































Last Updated on January 11, 2026
A data cleansing tool is perhaps the most powerful and yet the most underestimated solution. Companies spend millions of dollars in procuring cloud solutions and expensive databases, but, flinch when it comes to purchasing a data cleansing solution.
In our experience, over 80% of companies we’ve worked with were unsure of the functionalities of a data cleansing tool and how it could help them overcome their data quality challenges.
Hence, in this quick piece today, we’ll give a brief explanation and cover commonly asked questions like:
- What are data cleansing tools?
- How do you do data cleansing?
- What do you mean by data cleaning?
- Why is it important?
Let’s get started.
What is a Data Cleansing Software or Tool?
Before we talk about the tool, let’s talk about the problem aka bad data.
If you’ve ever taken a look at your company’s customer data, you’ll notice that it’s literally messy.
Here’s a sample:
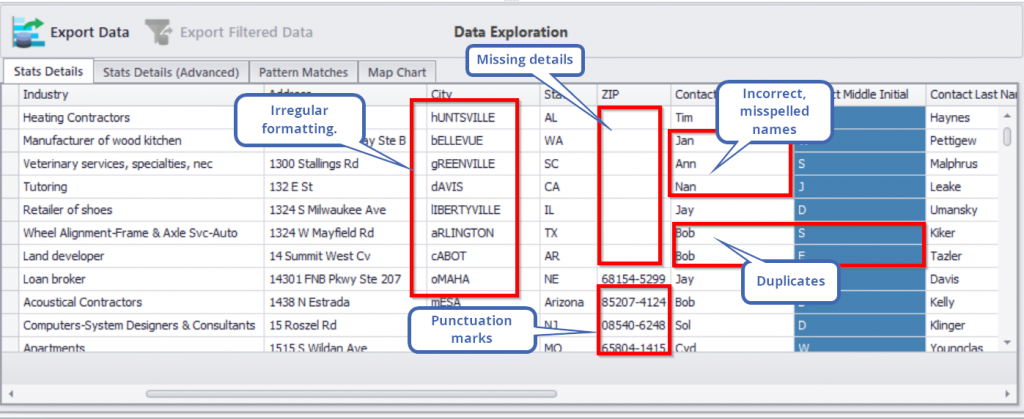
At the time you’ll need this data for marketing, promotional, or strategic decision-making purposes, you’ll be wasting critical time fixing these problems. Worse, you might not even be able to use the data.
It’s not possible to manually fix these errors. Sure, you can hand it over to IT, but IT is just going to make the problem worse. IT does not understand the sensitivity and nature of data like business users do. Eventually, you’ll end up spending more time than necessary in coordinating with IT, reviewing changes, and delaying your goals.
This is where the need for a data cleansing software comes in.
A data cleansing tool is an easy-to-use solution designed for business users. It’s an important, must-have software that allows you to fix all the data quality issues as shown above. A best-in-class data cleansing software like DataMatch Enterprise does much more than cleaning though – it allows you to remove duplicates from multiple data sources, cross-match data, merge data, standardize, and optimize your current data.
You can do all this *without* the help of IT resources, right on your desktop. It will also take under just an hour to clean and sort through a million rows of data. That saves you on time, effort, and money.
How Do You Do Data Cleansing?
Traditionally, data cleansing was done manually. In fact, in some organizations today, you’ll still find people solely dedicated to extracting data, fixing it by breaking it into multiple segments, running Excel functions to filter and sort out duplicates or inaccuracies.
Companies that use SQL have dedicated programmers and resources who know the language to clean entries. This leaves business users out of the loop and dependent on the SQL programmer’s timeline.
Where a data cleansing software easily helps you join two data sets, in SQL, you’ll have to run queries as the following to merge two tables.

select id, name, dept_name from
student_metadata s join department_details d
on s.dept_id = d.dept_id;
Source: DataCamp
Not only is this extremely time-consuming, but also impractical when it comes to resolving complex data challenges.
In the age of big data, things are complicated.
Your CRM data no longer consists of just a few hundred rows of basic contact information. Today, it might consist of behavioral data, social data, digital data, transaction data, and much more. Depending on the needs of your organization, you might have even more complex data sets that cannot be cleansed with the traditional methods and requires advanced CRM data cleansing techniques.
Large multinational brands use expensive solutions like Informatica, Oracle or IBM Match 360 to resolve their data quality issues – but here’s a resounding fact; not every company has the budget to purchase a solution from these guys. Oracle’s solution alone costs over $200K and you have to use multiple tools to get the results you want.
So for the mid-level businesses, there are little options left other than to try to do manual cleaning or to outsource to third party resources who will use Excel sheets and its functions to clean basic data issues. This is why a solution like DataMatch Enterprise is the perfect fit for organizations that want a tool on their desktop or cloud server to get the job done minus all the complications and unnecessary flair that comes with other solutions.
What Does Data Cleansing Exactly Mean?
Cleaning your data from spelling errors, resolving format issues, deduplicating duplicate data and ensuring you have error-free data.
By now you know you have messy data and that it needs to be cleaned. You also know how traditional methods are used to clean data. But when it comes to a software, how is data cleansing done?
