































Now the user is ready to start manipulating the data you have imported.

-
- The field name is are the column headers from your data.
- Field type will automatically standardize the field based on the type you select:
-
- Full Name: this will parse the full name located in the field into Prefix, First Name, Common name, Last Name, Middle Name, and Suffix.
- The common name comes from an internal database that we and integrated with DataMatch Enterprise. This feature will try to resolve nicknames (ex Matt, Jimmy Bill) to their formal name (ex Matthew, James, William).
- FirstName: Selecting this will generate a new column and will relate the first name to a Common Name (Ex: Terry –> Terrance) as well as will generate a column for gender.
- Address: This works very well when you have multiple columns for addresses. Selecting this will create new columns and distribute the address information in them. The auto-created columns include the following: Recipient, Street Number, Pre-direction (NE, S, N), Street, Post-Direction (NE, S, N), Street Suffix, PO Box, PO Box Number, Secondary Address Unit (Suite, Office, etc), Secondary Address Unit Number, Zip Code.
- Zip: Selecting this will parse the zip code in two fields, one for the traditional 5-digit zip and one for the additional 4 digits that may exist.
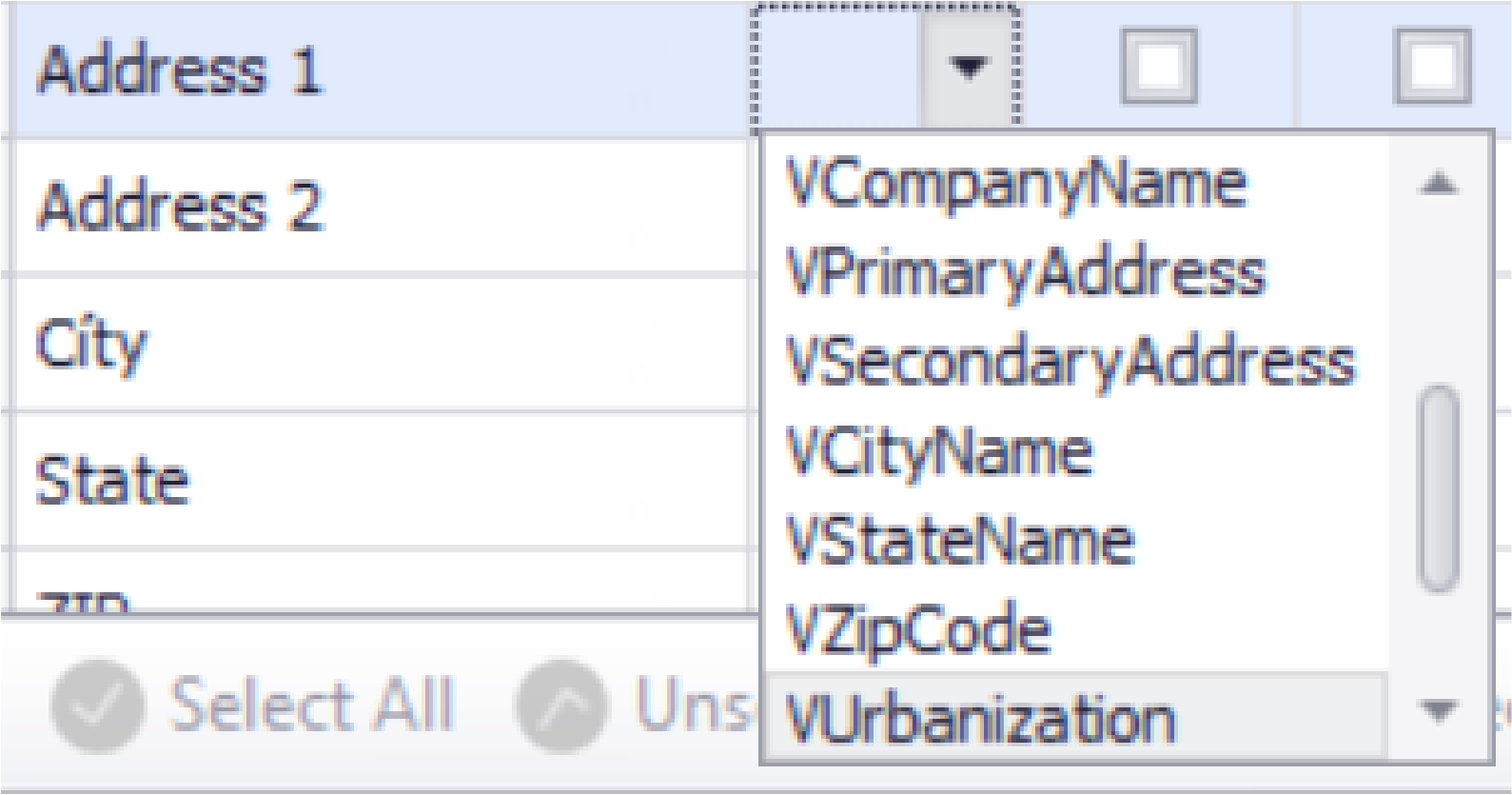
- Address and Company Validation: This feature is a premium feature and does not ship with the standard copy of DataMatch Enterprise. It is recommended to achieve the highest amount of validated addresses that the user applies as many “V” type addresses as possible. The minimum amount should contain a VPrimaryAddress and a VZipCode.
- Full Name: this will parse the full name located in the field into Prefix, First Name, Common name, Last Name, Middle Name, and Suffix.

-
- . If you plan on changing several aspects of a field you may want to make a copy of the field in order to preserve the original data.
- This option will reverse lower case to upper and upper case to lower.
- This will change all letters to upper case.
- This will change all letters to lower case.
- Proper case will make the first letter of every word begin with an upper-case letter while the rest of the word will be in lower case.
- This will remove all non-printable characters like carriage returns for example.
- If you wish to replace non-printable characters with another character, you can enter the value here.
- For empty (NULL) fields, you can add in a more meaningful value.
- Remove leading spaces to avoid issues with matching.
- Remove trailing spaces to avoid issues with matching.
- In this field, you may enter specific characters you wish to remove
- Characters to replace is an enhanced find and replace function that will allow you to create multiple rules.
- Remove spaces will remove all spaces before, after, and between the text of a field.
- Remove letters will remove any letters that might exist in a field.
- Remove numbers will remove any numbers that might exist in a field.
- Replace Zeros with O’s will replace the number 0 with the capital letter O.
- Selecting this will replace Capital O’s only with zeros.
- Pattern Builder (Based on Regular Expressions) – This feature is described on the Pattern Builder page.
- WordSmith® – It is described on the: WordSmith® page.
Want to see DME’s Data Cleansing and Standardization in action? Check out this video.


