































The Statewide Longitudinal Data Systems (SLDS) grant allows State educational agencies to, “design, develop and implement statewide, longitudinal data systems to efficiently and accurately manage, analyze, disaggregate, and use individual student data.” The fundamental goal is to use accurate and timely data to make data-driven and informed decisions at all levels of the education system.
The SLDS Data System Framework
The SLDS data system relies on accurate information to be efficient. For this purpose, a framework was designed to describe the components necessary to build and support the system in such a way that facilitates stakeholders, agencies, partners, and SLDS staff to achieve key objectives.
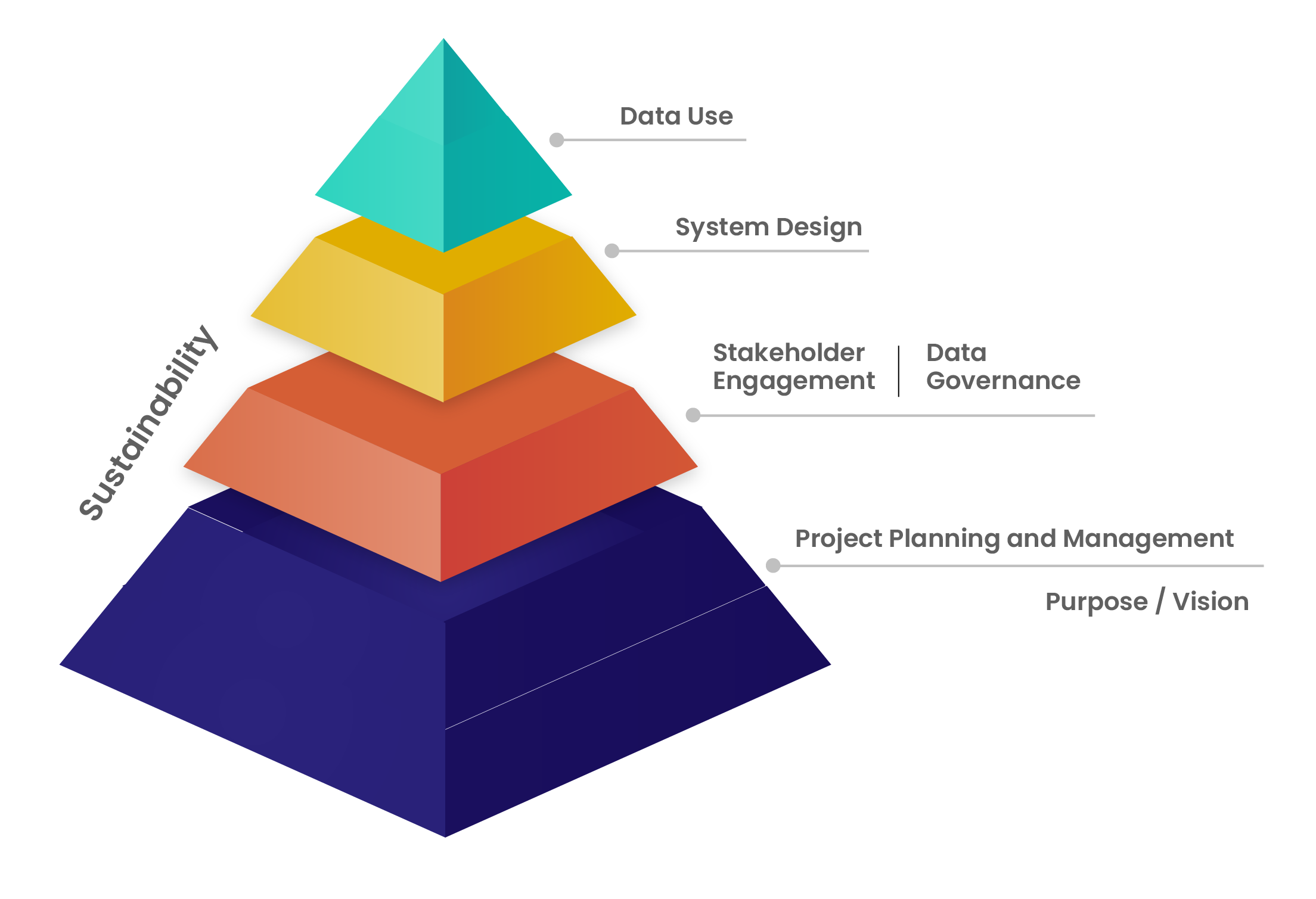
At the heart of this framework lies the critical function of record matching between and across multiple agencies to report on required reforms. But a key challenge with record matching is the restriction on using a unique identifier to identify a student individually which means states and agencies have to use methodologies that ensure the records are an accurate representation of the individual. These records include an individual’s history, demographic characteristics, grades, transfers, dropouts, etc. As this data is shared between or across agencies, the chances for duplication and erroneous data are high; making record-matching and identifying resolution two of the most crucial challenges that states have a hard time resolving.
