































Last Updated on December 29, 2025
Would you trust a skyscraper built on a cracked foundation? That’s the risk businesses take when they invest in BI and analytics programs without first fixing the cracks in their data. Every business insight, decision, and strategy depend on data. But dirty, inconsistent, or siloed data can topple even the most ambitious digital transformation initiatives, which is why data transformation should be your top priority.
Without trustworthy data, every investment in digital tools is a gamble your organization can’t afford to take. Therefore, before you invest in analytics tools or cloud solutions, you must fix your data to lay the solid, reliable foundation needed for stability and growth.
A Few Statistics to Push You into Action
Here are some statistics that highlight why most companies are struggling to become truly data-driven and why they must prioritize data quality:
- 49% of data practitioners reported that their organizations have suboptimal data quality or no active data quality strategy at all.
- 91% of a research participants agreed that data quality has some level of impact on their organization, yet only 23% view it as part of their organizational ethos.
- 42% organizations don’t have metrics to measure data quality, and 41% report that their data quality strategy only applies to structured data, leaving much of their data pipeline unchecked.
These figures illustrate the persistent and critical gaps many organizations face when it comes to building a reliable data-driven culture. Despite ramping up their efforts, issues like the above make it difficult for companies to trust and fully leverage their data.
What is Data Transformation & Why You Need to Prioritize it Over Everything Else?
Businesses today are dealing with an unfathomable amount of raw data, from social media apps, marketing and sales campaigns, and advertisements to market research activities, sales funnels and so on. All this raw data holds immense potential, but only if it’s properly “transformed” into information.
Data transformation refers to the process of converting this raw, unstructured data into structured, actionable insights. The purpose is to ensure that the data is usable by data scientists and business intelligence tools. This is a multi-step process that involves:
- Identifying flaws in existing data, such as inaccuracies, gaps, or duplications
- Integrating data from disparate sources into one unified view, often referred to as the “single source of truth”
- Cleaning and fixing data issues like missing values, typographical errors, and inconsistencies
- Deduplicating data to remove redundancies
- Mapping the data to business intelligence (BI) tools for data analysis
- Preparing data for migration or other digital transformation purposes
While this process may sound simple in theory, in practice, data transformation is a hectic process that involves a significant investment in data transformation tools, consultation with third-party service providers and a buy-in from C-level executives. On average, it takes businesses at least a year of deliberation to take the necessary steps for data transformation.
Yet, without transforming your data first, any investments in analytics, cloud solutions, or digital tools is not worth it. Inconsistent or low-quality data undermines the accuracy and effectiveness of these solutions. That’s why prioritizing data transformation is a prerequisite for sustainable growth.
The Two Basic Approaches to Data Transformation
When it comes to data transformation, companies typically adopt one of the following two approaches:
1. The Manual Approach: Creating an In-House Team to Hand-Code ETL Solutions
A traditional method, the manual data transformation approach is still used by some organizations today, causing them to fail miserably. The complexity and volume of data today make it practically impossible to create ETL scripts for each data source. Not only is this manual code generation a time-consuming process but it is also counterproductive. Teams have to spend months and years modifying scripts to match with increasing demand. Yet, they often fail to achieve the level of accuracy that is required for data to be efficient. Unintentional errors, misunderstandings, mundane and repetitive tasks make this approach an expensive failure for most organizations.
2. The Software Approach: Getting an On-Premises Data Preparation Tool
On-premises software solutions allow companies to prepare, transform, integrate, and merge data from multiple sources into a new, master record. Compared to the manual approach, this automated approach requires a short amount of time. It also consumes fewer resources and requires only one person to manage the entire process. Hence, it is cheaper than hiring a full-fledged team. It also ensures more accurate data. Some tools, like Data Ladder’s DataMatch Enterprise, have an easy user-interface that allows non-IT users to match, clean & merge data without requiring any additional language expertise.
With an automated software solution, the data transformation process becomes faster and more reliable and also frees up resources for other strategic initiatives. This approach is crucial for optimizing data warehousing systems, where efficiency and accuracy are key to creating centralized, actionable insights from various data sources.
How to Convert Your Raw Data into Useful Information? 6 Key Data Transformation Methods
Data transformation techniques are the foundation of effective data analysis, as they help to refine raw, inconsistent, or incomplete data into usable formats. There are various data transformation methods available. Below, we discuss the six widely used ones, their purpose, and how they contribute to enhancing data quality and usability:
1. Data Smoothing
Data smoothing is a technique used to reduce noise or fluctuations in data while retaining its core trends. This method is particularly useful in time-series data, where outliers or short-term variations can obscure underlying patterns. Techniques such as moving averages, exponential smoothing, or regression models are often applied. For instance, in stock market analysis, smoothing can help data analysts better understand price trends without the distraction of daily fluctuations.
2. Attribution Construction (Feature Engineering)
Attribution construction (or attribute construction) involves creating new attributes or features from existing data to improve its analytical value. For example, in e-commerce, raw data on customer behavior (e.g., page visits and clickstreams) can be transformed into derived attributes such as “time spent per page” or “conversion rate.” These engineered features make the data more meaningful for predictive modeling and analytics.
