





























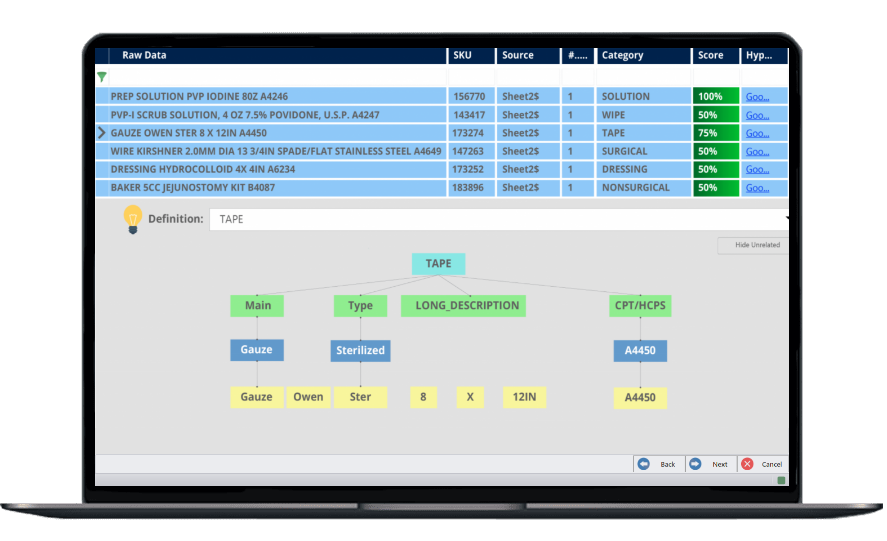









Reconnaissance sémantique
Le puissant moteur de reconnaissance contextuelle de la plateforme permet de comprendre la correspondance et la préparation des données dans un format structuré, éliminant ainsi le besoin de transformation des données.

Déduplication et liaison des produits
Réduisez considérablement le nombre de pièces dans votre inventaire tout en enrichissant les données sur les produits avec des attributs et des classifications en établissant des correspondances dans toute l'entreprise.

Correspondance de motifs
Utilisez l'assistant Regex pour identifier rapidement des modèles et analyser les enregistrements dans de nouveaux champs. Exemple : Le texte "3 x 4 x 6" peut être extrait en : Longueur = 3, Largeur = 4, et Hauteur = 6.
Produit correspondant
Faites correspondre des champs clés comme le numéro de pièce et le nom du fabricant ou des capacités clés comme la fonctionnalité du produit en extrayant des attributs pour comprendre les relations entre les produits.

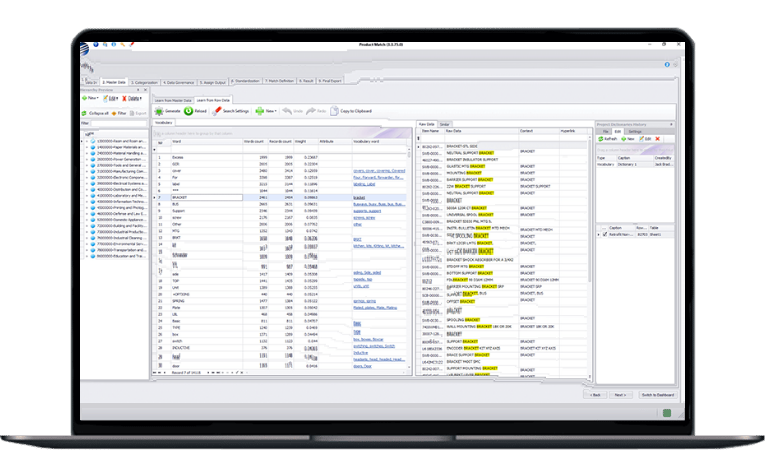
Interface de type "pointer-cliquer".
Data Ladder offre une interface moderne et visuelle dont il est prouvé qu'elle améliore d'au moins 10 % l'extraction, la normalisation et la structuration des attributs, ainsi que la précision des correspondances.
Normalisation à l'échelle
Identifiez et corrigez les fautes de frappe dans les données non structurées, analysez les attributs pertinents à l'aide d'un système avancé de correspondance des modèles et appliquez des règles de normalisation à grande échelle.
Capacités d'apprentissage automatique

Correspondance de motifs

Reconnaissance contextuelle

Validation de la qualité des données

Analyse syntaxique intelligente
Développement de la taxonomie
Traitement en mémoire
Fonctions de sortie personnalisées
Validation de la qualité des données basée sur des règles

L'intelligence compétitive

Bâtiment du catalogue

Analyse des lacunes du produit

Ce n'est pas seulement le logiciel qui fonctionne très bien pour nous, mais la concentration et les connaissances que Data Ladder apporte à la table


Grâce à Data Ladder, nous avons réussi à nettoyer et à faire correspondre notre fichier de vente interne avec de nouveaux prospects, améliorant considérablement l'efficacité et les ventes.

Nous ne pouvions pas faire ces rapports avant. Désormais, DataMatch est devenu un incontournable de ma suite d'outils avec laquelle je travaille


Fusion de données provenant de sources multiples - Défis et solutions

Un guide rapide pour la normalisation et la vérification des adresses
Qu’est-ce que la normalisation des adresses ? La normalisation des adresses est le processus qui consiste à mettre à jour et à appliquer une norme

8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise
En février 2020, Facebook a remis un ensemble de données anonymes à Social Science One – dans le but d’obtenir des informations sur les communications
Un guide rapide pour la normalisation et la vérification des adresses
Qu’est-ce que la normalisation des adresses ? La normalisation des adresses est le processus qui consiste à mettre à jour et à appliquer une norme
8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise
En février 2020, Facebook a remis un ensemble de données anonymes à Social Science One – dans le but d’obtenir des informations sur les communications

Guide du filtrage : ce que cela signifie et comment le faire ?
Last Updated on septembre 13, 2022 Il est facile de trouver des modèles dans tout type d’environnement riche en données ; c’est ce que font