































Does your data look like this?

Do you have data stored in Salesforce, Fusion, Excel, and other asset management systems?

 Do you have entries with mixed conventions, such as [Last Name, First Name] and [First Name, Last Name], across these different systems? Do you have duplicated entries for one entity? Do you have trouble getting insights, sales intelligence, marketing performance, and business reports on time, every time?
Do you have entries with mixed conventions, such as [Last Name, First Name] and [First Name, Last Name], across these different systems? Do you have duplicated entries for one entity? Do you have trouble getting insights, sales intelligence, marketing performance, and business reports on time, every time?
Have we got your attention?
These are the questions we’ve asked 4,500+ clients. The response unanimously points to poor data quality as the leading cause of business project failures, low customer retention rates, & chaotic operational processes.
Given that this is such a serious problem, over 80% of the companies we interacted with still did not have a data quality management plan in place.
This whitepaper will explain why you need a data quality management plan, how to create one using a data quality framework, how to use Data Ladder’s data quality tool as a component in the plan, and finally how to make data quality a long-term strategy.
Data quality is the key factor of business success.Typical causes of data corruption. Impact of poor data quality on business areas. Ascertaining data quality standards. How to set quality standards with data quality software. Using Data Ladder as a DQ tool.
Let’s dig in.
Data Quality as the Key Factor to Business Success
The modern world is data-driven. Unlike businesses of yesteryears, where decisions were made based on experience, gut instincts, and influence, today, companies rely on data to make effective decisions.
This means data is the key factor to business success –only – if it is accurate, reliable & fulfills its intended purpose.
A widely used definition of data quality by J.M. Juran, author of, Juran’s Quality Handbook summarizes the concept of data quality well:
“Data are of high quality if they are fit for their intended uses in operations, decision making, and planning.”
Key business operations, sales and marketing performance, ROI, and revenue are impacted by the level of data quality in the organization. More importantly, in this age of strict data compliance regulations, poor data quality can result in expensive lawsuits, penalties, and loss of business & credibility.
Moreover, as big data, predictive analytics, ML and AI make their way into business processes, companies are recognizing that their data is a critical intellectual asset that will decide their future. This recognition necessitates a focus on data quality.
Improving data quality improves business processes, translating to higher business success.
What Does Poor Data Quality Exactly Mean & What are the Typical Causes of Data Corruption?
Although data quality is a universal problem, there is no universally recognized definition of data quality.
In this respect, we can rely on our decade-long experience in data preparation and take the liberty to offer our own definition: data quality is the measurement of the usefulness of data.
For instance, data that is corrupt and rife with typos, duplicates, and missing information has a low degree of usefulness. It disrupts processes, causes flawed analytics and reports, reduces operational efficiency, and increases costs. Erroneous data is just one part of the problem. Data stored in silos or disparate systems, data that is obsolete, and data that no longer offers value in terms of insight and intelligence are problems that prevent data from being useful.
For data to be useful, it must be complete, coherent, unified, up-to-date, clean & accurate.

It’s quite possible that your data may be clean, but not updated or it may be unified, but not clean. You will have to conduct a data assessment to verify which characteristics are lacking.
Typical Causes of Corrupted Data
There is no one cause or form of corrupted data. It could be as simple a problem as data entry errors caused by manual keying in of data or it could be a complex problem as data stored in varying formats across several systems. Whatever the problem, it compounds when this data is needed for a migration or a merging initiative.
While organizations can have varying causes and forms of data corruption, in our experience, there are a few typical causes or origins of data corruption that are often overlooked.
These are discussed briefly below.
1. Poor Data Entry Practices
Data entry is the most obvious cause of poor data quality. If a company has no standards by which data is entered into the system, the data will soon become corrupt and unusable.
For instance, sales or customer service reps may have varying methods of entering a company name like General Motors. Some may enter it as GM, G.M.Motors or gm. If the organization operates at a global level, it is imperative to set data entry standards to ensure consistency.
Here’s an example of information on one entity, entered in multiple ways.
In the example above, poor data entry standards can result in confusion, skewed analytics, inaccurate information, and duplication of records.
These errors can result in direct costs of return mail, invoices, and other forms of communication. Worse, it can also result in contract breaches and an indeliberate violation of data compliance regulations.
2. Data Decay
On average, data decays at a rate of 30% per year, at 2.5 – 5% per month. The impact of this decay costs businesses millions annually. As people switch to new jobs, move to new places, or take up new names, the data entry you had for them in your database gets outdated and the customer record loses relevance – unless it’s updated and enriched regularly.
And changes happen rapidly. 18% of telephone numbers change annually. Americans move around 11.7 times in their lifetime. Email addresses decay at a rapid pace of 22.5% annually. Companies that don’t update their CRM in line with these changes, risk losing money, value & customers.