Let me explain this by using DataMatch Enterprise’s framework.
Profile Your Data to See Problems Affecting It: You cannot clean data if you don’t know what’s wrong with it. You can use Excel functions to identify incomplete rows and columns, but you can’t use it to highlight specific columns that have non-printable characters, or that have numbers in name fields and letters in number fields. These are problems that do not often come under the radar, but become major obstacles when you need to use the data.
So the first part of data cleansing is to actually identify the problems affecting your data. Once you’re able to identify issues, you can then move on to cleaning or scrubbing it.
Dealing with Duplicates: Messy data is an easy problem to deal with. The real problem are deep duplicates. As data complexity increases, so does duplicates. Every time a customer enters a different email, number or address, a duplicate will be formed. Moreover, when you combine customer data from different departments, you will end up with duplicates.
Some duplicates are easy to weed out, most are not. You will need solutions that use a combination of fuzzy matching algorithms to identify probabilistic duplicates (Cath and Catherine may be the same people, but they don’t have the exact names and are considered as probable duplicates). DataMatch Enterprise uses a combination of fuzzy algorithms and established proprietary algorithms to scan through your data sources and identify duplicates with an accuracy rate of 95%. No other solution can provide you with this level of accurate duplicate identification – not even IBM or SAS.
Cleaning and Standardizing Data: This is where the main cleaning process takes place. While traditionally, you had to manually create rules to clean data, now you can just click on pre-defined rules.
Take a look at the image below.
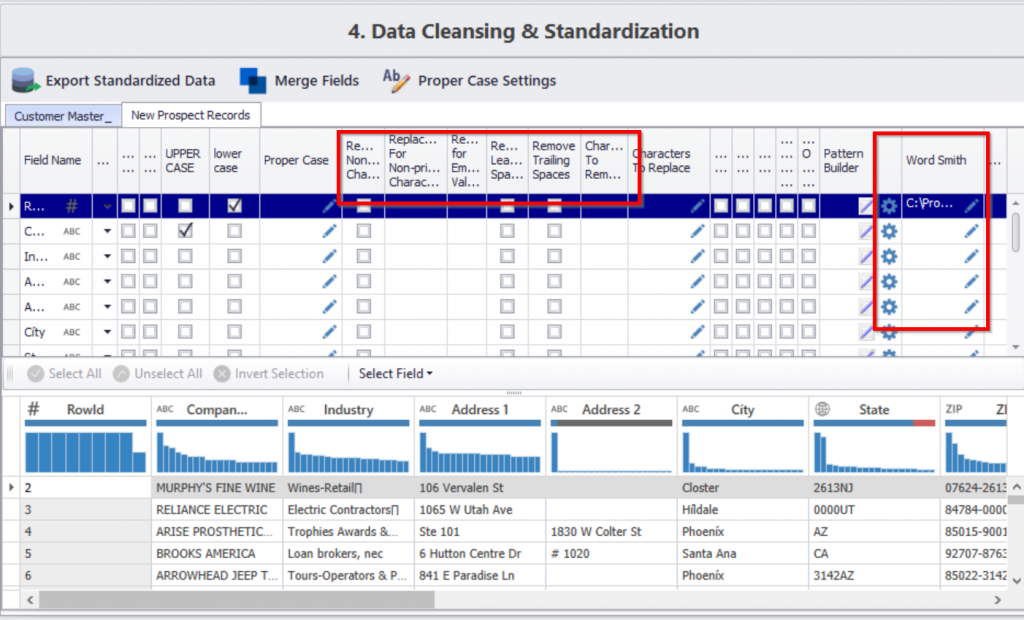
See how it’s easy to turn all upper cases to lower cases, removing negative spacing, replacing characters, etc? This kind of task would take months if done manually – not to mention, you will need to run queries and codes for each task. There’s also the WordSmith feature that allows you to automatically replace names and words within your directory.
Once you clean all this messy data, you can then create standardization rules. For example, you can set controls on your lead forms to make it mandatory for users to fill in ZIP codes, or to allow only business emails as contact addresses. Getting a preview of the problems affecting your data allows you to place controls wherever possible to prevent the data from being affected by the same problems repeatedly.
And now finally, moving towards the last question.
Why is it Important?
Stating the obvious here, but bad data impacts your reports, insights, analytics and operational efficiency. Infact, bad data impacts every aspect of your organization. You just don’t realize it.
Here’s how the circle goes:
Bad data enters system >> Business users cannot use data >> Connects with IT to resolve >> IT does not follow business timelines >> Business and IT have a tussle >> Goals are delayed >> Employees are burdened with cleaning up data by doing them manually on spreadsheets >> Errors are missed >> Data is put to use because goals need to be met >> Customers get the brunt of dirty data >> Complaints are filed >> Money is lost >> Employees are blamed >> Jobs are lost >> Back to square one.
Your employee morale, your goals, your customer satisfaction, your operational efficiency is ALL affected by bad data. This is not even considering ROIs, annual reports and insights or the cost of bad business decisions because of flawed data.
And the antidote to all of these problems? A powerful data cleansing tool.
Clean your data. Talk to us.
[WD_Button id=7841]

