meilleurs et durables.
Commençons.
1. Déterminer la relation entre les données et les performances de l’entreprise
Nous commençons par cette pratique car il s’agit de l’élément le plus important et le plus fondamental pour permettre une gestion, une adoption et une utilisation appropriées des données dans toute organisation. Tout d’abord, vous devez comprendre comment les données contribuent à vos buts et objectifs commerciaux.
A quoi cela ressemble-t-il ?
Il peut s’agir d’analyser le rôle des données à un niveau élevé (par exemple, en mettant en évidence les domaines dans lesquels les données sont utilisées) ou d’aller plus loin dans les détails (comme le rôle des données dans les opérations quotidiennes, les processus commerciaux, l’échange d’informations entre les départements, etc.)
Une fois que vous avez identifié cela, il est temps de poser cette question : si ces processus ou domaines n’ont pas été facilités par des données de qualité, quel impact cela peut-il avoir sur les indicateurs clés de performance qui en résultent ?
Un exemple d’une telle situation est lorsque les cadres dirigeants fixent l’objectif de revenu pour le trimestre suivant en se basant sur les données de vente du trimestre précédent, mais qu’ils découvrent que l’ensemble de données utilisé pour prévoir l’objectif futur présente de sérieux problèmes de qualité des données, ce qui oblige votre département des ventes à poursuivre une valeur arbitraire qui n’a aucune signification concrète. La situation qui en résulte a un impact négatif massif sur les opérations et la réputation de l’entreprise, comme le fait de fixer des attentes irréalistes aux représentants commerciaux, de promettre des chiffres de revenus inexacts, etc.
Comment cela aide-t-il ?
Comprendre le rôle des données dans chaque processus de fonctionnement d’une entreprise vous permet d’avoir toujours sous la main un argumentaire pour hiérarchiser les données et leur qualité. En fait, cela vous aidera également à obtenir l’adhésion et l’attention nécessaires des parties prenantes, ce qui est crucial pour apporter et proposer des changements aux processus existants.
2. Mesurer et maintenir la définition de la qualité des données
Une fois que vous connaissez l’impact des données sur votre entreprise, l’étape suivante consiste à assurer la qualité des données dans tous les ensembles de données de votre organisation. Mais avant cela, il est important de comprendre la définition de la qualité des données, car elle a une signification différente pour chaque entreprise.
La qualité des données est définie comme le degré auquel les données remplissent l’objectif prévu. Ainsi, pour comprendre la signification de la qualité des données dans votre cas, vous devez savoir quel est l’objectif visé.
A quoi cela ressemble-t-il ?
Pour définir la qualité des données pour votre entreprise, vous devez commencer par identifier les :
- Sources qui génèrent, stockent ou manipulent des données,
- Attributs stockés par chaque source,
- Glossaire des métadonnées qui définit chaque attribut,
- les critères d’acceptabilité des valeurs de données stockées dans les attributs, et
- Les métriques de qualité des données qui mesurent la qualité des données stockées.
Un exemple de définition de la qualité des données dans votre entreprise consiste à dessiner des modèles de données qui mettent en évidence les parties nécessaires des données (la quantité et la qualité des données qui sont considérées comme suffisantes). Considérez l’image suivante pour comprendre à quoi peut ressembler un modèle de données pour une entreprise de vente au détail :
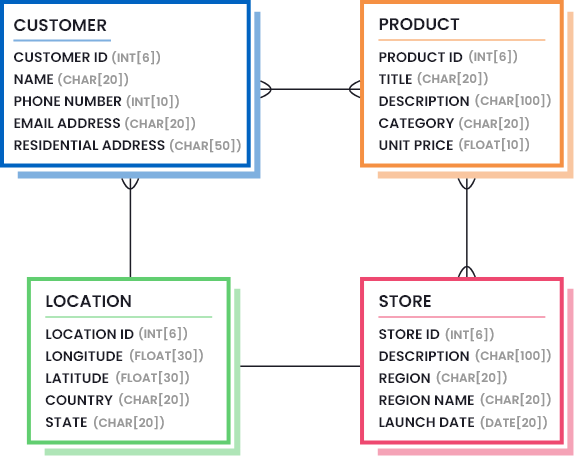
En outre, outre la conception de modèles de données, vous devez également identifier des mesures de qualité des données qui confirment la présence d’un niveau de qualité acceptable dans vos ensembles de données. Par exemple, vous pouvez exiger que votre ensemble de données soit plus précis et plus fiable que complet.