3. Mergers & Migration
A merger or acquisition often triggers system migrations that involve the transfer of customer data, financial data, inventory, vendor, and multiple other data sets. It is at this point that quality issues arise. Companies face a tough time matching old data to a new platform or interface. During this migration, issues with data standards, duplication, and other inconsistencies come to light. Typically, data needs to be cleaned, updated, and validated before loading to ensure completeness and accuracy.
4. Fragmentation of Systems
Companies today are connected to multiple tools, apps, and systems, each varying in terms of data structure, definitions, and standards. For instance, it’s not uncommon to see a company storing customer data in Salesforce, Fusion, and other asset management or ERP systems. This causes inconsistency, incompleteness, and the siloed storage of data, preventing the company from getting a consolidated, unified source of truth in their data. The consequence of such disparity can be seen in poor customer experience and service, failed personalization initiatives, and much more. Disparate data is a significant data quality struggle holding back companies from progress.

5. Too Much Data Collection
Data is only valuable if it is usable. Companies focus too much on collecting and storing data, with little emphasis on processing this data. The lack of resources, the right data quality tools, and organizational processes cause over half of this data to decay and become useless over time. Excessive amounts of data collection cause delayed processing time, with employees using shortcuts (thus creating further data quality issues) to finish reporting.

Impact of Poor Data Management on Business
Poor data quality impacts every aspect of a business – but its most disastrous effect is on its operational costs.
Take a look at the image below.
Click here to zoom in on the image

