































Last Updated on January 28, 2026
As companies are spending billions of dollars investing in big data with the hopes of turning data into money, the need for efficient, easy-to-use data preparation software, solution, and tools are equally rising. It’s becoming increasingly difficult for businesses to data prep using traditional methods especially now that big data is highly complex in nature. Basic ETL procedures no longer do the job. Hence the need for a powerful, top-in-class data prep tool.
This quick guide on data preparation will help data science newbies, experts, business users and decision-makers understand the data preparation process better, it’s importance in our business environment and how a best-in-class solution can help you achieve your data prep goals. We’ll be covering in-depth answers to questions as:
- What is Data Preparation?
- Why is Data Preparation Important?
- How do You Prepare Data?
- Challenges to the Data Preparation Process
- Key Benefits of Data Preparation
- Best Practices
Let’s dive in!
What is Data Preparation?
The standard definition of data preparation is:
“The process of gathering, combining, structuring, and organizing data.”
But data preparation in the age of big data is more than just organizing data.
It’s a necessity that fuels decision-making.
It’s a requirement to make sense of $65 billion investment in big data analytics.
It’s also a much-needed new approach to self-service data preparation, enabling business users to be able to optimize their data for its intended use.
In practice, data preparation is a workflow made up of:
- Data profiling: Assessing your data to see the nature and extremity of problems; such as unstructured fields, missing values, misspelled names, excessive typos, use of non-printable characters etc.
- Data cleansing: Using pre-defined business rules to clean up messy data.
- Data deduping: Duplicates are a severe problem to tackle. While you can manage messy data, it is duplicate data that can cause unforeseen havoc.
- Data validation: The process of verifying or validating your data with authority standards. For example, validating address data with that of the USPS.
- Data transformation: Turning messy, raw data into usable, clean data.
- Data merger and survivorship: Merging multiple data sources to create final master records.
The image below is an example of the kind of bad data for which you will need a data preparation solution to resolve.

Each of these sub-activities is a complex process that takes days and months to accomplish. This is one of the reasons why data scientists end up spending 80% of their time just fixing data. Despite massive investment in big data analytics, companies are still struggling to prepare their data.
It must be noted that data preparation is not a simple matter of running your data sets using a tool or software.
In theory, data preparation involves:
- Identifying a problem
- Acknowledging the problem
- Understanding how the problem impacts business
- Assessing an organizational approach to data quality
- Analyzing current data strategy
- Implementing a data quality plan
- Shifting the dependencies from IT Team and enabling business users
In our experience working with Fortune 500 companies, we’ve seen that companies that are aware of the underlying business problems with data are likely to be successful with data preparation. These organizations know the problem and its impact on the business. On the other hand, organizations that did not assess, understand and acknowledge the problems with their data found it difficult to make data preparation succeed.
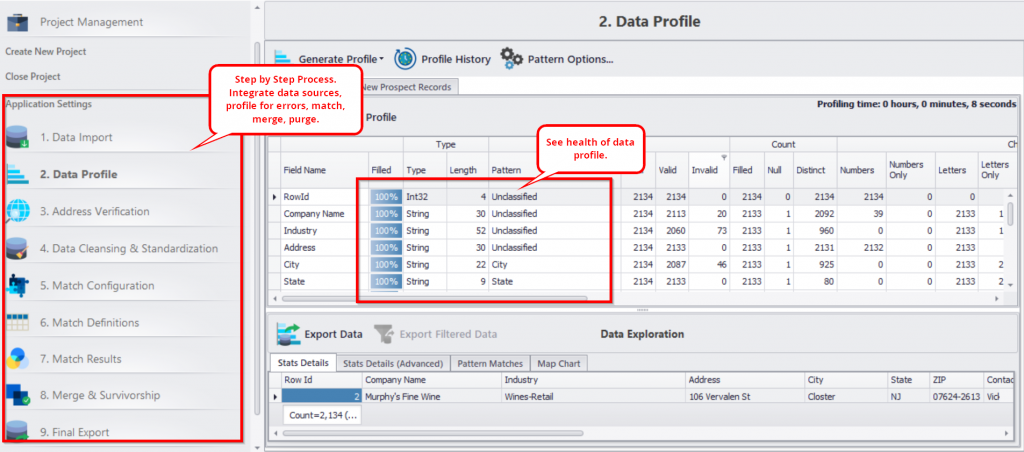
Here’s an overview of the data preparation process used in DataMatch Enterprise, Data Ladder’s flagship data preparation tool.