Comment cela aide-t-il ?
Une définition normalisée de la qualité des données permet de mettre tout le monde sur la même longueur d’onde, afin qu’ils puissent comprendre ce que signifie la qualité des données, à quoi elle ressemble et comment elle peut être mesurée. Cela permet à chaque personne de comprendre et de satisfaire les exigences en matière de qualité des données.
3. Définir les rôles et les responsabilités en matière de données dans l’ensemble de l’organisation
Il est communément admis que la garantie de la qualité des données au niveau de l’entreprise nécessite l’implication ou l’adhésionde la direction générale. En réalité, plus que d’impliquer certaines personnes dans des environnements cloisonnés, vous devez engager des personnes dans les processus existants, et rendre les gens responsables de l’obtention et du maintien de la qualité des données – de la direction de haut niveau au personnel opérationnel.
A quoi cela ressemble-t-il ?
Parmi les rôles courants mais importants en matière de données et leurs responsabilités, citons les suivants :
- Chief Data Officer (CDO) : un représentant des données au sein de la direction de haut niveau, chargé de concevoir des stratégies pour assurer une gestion efficace des données, un suivi de la qualité des données et l’adoption des données dans toute l’organisation.
- Intendant des données : contrôleur de la qualité des données, chargé de garantir l’adéquation des données à l’usage auquel elles sont destinées et de gérer les métadonnées.
- Responsable des données et de l’analyse (D&A) : un acteur des données, chargé d’assurer la maîtrise des données dans l’ensemble de l’organisation et de permettre aux données de produire de la valeur.
Comment cela aide-t-il ?
Lorsque les données sont traitées comme la source principale alimentant les processus commerciaux fondamentaux, un changement se produit à l’échelle de l’entreprise. C’est là que l’attribution de rôles et de responsabilités dans le domaine des données et le fait de donner aux gens le pouvoir d’avoir un impact et de s’exprimer sur les questions cruciales relatives aux données peuvent jouer un rôle important pour assurer une culture des données réussie dans toute organisation.
4. Former et éduquer les équipes sur les données
Dans une enquête menée auprès de 9000 employés jouant différents rôles dans une organisation, seuls 21 % d’entre eux avaient confiance dans leurs compétences en matière de données.
L’introduction de rôles et de responsabilités en matière de données peut avoir un impact positif énorme sur votre entreprise, mais il est néanmoins crucial de considérer que dans un lieu de travail moderne, chaque individu génère, manipule ou traite des données dans ses opérations quotidiennes. C’est pourquoi, s’il est important de confier à certaines personnes la responsabilité de mettre en œuvre des mesures correctives, il est tout aussi nécessaire de former et d’éduquer toutes les équipes sur la manière de traiter les données organisationnelles.
A quoi cela ressemble-t-il ?
Cela peut impliquer la création de plans de maîtrise des données et la conception de cours qui initient les équipes aux données et aux explications de l’organisation :
- Ce qu’il contient,
- La signification de chaque attribut de données,
- Quels sont les critères d’acceptabilité de sa qualité,
- Quelle est la bonne et la mauvaise manière de saisir/manipuler les données ?
- Quelles données utiliser pour atteindre un résultat donné ?
En outre, ces cours peuvent être créés en fonction de la fréquence d’utilisation des données par certains rôles (quotidienne, hebdomadaire ou annuelle).
Comment cela aide-t-il ?
La capacité de lire, de comprendre et d’analyser correctement et précisément les données à tous les niveaux permet à chaque employé de poser les bonnes questions, et ce de la manière la plus optimisée possible. Il garantit également l’efficacité opérationnelle de votre personnel et réduit les erreurs lors de la communication de questions impliquant des données.