A Framework and a Methodology for Data Quality Assessment and Monitoring
Almost every area of your business is affected by the cost of poor data. From organizational efficiency to employee productivity, from customer retention to customer service, and logistics to lawsuits, poor data can ruin businesses.
A widely popular report by Gartner estimates poor data quality costs businesses an average of $9.7mil per year. Other general adverse effects that businesses suffer because of poor data management practices include:
Impaired productivity and growth as employees struggle to make sense of data. Expensive and ineffective business decisions based on flawed data. Poor customer experience, service, and relationships. Implementing failed business strategies. Reputation and credibility loss. Missed opportunities and competitive disadvantage. Difficult in setting and executing strategies. Penalties & fines caused by non-compliance to data regulations.
Up until a few years ago, data quality was never a priority in an organization. But as the world moves towards digitization, companies are realizing the need to step up and sort their data. Some have successfully identified poor data as the leading cause of low customer satisfaction and high costs – problems, which initially, were treated as a marketing or operational failure. This has led companies to create data quality standards and implement a framework to manage their data.
Ascertaining Data Quality Standards
By now, you know what makes data poor. In retrospect, what makes data good? How would you ascertain whether your lists or records are good, usable, and of high quality?
Here’s a set of standards widely implemented by organizations and data experts to measure and implement quality standards.
| Characteristic | Purpose | Examples | How to measure | Metrics |
|---|---|---|---|---|
| Accuracy | Data accuracy refers to the ‘correct’ values, records, or entries in your dataset. Inaccurate data such as the one given in this example will lead to catastrophic failures. For instance, you could accidentally send out a mass email addressing people’s last names instead of their first names. | Do your records accurately follow [Last Name, First Name] or [First Name, Last Name] conventions? | Crossmatch records. Representatives may often end up writing first names as last names and vice versa. | Ratio of data entry errors. |
| Completeness | A measure of whether the records are in their complete form. Address data is one of the most challenging quality issues when it comes to measuring for completeness. | Do your records have addresses with complete ZIP codes, city, and country names? | Verify and validate your data using an address validation tool. Incomplete addresses can result in high mailing costs. | Missing fields and values in a list. |
| Consistency | Records must reflect the same information across multiple systems or sources. | A CRM record shows Entity A as a Manager, while the ERP record shows the entity as an Executive. | Review data sets to verify the consistency of information. | The ratio of inconsistent information in a list when matched with other lists. |
| Timeliness | Data that is up-to-date and provides insights in real time. | A company making current market share estimations based on last year’s data or sales results. | Is your information giving you up-to-date insights? Is it reflecting market changes or shifts as it happens? | Number of obsolete, decayed records. |
| Validity | Records in the database must follow defined rules, standards, formats, and any combination thereof. | Do records across multiple systems follow consistent Date formats [YY/MM/DD] vs [YYYY/MM/DD] and time format [12hour] vs [24hours]. | Identify current data entry standards or business rules being followed and verify if the information follows the specific format. | The number of fields that do not meet business rules. |
| Uniqueness | The real, correct, single version of a record. | Duplication is caused by entering multiple variants of a single entity. John Doe, written as J.D, J.Doe, Doe John, or Johnny are duplicates with redundant, confusing information. | Use a match tool to check for duplications and dedupe data. | The ratio of duplicates in a record. |
Some additional, useful questions to ask may include:
How clean is the data? What are the most common problems with the data? What are some of the most challenging problems teams are facing when trying to use data? What systems or checks are in place to manage the problem of data quality? What kind of cleansing or data maintenance process is being followed? Can this data be trusted enough to give reliable information? Does the data perform the task that it was intended to? How can data quality standards be implemented and maintained across the organization? Is data affecting any of your core processes? How can the organization achieve a single source of truth?
Data quality standards are part of a long-term, mature effort to data quality management because they ensure you have a unified benchmark or approach to data collection, storage, and use.
How to Set Quality Standards with a Flexible Data Quality Solution
The ideal solution to data quality issues within many organizations comprises powerful data analysis technology, capable of identifying and resolving almost any data quality problem, without prohibitive initial investments or sky-high ongoing maintenance cost.
These solutions, optimized for processing massive data sets, use algorithmic techniques to consolidate disparate data, parse, match, consolidate, and normalize – among many other functions. Here’s an example of how a flexible solution will allow you to meet the quality characteristics or standards defined above.
| Characteristic | Metrics | Function | Purpose |
|---|---|---|---|
| Accuracy | Ratio of data entry errors. | Data profile, data match, data validation. | Assess accuracy by reviewing data for inconsistencies based on pre-defined business rules. Data match can be used to verify information across several lists or data sources. |
| Completeness | Missing fields and values in a list. | Data profile. | Verify which columns or rows are missing key fields such as missing phone numbers in the [Phone] token or missing middle names in the [Middle Name] list. |
| Consistency | The ratio of inconsistent information in a list when matched with other lists. | Data match, data deduplication. | Match data between or across lists to verify value and field consistency. |
| Timeliness | Number of obsolete, decayed records. | Data profile, cleaning. | Assess outdated data, clean, replace, or validate this data. |
| Validity | The number of fields that do not meet business rules. | Data standardization, data cleaning. | Set standardization rules such as changing from upper-case to lower-case, and implementing format and structural rules. |
| Uniqueness | The ratio of duplicates in a record. | Data deduplication, data matching. | Match lists and data sources to identify duplicates. Merge records to get a consolidated view. |
Manual methods work best when there are few records to check and when there’s a known accurate value. For instance, a sales rep verifying the phone and email addresses of 200 contacts manually makes sense. But for the same rep to evaluate thousands of records with duplication, validity, and accuracy issues will require a digital solution.
Data Ladder’s Data Quality Solution
Data Ladder is a flexible data quality solution that can be used to integrate data from over 500 sources, allowing you to clean, transform, match, and dedupe your data on a single platform. Our solution differs from generic analysis or native platform tools because it is built to address the multiple needs of data quality. Using a proprietary algorithm in combination with established algorithms, our solution lets you perform powerful data match while limiting high false positive rates.
Data Ladder is the only solution that offers data match, data cleansing, data standardization, data merging & survivorship, and data governance abilities in one platform.
Data Integration with Over 500 Sources
An average company uses 461+ apps which means companies have to cope with data streaming from multiple data sources. Data Ladder is the only service provider that gives companies an on-premises solution as well as direct integration to over 500+ data sources.
DME allows you to import data from virtually any data source, including but not limited to:
Files (Excel, Delimited Text File, Excel (97-2003), Fixed Width Text File) Databases (Direct integration with SQL Server, Oracle, Teradata, and many more) CRM (Integration with Salesforce, MS Dynamics CRM, Sugar CRM) Social (Integration with Facebook and Twitter) Services (XML and JSON) Other (ODBC or Email)