Identifying the Need & Asking the Right Business Questions
As odd as it sounds, data preparation does not exactly start with data – it starts with identifying a need in corporate decision making. It starts with understanding how a certain set of data impacts marketing strategies, resource deployment, product distribution, and every other area of corporate operations. Making informed and correct business decisions are the paramount business need that operates on information – if the company does not have access to this information, it is doomed.
When it boils down to asking the questions though, it’s necessary to be precise. You cannot have a blanket approach to data preparation or data quality.
You cannot fix a million customer records just because you want clean data. The cost of data discovery and preparation should not be greater than the value gained or the effort is not profitable.
There needs to be a goal.
The goal needs to be tied to profitability & efficiency.
There needs to be an assessment of the data and its ability to support that goal.
The goal should help answer business questions as:
- Are we making money with this goal? (A new product, a new promotional activity, a new marketing goal etc.)
- Does this goal help us succeed with customer satisfaction or even acquisition and retention?
- Why are we trying to achieve?
- How will we measure success or failure of a project?
- What tools or resources do we have to carry out this goal?
- What additional tools or resources will we require and why?
- What will the cost of those tools and what is the ROI we expect from the expenditure?
As a rule of thumb, start with a business question, come up with a hypothesis, perform an exhaustive analysis of the impact of your decisions and finally map out the conclusions to your business equation.
Understanding Your Data
Before you can even begin executing a business strategy, you need to understand your data.
- Do you have raw, untreated data?
- Do you have technically correct but duplicated data?
- Do you have clean usable data to work with?
- Do you have siloed data from disparate sources?
- Do you have a selection of the type of data you will need for this goal?
- Do you need to integrate large data sources such as social media, transactional or behavioral data to get a unified view of your customers?
- Do you have a robust data preparation software that can let you work with your data on your cloud or server domain?
It’s important to mention three common challenges that companies usually face when it comes to preparing their data for its intended use. These can be resolved by a data preparation solution, however, you will need to measure the scale of the activity and the type of training or learning curve you will need to use the software. Many companies spend millions just to have trained specialists work on a data preparation software, therefore, be sure of what you need to get done before investing a hefty amount in a popular data quality solution.
Why is Data Preparation Important?
Although everyone talks about data preparation, no one does anything about it. After identifying your goals or the problems to solve, data preparation is the, key to solving the problem. It’s easily the difference between success and failure, between usable insights and unintelligible text, between what is informed decision and useless assumptions or theories.
For instance, one customer had to use their data to launch a customer personalization strategy. The organization considered itself as data-driven because it had made data lakes to store household data of its customers and now wanted to use that data to offer personalization services. While they were aware of raw data issues, they weren’t prepared to deal with the excessive number of duplicates and garbage that rendered nearly 40% of their data useless. Before initiating their personalization goals, they had to first prepare and clean their data.
So while companies have huge data lakes they eventually become data garbage dumps because the initial thought was ‘more data is better.’ This approach no longer works. You need data preparation and its sub-activities to ensure that you have usable data to work with.
If not, the lack of clean data could result in:
- Operational inefficiency: Teams and processes will be affected as they won’t have the right data set to work with and contribute to the goal.
- Poor customer satisfaction: A company mismanaging data can result in embarrassing mistakes and missed opportunities that will result in poor customer satisfaction.
- Unnecessary costs: The consequences of mismanaged data will result in all kinds of costs that could be detrimental to your business – legal fines, data security problems, data compliance penalties, return mails, lost customers, and so on.