5. Contrôler en permanence l’état des données grâce au profilage des données.
Obtenir la qualité des données et la maintenir dans le temps sont deux choses différentes. C’est pourquoi vous devez mettre en œuvre un processus systématique qui surveille en permanence l’état des données et les profile pour découvrir des détails cachés sur leur structure et leur contenu.
La portée et le processus de l’activité de profilage des données peuvent être définis en fonction de la définition de la qualité des données dans votre entreprise et de la manière dont elle est mesurée.
A quoi cela ressemble-t-il ?
Cela peut être réalisé en configurant et en programmant des rapports quotidiens/hebdomadaires sur le profil des données. En outre, vous pouvez concevoir des flux de travail personnalisés pour alerter les responsables des données de votre entreprise si la qualité des données passe en dessous d’un seuil acceptable.
Un rapport sur le profil des données met généralement en évidence un certain nombre d’éléments concernant les ensembles de données examinés, par exemple :
- Le pourcentage de valeurs de données manquantes et incomplètes,
- Le nombre d’enregistrements qui sont des doublons possibles les uns des autres,
- Évaluation des types, des tailles et des formats de données afin de découvrir des valeurs de données invalides,
- Analyse statistique de colonnes de données numériques pour évaluer les distributions.
Comment cela aide-t-il ?
Cette pratique vous permet de détecter les erreurs de données à un stade précoce du processus et d’éviter qu’elles ne se répercutent sur les clients. En outre, il peut aider les Chief Data Officers à rester au fait de la gestion de la qualité des données et à prendre les bonnes décisions, notamment quand et comment résoudre les problèmes mis en évidence dans les profils de données.
En savoir plus sur le profilage des données : Portée, techniques et défis.
6. Concevoir et maintenir des pipelines de données pour obtenir une source unique de vérité.
Un pipeline de données est un processus systématique qui ingère des données d’une source, exécute les techniques de traitement et de transformation nécessaires sur les données, puis les charge dans un référentiel de destination.
Il est essentiel que les données brutes passent par un certain nombre de contrôles de validation avant d’être jugées utilisables et mises à la disposition de tous les utilisateurs de l’organisation.
A quoi cela ressemble-t-il ?
Pour construire un pipeline de données, vous devez revenir à la pratique#02 que nous avons mentionnée dans ce blog : Définir et maintenir la définition de la qualité des données. Et selon cette définition, vous devez décider de la liste numérotée des opérations qui doivent être effectuées sur les données entrantes pour atteindre le niveau de qualité défini.
Voici une liste d’exemples d’opérations qui peuvent être effectuées dans votre pipeline de données :
- Remplacer les valeurs nulles ou vides par un terme standard, tel que « Non disponible ».
- Transformer les valeurs des données selon le modèle et le format définis.
- Analyse syntaxique des champs en deux colonnes ou plus.
- Remplacer les abréviations par des mots appropriés.
- Remplacer les surnoms par des noms propres.
- Si l’enregistrement entrant est suspecté d’être un doublon potentiel, il est fusionné avec l’enregistrement existant, plutôt que d’être créé comme un nouveau.

Comment cela aide-t-il ?
Un pipeline de données agit comme un pare-feu de qualité des données pour vos ensembles de données organisationnelles. La conception d’un pipeline de données permet de garantir la cohérence des données entre toutes les sources et d’éliminer toute divergence éventuelle, avant même que les données ne soient chargées dans la source de destination.
7. Effectuer une analyse des causes profondes des erreurs de qualité des données
Jusqu’à présent, nous nous sommes surtout concentrés sur la manière de suivre la qualité des données et d’éviter que des erreurs de qualité des données n’entrent dans les ensembles de données, mais la vérité est que, malgré tous ces efforts, certaines erreurs finiront probablement par se retrouver dans le système. Non seulement vous devrez les réparer, mais le plus important est de comprendre comment ces erreurs se sont produites afin d’éviter de tels scénarios.
A quoi cela ressemble-t-il ?
Une analyse des causes profondes des erreurs de qualité des données peut impliquer l’obtention du dernier rapport sur le profil des données et la collaboration avec votre équipe pour trouver des réponses à des questions telles que :
- Quelles erreurs de qualité des données ont été rencontrées ?