Data profile is always the first step to data cleaning. It allows you to assess the quality of your data and lets you discover information about your lists according to metrics as valid, invalid, filled, null, distinct, numbers, numbers only, letters only, numbers and letters, punctuation, leading spaces, non-printable characters, min, max, mean, median, mode, extreme. These units describe the overall issues with your master data.
Additionally, you can also use built-in expressions to assess your data as per your requirements. The solution also has a WordSmith tool that lets you replace the right word, name, or expression across your list.
Data Cleaning and Standardization
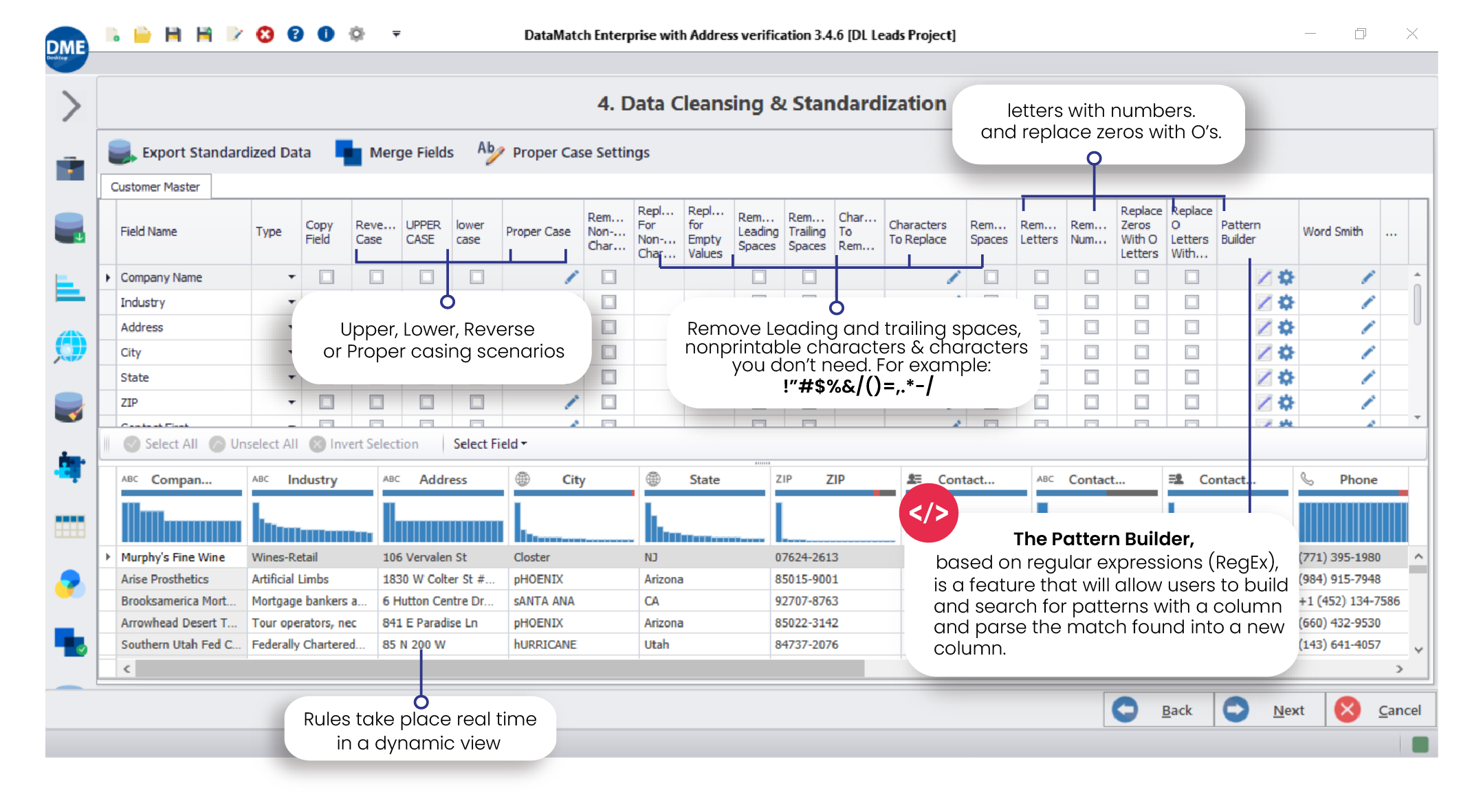
Data fields with inaccurate spellings, case settings, and other structural problems need to be cleansed and transformed.
DME’s data cleansing and standardization function allows users to:
Change cases and ensure that each field follows a defined standardization. Find and replace different characters. Choose whether you want to preserve abbreviations. Set your exceptions. Choose a delimiter that separates your fields such as tabs, commas, semicolons, etc. Remove spaces, numbers, letters, non-printable characters, zeros, and zeroes with letters.
Powerful Data Match with 100% Accuracy
Data Ladder is the only data-matching solution that has the highest matching accuracy rate at 96% when compared with other solutions in the industry.
Most data-matching solutions rely on fuzzy logic to match data, but DME has a unique proprietary algorithm that outperforms other solutions.
Define how you want to match data sources Choose the fields you want to map by the fields of your data list. Run multiple matching sessions simultaneously. Get matches based on exact, phonetic, numeric, and fuzzy matching techniques View match results and create a Master Record that you can use as a surviving record. Save and export your results for later review. Use a merge and survivorship option to overwrite data based on your criteria.
With our data match solution, you can:
Survivorship and Enrichment
Once you have performed the cleansing, matching, and fixing of your records, you can save them as a master record. DME allows for data survivorship and data enrichment where you can decide which record to use as the Golden Record. This is an ideal solution if you have customer info dispersed over several platforms or channels. With this option, you can merge specific fields of those other data sources and create a unified source of truth.
Export in Multiple Forms
DME allows you to export records in multiple forms. It supports CSV, Excel, SQL Server, MySQL, Apache, and Salesforce to name a few. Additionally, you can also choose to export all unique records with suppressed duplicates or you can export a master record for each group of duplicates.
Benefits of Using Data Ladder’s Solution
While many companies have developed data-wrangling solutions, they require a steep learning curve and are not meant for business or end-users. DME removes the dependencies on IT and empowers the business user to work directly with their data.
Designed to meet the data demands of the modern age, DME uses machine learning technology to learn from human input on what is & what is or isn’t a match just as well as human experts to automatically derive taxonomy and extract attributes from product data.
DME may be used in a variety of data quality initiatives – ranging from data migration to mergers & acquisitions, data integration and consolidation to data cleaning and standardization. The solution allows business users to transform data and make it usable within weeks instead of months or years. In an age where real-time data accessibility is the demand, organizations cannot afford to wait months to clean and match this data.
