































Last Updated on January 13, 2026
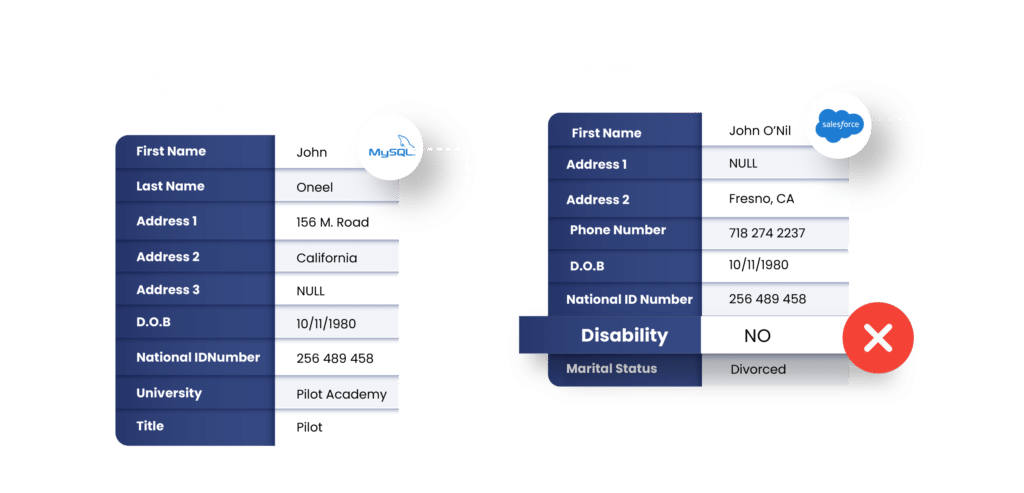
If record linkage were as simple as matching names and emails, organizations wouldn’t be sitting on mountains of unleveraged data.
In real enterprise environments, naïve matching rules break down fast because teams are often asked to link records across systems that were designed independently, without a shared or reliable identifier. They may have CRM data with missing identifiers, operational systems that disagree on basic attributes, or legacy sources where key fields are blank, outdated, or unreliable.
Linking records under these conditions is one of data management’s highest-risk activities. But critical business decisions depend on it. Customer 360 initiatives, compliance reporting, fraud detection, and master data programs all assume that fragmented records can be resolved into a single, trustworthy view.
This is where record linkage techniques become a hard operational requirement. The techniques an organization relies on determine whether downstream systems are strengthened by linkage or weakened by false matches and missed connections.
What Challenges Do Organizations Face in Linking Similar Records with Incomplete Data
In theory, record linkage most often fails because data is “messy.” But in practice, it fails for much more specific and predictable reasons.
Most enterprise datasets don’t suffer from a single flaw. They suffer from combinations of gaps, inconsistencies, and design limitations that compound each other and make simplistic matching unreliable. Understanding these failure modes is essential before choosing any record linkage techniques. Here are the most common ones:
Missing or Unreliable Identifiers
Unique identifiers are often assumed to exist. But in reality, they are frequently:
- Missing in older or migrated records.
- Populated inconsistently across systems.
- Reused, overwritten, or repurposed over time.
When identifiers can’t be trusted, linkage has to rely on descriptive attributes that were never meant to function as keys.
Partial and Asymmetric Records
It is also common for data records to have different missing values. This asymmetry makes one-to-one comparison impractical and forces teams to work with incomplete evidence.
Variants, Typos, and Formatting Differences
Names, addresses, and free-text fields rarely appear in a single canonical form. Typos, abbreviations, transliterations, casing differences, and inconsistent tokenization are common, especially across systems built by different vendors or teams.
With these issues, records that refer to the same entity may look different enough to defeat exact matching, while overly permissive logic increases the risk of false positives.
Conflicting Attribute Values Across Systems
Even when field values exist, they don’t always agree. There may be differences in name formats or ordering, multiple addresses for the same entity, or conflicting dates, titles, or classifications.