- D’où viennent-ils ?
- Quand ont-ils vu le jour ?
- Pourquoi se sont-ils retrouvés dans le système malgré tous les contrôles de validation de la qualité des données? On a raté quelque chose ?
- Comment éviter que de telles erreurs ne se reproduisent dans le système ?
Comment cela aide-t-il ?
Aller au cœur des problèmes de qualité des données peut contribuer à éliminer les erreurs à long terme. Vous ne devez pas toujours travailler selon une approche réactive et continuer à corriger les erreurs au fur et à mesure qu’elles se présentent. Grâce à une approche proactive, vous pouvez permettre à vos équipes de réduire au minimum les efforts qu’elles consacrent à la correction des erreurs de qualité des données – et laisser les processus affinés de qualité des données s’occuper de 99 % des problèmes associés aux données.
8. Utiliser la technologie pour atteindre et maintenir la qualité des données.
Ceci nous amène à notre dernière meilleure pratique : l’utilisation de la technologie pour atteindre un cycle de vie durable de la gestion de la qualité des données. Aucun processus n’est censé être performant et offrir le meilleur retour sur investissement s’il n’est pas automatisé et optimisé par la technologie.
A quoi cela ressemble-t-il ?
Investissez dans l’adoption d’un système technologique doté de toutes les fonctionnalités dont vous avez besoin pour garantir la qualité des données dans tous les ensembles de données. Ces caractéristiques comprennent la possibilité de :
- Importation de données: Intégrez des données provenant de plusieurs sources,
- Profil des données: Évaluer les données pour générer des rapports sur la qualité des données,
- Nettoyage des données: Mettez en évidence les domaines qui pourraient nécessiter un nettoyage, une normalisation et une transformation des données, et mettez en place des solutions,
- Correspondance des données: faites correspondre les données à l’aide d’algorithmes de correspondance exacte et floue avec un haut niveau de précision, et adaptez les algorithmes en fonction de la nature de vos données,
- Déduplication des données: Reliez les enregistrements et trouvez la source unique de vérité,
- Exportation de données : Exportation/chargement des résultats.
En plus des fonctions de gestion de la qualité des données mentionnées ci-dessus, certaines organisations investissent dans des technologies qui offrent également des capacités de gestion centralisée des données. Un exemple d’un tel système est la gestion des données de référence (MDM). Bien qu’un MDM soit une solution complète de gestion des données intégrant des fonctionnalités de qualité des données, toutes les organisations n’ont pas besoin de la liste exhaustive des fonctionnalités d’un tel système.
Vous devez comprendre les besoins de votre entreprise pour évaluer quel type de technologie est la bonne décision pour vous. Vous pouvez lire ce blog pour découvrir les différences fondamentales entre une solution MDM et DQM.
Comment cela aide-t-il ?
L’utilisation de la technologie pour la mise en œuvre de processus qui doivent être répétés régulièrement pour obtenir des résultats durables présente de nombreux avantages. En fournissant à votre équipe des outils de gestion de la qualité des données en libre-service, vous pouvez accroître l’efficacité opérationnelle, éliminer les efforts redondants, améliorer l’expérience client et obtenir des informations commerciales fiables.
Conclusion
La mise en œuvre de mesures de qualité des données cohérentes, automatisées et reproductibles peut aider votre organisation à atteindre et maintenir la qualité des données dans tous les ensembles de données.
Data Ladder offre des solutions de qualité des données à ses clients depuis plus d’une décennie maintenant. DataMatch Enterprise est l’un de ses principaux produits de qualité des données – disponible sous forme d’application autonome ou d’API intégrable – qui permet une gestion de la qualité des données de bout en bout, y compris le profilage, le nettoyage, la mise en correspondance, la déduplication et la purge par fusion des données.
Vous pouvez télécharger l’essai gratuit dès aujourd’hui ou programmer une session personnalisée avec nos experts pour comprendre comment notre produit peut aider à mettre en œuvre les meilleures pratiques pour atteindre et maintenir la qualité des données au niveau de l’entreprise.