Additionally, users can also experience:
An on-premises platform that can be used on the cloud, servers, and the desktop. A CASS-certified Address Verification system that gives the user flexibility to add government databases and dictionaries for address verification. Integration of structured and semi-structured data from multiple sources. A strong Master Data Management (MDM) foundation.
With data quality projects of government institutions and Fortune 500 companies that involve millions of data records in multiple data structures, Data Ladder’s solution is designed to handle complex data and high volumes of transactions – rapidly and efficiently.
DME will allow your company’s organization resources to focus on high-value jobs where they will implement data quality standards through strategic decision-making – all while significantly reducing operational costs.
Data Ladder’s Solution in Action – Case Study: Amec Wheeler, Mastering and Maintaining Data Quality
Company Profile
Wood Group has combined with Amec Foster Wheeler to form a new global leader in the delivery of project, engineering, and technical services to energy and industrial markets.
Business Situation
In a merger and acquisition process, Wood Group acquired Amec Wheeler in 2017. The merger propagated the urgent need for improving data quality and accuracy. With the increasing demands of the environmental engineering industry, the company was in strong need of streamlining its business processes for the upcoming influx of projects and human resources tasks. The company was in the process of migrating to a new finance and HR system and knew the quality of their data needed improvement before going to the next important step.
Solution
Using DataMatch™, Data Ladder’s flagship data software, the company was able to manage its deduplication efforts. With the large task of migrating all of their existing financial and human resources information to a new system, they also plan to use DataMatch™ to clean and repopulate their systems. In the past, managing vast amounts of data was a challenging and costly process, and strained the companies’ IT resources. The firms identified the need for a robust data quality solution that could help them do the following without increasing costs:
Keep the data accurate. Maintain a high level of data quality needed to migrate into their new financial and HR system. Speed up the deduplication process. Implement an automated data-cleaning process.

Results

Data Ladder’s technology allowed Wood Group and Amec Wheeler’s IT team to achieve:

Maintain a high level of data quality needed to migrate into their new financial and HR systems.

Speed up the process of deduplication through fuzzy matching algorithms. It took the company just three weeks to match and clean millions of customer data.

Consolidation of disparate data sources into a unified source of truth.
Conclusion
To remain competitive & be ahead of the curve, businesses must ensure their data assets follow the tenants of data quality standards. The data must be complete, valid, accurate, and up-to-date to be of use to the organization.
By proactively identifying and working on data quality, organizations can take immediate action to stem and remedy data quality issues. Unlike yesteryears, today, organizations have the benefit of using powerful ML-based automated tools to keep their data quality clean, reliable, and usable.
Data Ladder enables organizations of all sizes to efficiently and cost-effectively manage their quality for greater business success, growth, compliance, and improved business performance.
Essentially then, the true essence of transformation is not systems, but data, which is the soul of a system.