Contrary to how it may appear, these conflicts are rarely random. Most often, they reflect differences in data capture rules, validation logic, and business context, all of which standard matching logic tends to ignore.
Scale and Performance Constraints
At enterprise scale, linkage isn’t just about accuracy. It’s also about ensuring the process can be implemented at scale. Millions of records can’t be compared pairwise. That’s why it becomes essential to introduce blocking and indexing techniques and those decisions directly affect recall.
These constraints introduce architectural trade-offs that shape linkage outcomes long before scoring logic is applied.
Precision vs. Recall Balance
Linking similar records always involves uncertainty. The real question is where errors are acceptable. Different use cases tolerate different risks, but many linkage implementations fail because this distinction is never made explicit.
When Not All Records Should Be Linked and Why
Not every similar-looking record should be linked. Over-linking can be just as damaging as missed matches. It can introduce false positives that contaminate analytics, compromise compliance efforts, and erode trust in master data.
In regulated or high-risk environments, it is often safer to preserve uncertainty and route ambiguous cases for review than to force a match that cannot be defended later.
Common Data Issues and Their Impact on Record Linkage
Challenge
Why It Happens
Business Impact
Missing identifiers
Legacy systems, migrations, optional fields.
Forced reliance on weak matching signals.
Asymmetric & variant data
Systems capture different attributes; manual entry, typos, formatting differences.
Reduced confidence in similarity scores; missed matches or inflated false positives.
Cross-system inconsistencies
Different validation rules and data models.
Conflicting similarity scores.
Scale constraints
Large datasets, compute limits.
Aggressive blocking reduces recall.
Undefined error tolerance
No agreed precision/recall targets.
Misaligned outcomes across teams.
Core Record Linkage Techniques – What Actually Works with Incomplete Data
When data is incomplete, the success or failure of record linkage has less to do with which technique you choose and more to do with how well the chosen technique aligns with the realities of your data. Many linkage initiatives fail because the methods are applied outside the conditions they were designed for.
Below are the core record linkage techniques used in enterprise environments, and how they behave when identifiers are missing, attributes are inconsistent, and systems disagree:
1. Deterministic Matching (Rule-Based Record Linkage)
Deterministic matching relies on predefined rules, such as exact matches on one or more fields. For example, ‘match records where email addresses are identical,’ or ‘where name and date of birth matches exactly.’ In practice, many deterministic implementations use hierarchical or rules-priority matching, where high-confidence rules are evaluated first before broader criteria are applied.
This approach works well when identifiers are stable, consistently populated, and governed by strong validation rules. It is also favored in regulated environments because match logic is transparent and easy to audit.
However, deterministic matching degrades quickly when data is incomplete. Missing or null fields immediately disqualify otherwise valid matches. Formatting differences, abbreviations, or system-specific conventions can cause false negatives. To compensate, team often relax rules, which then increases the risk of false positives.
Practical Takeaway: Deterministic matching is best used as a high-confidence layer within a broader strategy, not as the sole mechanism for linking records with incomplete data.
Probabilistic Record Linkage
Probabilistic record linkage is a foundational technique in modern entity resolution that enables organizations to resolve identities across systems even when no single identifier can be trusted.
Rather than requiring exact matches, it accepts partial agreement and uncertainty as part of the decision process.
Many modern implementations are grounded in probabilistic frameworks such as Fellegi-Sunter model which formalizes how agreement and disagreement across attributes contribute to match likelihood.
This technique performs well in environments where identifiers are missing or unreliable and where attributes such as names, addresses, or phone numbers are inconsistently populated. By balancing evidence across multiple fields, probabilistic approaches can recover matches that deterministic rules would miss.
The challenge here, however, is the configuration and governance. Poor attribute selection, inappropriate weighting, or poorly calibrated thresholds can produce unstable results. Without clear precision and recall targets, different teams may interpret match scores differently, which then leads to inconsistent outcomes.
Practical Takeaway: Probabilistic linkage is one of the most effective record linkage techniques for incomplete data, but it must be tuned, monitored, and governed to remain trustworthy.
