






































Identify gaps, outliers, duplication levels, and structural inconsistencies in your data. Catch problems
before they corrupt training data or skew automated decisions.
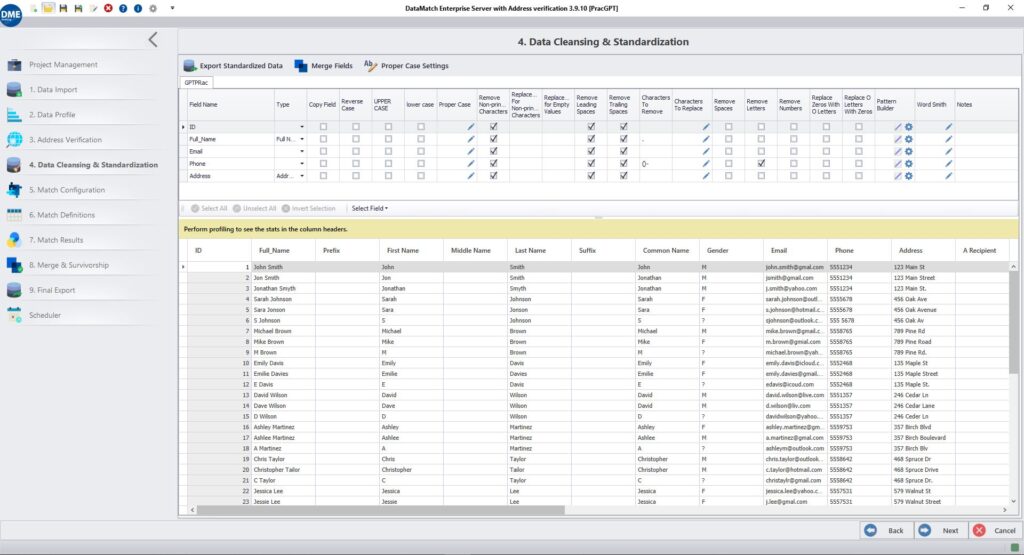
Standardize formats, clean text values, and apply consistent rules for how your data should look toensure uniformity before data hits your model or process
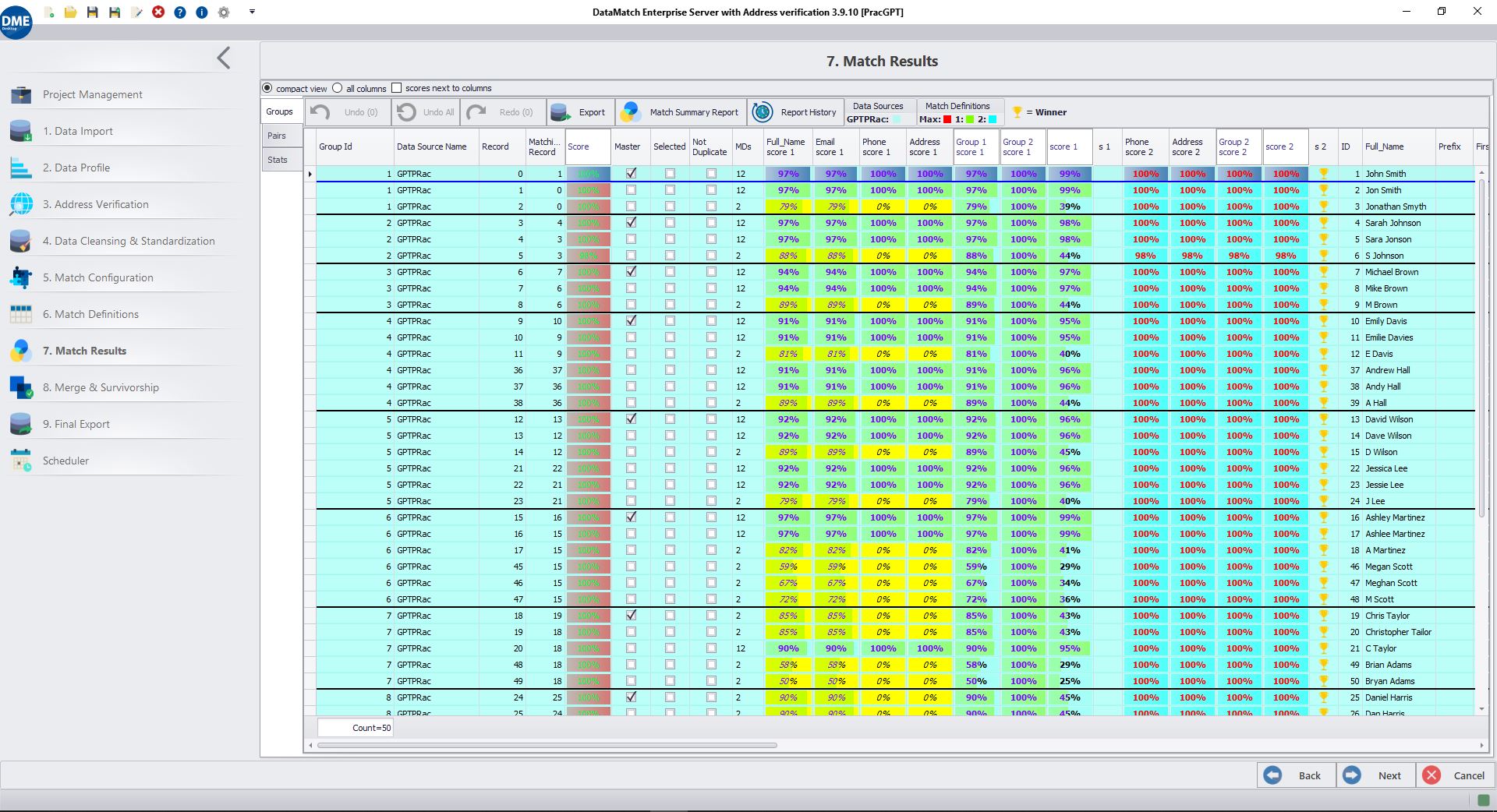
DME uses fuzzy, phonetic, numeric, and domain-specific logic to resolve duplicates and unify recordsacross sources. It helps you identify and link records that refer to the same thing even if the names,spellings, or formats don’t exactly match.
Role-based access, survivorship rules, match previews, and traceable changes ensure your AI workflows remain transparent, secure, and compliant.
Most AI models – especially in supervised learning – rely on labeled data. But if that data is inconsistent, incomplete, or duplicated, your model won’t learn the right patterns. You’ll end up training AI on flawed assumptions, which leads to bias, poor predictions, or even failed rollouts.
DataMatch Enterprise helps you solve these issues before labeling begins. By cleaning, matching, andstandardizing records upfront, DME ensures your training datasets are accurate, consistent, and readyfor annotation. That means:
• Less time spent labeling redundant or unclear data.
• Better inputs for supervised learning
• Higher-quality predictions from your AI models.
Whether your team is labeling data in-house or working with an external annotation partner, DME improves the input layer, so your AI model learns from the truth, not noise.

Reduce manual cleanup time from days to just hours – and hours to minutes.

Improve matching accuracy by up to 96%

Build trust in reports, models, and decisions.



Merging Data from Multiple Sources – Challenges and Solutions

Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 20, 2026 Enterprise databases run duplicate rates between 5 and 10 percent, based on figures the American Health Information Management Association
9 Best Fuzzy Matching Software for Data Teams in 2026
Last Updated on July 7, 2026 Fuzzy matching software identifies records that likely refer to the same real world entity even when the text doesn’t
Best Data Deduplication Software for Enterprise Data: A Record-Level Comparison (2026)
Last Updated on July 20, 2026 Enterprise databases run duplicate rates between 5 and 10 percent, based on figures the American Health Information Management Association
9 Best Fuzzy Matching Software for Data Teams in 2026
Last Updated on July 7, 2026 Fuzzy matching software identifies records that likely refer to the same real world entity even when the text doesn’t
Post-Merger Customer Deduplication for Two Customer Databases Without Losing Data Integrity
Last Updated on July 3, 2026 When two companies merge, their customer databases merge in name only. The same customer often exists under different account