3. Data Generalization
Data generalization simplifies data by replacing low-level data values (e.g., transactional details) with higher-level concepts (e.g., monthly summaries or customer categories). This is particularly useful for data mining or summarizing trends. For instance, instead of analyzing every transaction made by a customer, businesses can generalize this data into metrics like “average monthly spending” or “purchase frequency.”
4. Data Aggregation
Data aggregation involves consolidating data from multiple sources or granularity levels into a unified summary that provides a holistic view of the data. This method is critical for businesses dealing with large volumes of data from multiple departments or systems. For example, sales data can be aggregated at the product-level, region level, or timeframe (daily, monthly, yearly) to support strategic decision-making.
5. Data Discretization
This data transformation technique converts continuous data into discrete categories or data intervals to make it easier to interpret or analyze. For example, income values might be discretized into categories such as “low,” “medium,” and “high.” Discretization is particularly important for classification models, where grouping similar data points can simplify predictions and improve model performance.
6. Data Normalization
Data normalization ensures that data is scaled consistently, eliminating biases caused by differences in units or ranges. For instance, in a dataset containing customer age, income, and spending, normalization can scale all values between 0 and 1 (or to a standard distribution), ensuring that no variable dominates the analysis. This technique is particularly valuable in machine learning, where consistent scaling is critical for algorithm performance.
Five Fundamental Steps to Prepare Your Data for Transformation
Data transformation involves multiple processes and each process is designed to help businesses meet a certain data goal. For instance, some businesses may already have a data cleansing mechanism in place and only need an integration solution to consolidate their data onto one platform in order to establish a unique source of truth, while others may have raw data that must be cleansed and standardized before it could be integrated.
In essence, your data transformation needs are dependent upon the current state and quality of your data quality and the objectives you aim to achieve.
Generally, if you don’t have a data quality framework in place, your data will need to undergo five basic processes to be transformed. These steps ensure your data is clean, organized, and ready for downstream processes. They include:
1. Data Cleansing
Raw data is dirty data. In fact, any data that is collected by a system and has not been processed or analyzed for use tends to be dirty data. Left unchecked, these issues degrade data reliability and usability.
When we talk about raw data it means any data that is:
- Plagued with spelling errors, typos, numeric & punctuation issues and much more.
- Duplicated several times in one data source or over multiple data sources (if an organization has multiple departments storing varying forms of information of an entity)
- Incomplete, inconsistent and inaccurate. Fake names, email addresses and physical addresses are some of the most common data quality problems.
Data cleansing is the first step in data transformation. You cannot do anything else until your data is cleansed of basic errors that give it a ‘bad health.’
You can get more information on data cleaning in our extensive 101 Data Cleansing Guide.
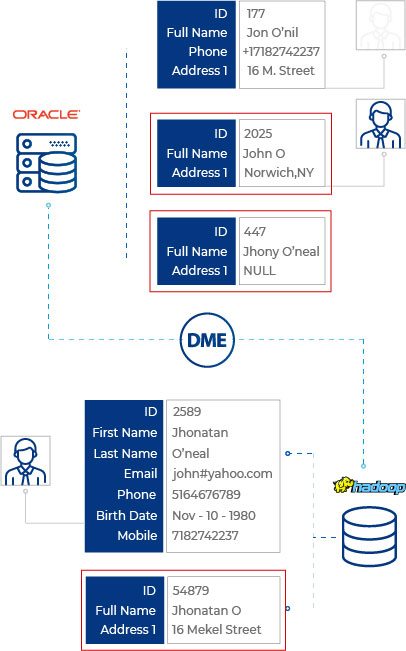
2. Data Deduplication
Duplicate data is a classic problem with most organizations. It’s the most common problem we’ve had to encounter with even Fortune 500 clients. A leading retailer, for example, had a troublesome time managing product data that arrived from multiple vendors and third-party dealers. With different unique identifiers, data formats and data sources, product lists were badly affected by poor data quality.
Similarly, organizations that have customer data stored siloed away in multiple data sources often have problems with data duplication. If sales, marketing, billing are collecting the same customer data in three different ways, chances are data duplication will occur exponentially. Comprehensive deduplication ensures your data is unique and consistent and thus, prevents redundancy and inefficiency.
3. Data Standardization
Although the lack of a unified data format may not seem significant, in the long run, it causes the most severe bottlenecks especially during data migration. If your new CRM has strict data standardization rules in place (such as all names must start with capital letter or all phone numbers must start with country + city code), you’ve got a serious problem to deal with. If the data in your organization is being collected and entered manually by different people using different formats, it will need to be converted into a standardized format to be processed.
Standardizing ensures uniformity across systems and allows for smooth processing and accurate analysis. Seemingly inconsequential, data standardization is often missed out by organizations until they need to run a data matching activity only to realize that the data match algorithm misses out on information that does not have exact characteristics.
4. Data Validation
Is your source data accurate? Is it complete? For example, do you have accurate address data? Do you have more fake phone numbers and email addresses than valid addresses? Data validation is the process of ensuring that you have accurate, reliable data.