Fuzzy Matching and Similarity Algorithms
Fuzzy matching techniques measure how similar two values are rather than whether they are identical. Common examples include string similarity measures used to compare names, addresses, or other free-text fields.
These techniques are especially useful for handling typos, spelling variations, abbreviations, and transliterations. In incomplete datasets, fuzzy matching often provides critical signals where structured identifiers are missing.
However, if used in isolation, fuzzy matching can be misleading. Similar-looking values do not always represent the same entity, and aggressive similarity thresholds can significantly increase false match rates. The quality of preprocessing and standardization directly affects outcomes here.
Practical Takeaway: Fuzzy matching is a powerful contributor to linkage decisions, but it should support broader scoring logic rather than act as a standalone decision-maker.
Blocking and Indexing (Enabling Record Linkage at Scale)
Blocking and indexing are sometimes misunderstood in discussions around record linkage techniques. They are not methods for determining whether records match. Instead, they determine which records are even compared in the first place and how efficiently those comparisons can happen at scale.
Blocking works by grouping records into candidate sets based on selected attributes, such as shared prefixes, geographic regions, or normalized tokens, so similarity scoring can run efficiently.
Blocking is unavoidable in environments with millions of records. Without it, probabilistic or fuzzy comparisons become computationally infeasible.
On the flip side, blocking can also be risky. The risk is that overly strict blocking criteria can silently exclude valid matches before scoring begins. When data is incomplete, relying on a single blocking key can dramatically reduce recall, especially if that key is missing or inconsistently populated.
In practice, blocking decisions shape recall before matching logic is ever applied, which makes them as consequential as scoring models in incomplete data environments.
Indexing supports this process by making candidate retrieval and comparison performant at scale. Poor indexing doesn’t usually reduce match accuracy directly, but it can make otherwise sound linkage strategies impractical to run in production.
Practical Takeaway: Blocking is essential for record linkage at scale, but in incomplete data environments, it must be designed carefully and evaluated for recall loss, not just performance gains. Indexing ensures those comparisons remain operationally viable as data volume grows.
Hybrid and Ensemble Approaches
In practice, the most reliable record linkage techniques are not single methods but deliberate combinations of deterministic rules, probabilistic scoring, fuzzy similarity measures, and carefully designed blocking strategies.
Hybrid approaches acknowledge that different attributes contribute different levels of confidence and that no single signal is sufficient when data is incomplete. Deterministic rules can anchor high-confidence matches, probabilistic models can resolve ambiguity, and fuzzy matching can recover signal from messy text.
The trade-off, however, is complexity. Hybrid record linkage techniques require clearer governance, better monitoring, and shared agreement on what constitutes an acceptable match. Without these controls, complexity can undermine trust rather than improve accuracy.
Practical Takeaway: For incomplete, cross-system enterprise data, hybrid approaches are the most resilient option when implemented with clear ownership and accountability.
Record Linkage Techniques at a Glance
Technique
Best Fit
Strenghts
Limitations with Incomplete Data
Deterministic matching
Clean identifiers
Transparent, auditable
Breaks when keys are missing
Probabilistic linkage
Partial, noisy data
Balances recall and precision
Requires tuning and governance
Fuzzy matching
Text-heavy attributes
Handles variants and typos
Threshold-sensitive
Blocking and indexing
Large datasets
Enables scale
Can reduce recall silently
Hybrid approaches
Complex enterprise data
Most resilient overall
Higher implementation complexity
Why Record Linkage Strategy Determines Entity Resolution Success
Record linkage and entity resolution are closely linked, but they are not the same thing. Record linkage refers to the mechanics, i.e., how records are compared, scored, and connected when identifiers are missing or unreliable, whereas entity resolution is the process of establishing a single, trusted representation of a real-world entity across systems.
When linkage strategy is weak, the impact cascades. False matches and missed connections undermine single source of truth initiatives, distort Customer 360 views, weaken master data management programs, and introduce risk into analytics and compliance reporting. Strong entity resolution is not achieved by downstream tools alone. It depends on linkage decisions that hold up under incomplete, inconsistent, enterprise-scale data conditions.