- Stunted growth: It’s a dynamic market out there. If you’re not banking on data, you won’t be able to grow. Futuristic companies focus on optimizing their data.
- Flawed insights: Almost every company is engaged in some form of data modeling for insights and analytics. Inaccurate data that has not undergone a data preparation process will be the cause of flawed insights – the consequences of which we know all too well.
In its simplest form, data preparation helps us understand the information in data that we cannot understand just by looking at it. That’s all. And that’s the most important purpose of this activity.
How Do You Prepare Data?
Data preparation has largely been a manual effort. After a data set is selected for use, it is run through a data preparation software where specific operations are applied to the files. For instance, one of these operations may involve manually removing text data in a number field for which formulas or a combination of functions will be used. While this worked for small and not-so-complex data sets, today, as data volume and complexity is increasing, data scientists are finding it exceedingly frustrating to spend most of their time just preparing this data.
Chances are your organization is already using an ETL process to make sense of data, however, ETL is highly restricted and does not allow business users to make use of their data efficiently. Read the following post to know the difference b/w ETL and data preparation.
For this reason, there has been an increase in the number of software vendors over the years. Most of these tools now deliver a self-service feature where business users too can get involved in the data preparation process.
A tool like DataMatch Enterprise, for instance, simplifies the data preparation process by taking the user through a workflow that allows them to easily clean, dedupe, and merge data – a process that usually takes days and months would take just a few minutes.
Data preparation tools also make it easier to handle inconsistent data stored in silos. A few decades ago, you would have to fix the data in its individual system and try to merge parts of this data manually and still fail to get the analysis you’d need.
Now, you can easily integrate unlimited data sets, merge them, purge them, prepare them as you deem fit. It’s like a drag and drop activity, requiring very limited technical expertise.
Challenges to the Data Preparation Process:
While data preparation has been made easy, the challenges to data preparation remain the same, if not more complex and troublesome. Some of the key challenges companies must deal with are:
Data in Silos and Disparate Sources: Companies now want to create unified customer views to create personalization experiences or to get an overview of hidden opportunities. For instance, a retailer wanted a consolidation of data from multiple data sources to deliver a smooth digital experience to their shoppers coming from different European regions.
But data consolidation from multiple sources is not an easy deal. Data stored in disparate sources variate in structure, form and purpose. More importantly, data errors varied culturally. Italian names for example were often misspelled more frequently than American names. It takes a significant amount of time to prepare this data and make it useful for the retailer. Even if a data preparation tool is used, there will be still some manual effort in reviewing names from different cultures and ensuring that no mistakes are made.
Duplicate Data: Almost every company we’ve worked with reported data duplication as a major roadblock to their data preparation success. While there are dozens of data preparation tools out there that lets you fix data anomalies, very few have the capacity to fix duplicate data at a 100% matching rate. In fact, data matching is an in-demand solution with very few vendors making it to the 95% accuracy match.
A government institute we worked with discovered that their in-house data deduping solution could only do half the job of removing duplicates. When they used DataMatch, they were able to remove an additional 40% of duplicate data.
Inconsistent Data: Aka dirty data. The quality of data is always dubious as long as it’s humans typing in customer names and addresses, product codes, and prices. Inevitably, manual methods result in mistakes that takes a considerable amount of manual effort to resolve. It’s even more complicated and messy when you have to combine corporate data with external data from third-party sources. For instance, a customer’s social media data is anything but consistent. Some may use abbreviations in their names, some may use an alternate name…the list goes on.
These issues have pushed the rise of self-service and cloud-based data preparation software that allows users to integrate data from multiple sources, create business rules in accordance with their data requirements and bring together IT and business users to solve data quality issues.