When moving data, it’s imperative that data from different sources conform to business rules of the new source or system and not become corrupted due to inconsistent data. Data validation ensures this.
5. Data Consolidation
Data stored in disparate sources is one of the most critical challenges organizations face today. For an average enterprise to be connected to over 1,000 applications, the amount of data streaming in is unfathomable. To make sense of all this data coming in from different sources and stored in different databases, companies need a solution that can let them merge or consolidate this data to get a single source of truth.
For many of our clients, data consolidation is the key to their personalized customer engagement strategies. For example, Bell Banks, a renowned financial institution, achieved its customer engagement goals through an effective data matching and data consolidation process. The bank was able to identify the journey of its customers across multiple services and were able to consolidate information from disparate sources to get a 360-customer view. Not only did this help them with personalized customer engagement but it also enabled their teams to get business intelligence that was used for initiating new strategies.
The Comprehensive Six-Step Process of Data Transformation
While the foundational steps above prepare your data, a broader six-step data transformation process delivers the actionable, accurate insights organizations need. This structured framework ensures that raw data evolves into a strategic asset. It includes:
1. Data Discovery
Begin by analyzing your data landscape to understand its structure, sources, and quality issues. Identify gaps, redundancies, and inconsistencies that must be addressed.
2. Data Mapping
Define how your data flows between systems, and ensure that all formats, fields, and relationships are aligned for seamless transformation. Plan how the data will be modified, matched, filtered, and aggregated to meet the target format or analysis goals.
3. Data Extraction
Extracting data means retrieving raw data from various sources, such as on-premises databases, cloud applications, or third-party platforms.
4. Code Generation and Execution
Create and execute scripts (in languages like SQL or Python) to apply the necessary operations to modify, clean, standardize, or deduplicate your data. This stage builds on the foundational steps outlined earlier to ensure data is accurate and usable.
5. Validation
Conduct thorough checks to verify the transformed data aligns with predefined quality standards and business rules, is complete, and adheres to any relevant regulatory requirements.
6. Delivery
Load the transformed and validated data into its target system – whether that’s a data warehouse, business intelligence platform, or operational database.
This end-to-end process not only refines your data but also ensures it is strategically positioned to power decision-making and drive business success.
How Can Data Ladder Help You Achieve Your Data Goals?
Data Ladder, being a data quality solutions provider has helped over 4,500 businesses in 40+ countries with data management. Over the past decade we’ve realized that for most businesses, the greatest bottleneck in achieving digital transformation or operational efficiency lies in poor data management.
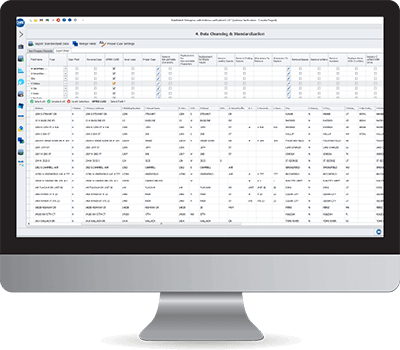 With our solution, businesses can:
With our solution, businesses can:
Transform Data through Data Cleansing & Preparation Tools:
Data Ladder’s flagship software DataMatch Enterprise allows for easy, efficient data cleansing and preparation across multiple data sources.
Match Data to Remove Duplicates at a 95% Accuracy Rate:
In the world of data matching, accuracy rates matter. DataMatch Enterprise is the only best-in-class solution that offers an accuracy rate of 95%. Our data matching process is designed to help businesses achieve two goals – remove duplicates and consolidate or merge multiple data sources.
Standardize & Validate Data:
Being a CASS certified solution, DataMatch Enterprise can be used to verify and validate address data. Based on pre-built business rules, users can use the Data Standardization option to create uniformity and consistency across, between, and within data sets.
Data Integration & Merging to Create Master Records:
Integrating data from multiple sources can easily be done using the over 150 data integrations options provided by our solution. The software also lets users create master records of their file mergers and matches which can then be used as the final version of the truth.
Automated Data Cleansing:
For enterprise-level companies, data cleaning is not a one-time process. It needs to happen regularly and consistently. To achieve this purpose, an automated solution is needed. DataMatch Enterprise lets its users schedule automated cleaning schedules based on their preferred date and time or their needs. This ensures that data cleaning happens even when data managers are not around or miss a cleaning deadline.
Data Transformation is Essential!
Data transformation is no longer an option – it’s the need of the hour (of the age?). Organizations that want to be digitally empowered and data-driven must have data they can trust. This can only happen when companies shift their focus from investing in new cloud solutions and CRMs and instead focus on getting their data sorted first because without quality data, your digital transformation projects are bound to fail.
At Data Ladder, our mission is to help businesses unlock the full potential of their data and ensure their transformation initiatives succeed. With a focus on quality, consistency, and accuracy, we provide the tools you need to turn your data into a powerful asset for driving business success. Download a free trial today or book a demo with an expert to learn how Data Ladder can assist you in converting data into useful information.