How High-Performing Teams Implement Record Linkage with Incomplete Data
Understanding record linkage techniques is only half the battle. In practice, outcomes are shaped far more by how those techniques are operationalized than by the theory behind them. High-performing teams tend to follow a few consistent implementation patterns that reduce risk, improve accuracy, and make results defensible.
Here’s what that involves:
- Standardize aggressively before matching.
- Separate similarity scoring from match decision.
- Design blocking and scoring together.
- Define acceptable precision and recall up front.
- Apply human review only where ambiguity exists.
A practical end-to-end workflow usually looks like this:
Clean & Standardize
Block / Index
Compare Attributes
Score Similarity
Review if Needed
Link or Merge
How to Evaluate Record Linkage Solutions for Incomplete Data
There’s no universally “best” set of record linkage techniques. The right solution depends on how incomplete your data is, how the results will be used, and what happens when matches are wrong. Teams that evaluate record linkage software through this lens make better long-term decisions that those that choose based on algorithm labels alone.
Key Evaluation Criteria:
- Data Adaptability: Can the solution handle missing, inconsistent, or asymmetric data across multiple sources without relying on rigid assumptions?
- Scalability and Performance: Can it maintain accuracy at enterprise scale and adapt to one-time, batch, or continuous linkage requirements?
- Accuracy and Risk Management: Does it allow configurable precision-recall trade-offs, confidence thresholds, and risk-based review for ambiguous matches?
- Explainability and Compliance: Can match decisions be explained and audited to satisfy governance or regulatory requirements?
- Operational Ownership: Is the platform maintainable and tunable by data and business teams without requiring constant reengineering or specialized expertise?
Platforms designed specifically for real-world data issues (such as those supporting hybrid matching, configurable blocking, and explainable scoring) tend to outperform rigid or single-technique solutions over time. This is where Data Ladder’s data matching tool, called DataMatch Enterprise (DME), stands out for how well it operationalized record linkage under real-world data conditions.
How DataMatch Enterprise Supports High-Accuracy Record Linkage
DataMatch Enterprise (DME) is designed to operationalize record linkage techniques under real-world data conditions, where identifiers are missing, attributes are inconsistent, and scale constraints matter. It offers:
Configurable Match Logic and Scoring
DME allows teams to define match criteria across multiple attributes using exact, fuzzy, phonetic, and numeric comparisons. Fields can be weighted differently, and match thresholds can be adjusted so similarity scores reflect the relative importance of each signal rather than treating all attributes equally.
Support for Hybrid Matching Strategies
DME combines multiple data matching algorithms so high confidence matches, and ambiguous cases can be handled differently.
For example, deterministic rules can be used to capture high-confidence matches, while similarity-based scoring helps surface potential matches when identifiers are missing or inconsistent. This layered approach reduces reliance on any single attribute and supports more resilient linkage outcomes on incomplete data.
Explainable Match Decisions
Each match decision is transparent and auditable, which supports governance, compliance requirements, and cross-team trust in linkage outcomes.
Enterprise-Scale Performance
DME is built to handle large, multi-source datasets efficiently. It allows both batch and ongoing linkage without sacrificing accuracy as data volumes grow.
Conclusion & Next Steps for Decision-Makers
Linking similar records with incomplete data is not a problem solved by any single technique. It is solved by choosing the right combination of record linkage techniques, applied with a clear understanding of data conditions, risk tolerance, and long-term governance needs.
Organizations that acknowledge uncertainty, design for it, and govern it explicitly are far more likely to maintain trust in downstream systems. Those that don’t often discover the cost of poor linkage only after credibility erodes.
If your team is assessing current linkage outcomes, planning a new implementation, or validating whether existing approaches still meet today’s data realities, a structured assessment or pilot can surface gaps quickly and reduce downstream risk.
Get in touch to see how DataMatch Enterprise can help you link similar records with incomplete data. You can also try it on your own buy downloading a free record linkage software trial.