Best Practices for Data Preparation
Now that the world is moving towards AI, machine learning, and business intelligence goals, it needs to focus on preparing data to meet these goals. Using a data preparation software or tool though is only part of the solution. You will need to incorporate additional practices for data preparation that must include:
- Making Data Quality a Priority: The problems and challenges in data preparation is caused by the lack of focus on data quality. Companies may talk about data quality but they don’t make it an organizational focus. You’ll keep fixing the same mistakes repeatedly unless you rectify the source of the problem. For instance, your sales team is messing up data quality as they enter inaccurate information, leave out important information, or make human errors while entering data. To curb this, your team will need to be trained on data quality, helping them understand the impact of a typo or missing information on downstream processes.
- IT Can Facilitate Business Users with Training & Learning Sessions: This is a good way to bridge the gap between IT and business users. IT can plan data quality training and learning sessions to help business users understand the importance of data quality and data preparation. As business users become familiarized with the problem, authorized users can be equipped with the right data preparation tools to start preparing their data for business use without depending on IT.
- Follow the Data Preparation Process: If you’re using a data preparation software like DataMatch Enterprise, you go through a step by step process that takes your data from its raw to its final stage in 8 modules. If you’re not using a tool and are implementing it on your own, make sure to follow the workflow given below
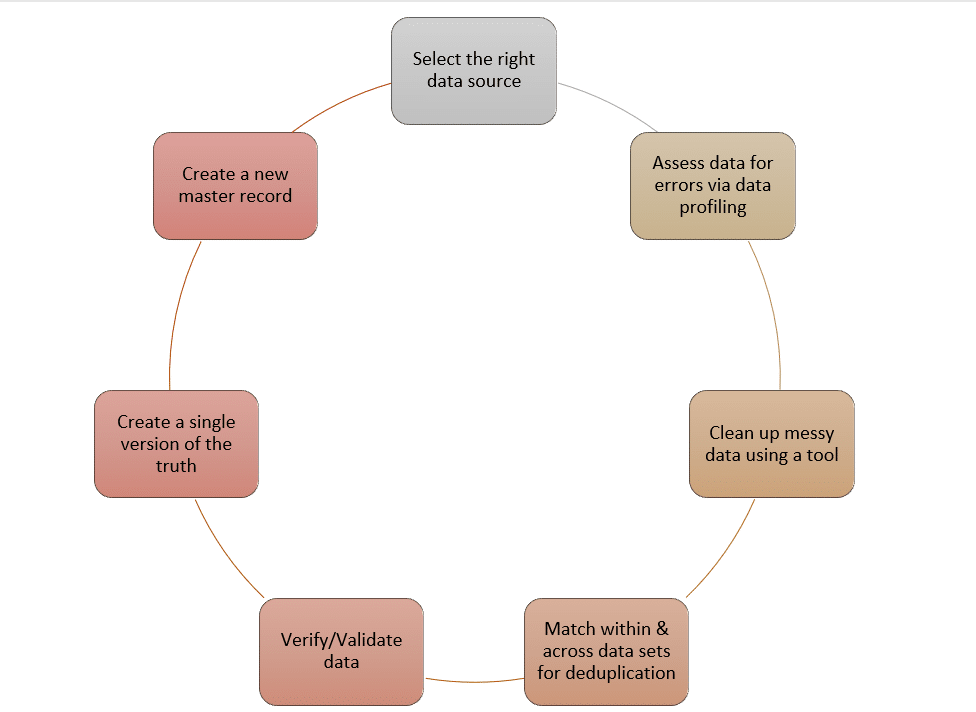
The task is huge. But any smart organization will know that the goal is not a 100% perfection or a blanket approach. The goal is to ensure a data quality culture and approach where problems are prevented before they become difficult nuisances.
Conclusion
Data preparation is only part of the first step of data management, and while there are powerful data prep tools to do most of the hard work, companies will still require humans to verify, validate and ensure the outcome is as desired. It’s important to acknowledge that tools are only as smart as the humans using them. Since the future is AI and ML, it’s imperative that companies begin a focused approach in data preparation, turning their data into fuel that drives the organization forward.

How best in class fuzzy matching solutions work: Combining established and proprietary algorithms
Start your free trial today
Oops! We could not locate your form.