Accurate Record Matching & Identity Resolution for P-20W Data
P-20W data (data that is collected from pre-kindergarten until the individual joins the workforce) is one of the most challenging aspects of the SLDS system. It is here that record linkages need to be built for which record or data matching and identity resolution are the most critical functions. Because the information is vast in nature and comes from multiple data sources, the quality of data is bound to degrade.
Most states do not have a robust mechanism or tool to verify the quality of data acquired, and neither can it help them meet an accurate match rate. This in turn affects the objectives of the SLDS system, because this system relies on reliable, consistent and verifiable data to be trusted and useful.
Some states have taken it upon themselves to develop a data match process, but as in the case of this one state that was also a client of Data Ladder, the in-house matching solution missed half of the matches. With their existing program, the sample found that 22 percent of the 5,344 students in that city had gone on to higher education. After using Data Ladder, that number went up to nearly 41 percent, nearly double the first figure.
Match Rate as an Important Indicator of Data Quality
The match rate – defined as the level of accuracy with which a state can identify records for the same individual across multiple agencies is a key indicator of the quality, completeness and usefulness of longitudinal data.
For the match rate to be accurate, states will have to take care of several factors. These include:
 Identifying gaps in the data collection process.
Identifying gaps in the data collection process.
Identifying common data error occurrences.
Setting up data governance policies.
Set up a data cleaning/fixing process.
Invest in a data preparation and matching tool.
Automate the data cleaning/fixing process.
Record-matching is not a one-time process and will require departments or agencies to consistently perform the function as each source of data will have its own set of matching rules due to differences in data elements.
Each state involved in the SLDS program has its approach and methodology to record linkage, however, almost all of them share some common limitations including:
Time: For everyone involved in the process, agencies, schools and SLDS staff alike, ensuring that data is obtained, formatted, stored and correctly matched is a time-consuming process. Not to mention, the process needs to be refined and repeated for every batch of data obtained.
Incomplete & Inaccurate Data: For everyone involved in the process, agencies, schools and SLDS staff alike, ensuring that data is obtained, formatted, stored and correctly matched is a time-consuming process. Not to mention, the process needs to be refined and repeated for every batch of data obtained.
Lack of a Flexible Tool: Most data matching tools in the market do not offer a powerful or accurate data-matching solution. Even if they do, the tools are enterprise-driven and are more focused on big-data technologies rather than on data matching.
These problems hinder the SLDS from achieving its intended objectives of using data to create reports, publish insights & make reforms in the education industry.
How the Connecticut State Department of Education Used Data Ladder for a P20-WIN Data Matching Process
While some states such as Texas and Washington have their own data match process, other states, such as Connecticut are trying out commercial solutions to determine the quality of matches. In a bid to evaluate their record-matching process, Connecticut tested and evaluated data-matching tools in order to select a data-matching utility for its SLDS. The chosen data matching method would be used to match K12 and post-secondary data based on name, date of birth, high school and a non-universal student identifier. Furthe, r it will also be required to match student data to workforce records based on partial names and social security number. For this purpose, a test plan was initiated to evaluate in-house and vendor-produced matching tools using fabricated data modeled on real-life matching instances.
The Test Criteria:
In order to evaluate the Data Ladder tool, the SE developed a file of student data to match with data from the National Student Clearinghouse (NSC) using the NSC’s proprietary algorithm.
The match process was divided into two phases:
The first phase was to match SDE student data to NSC data.
The second phase was to match the same SDE student data to enrollment data from the Board of Regents for Higher Education (BOR). The BOR data was selected so that the output file would contain individuals who were 21 years or younger during the 2009-2010 academic year.
For both approaches, the ‘match’ would be the accurate representation of a high school graduate who enrolled in a post-secondary institution.
The Result:
For the first process, the NSC matching generated 15,570 matches, meaning that of the 38,426 students, 15,570 were enrolled in a Connecticut public institution of higher education after high school graduation. The NSC’s highest match rate is not defined, however, experts believe that is very high since the NSC is a trusted organization.
In the second match process with BOR enrollment, Data Ladder provided an additional 1,030 matches to the original 15,570 matches by NSC, resulting in 16, 600 matches, which means, 1,030 additional high school graduates enrolled in a Connecticut public postsecondary institution.
Upon visual inspection, the match was found to produce an estimated 100% match rate.
According to the Department’s report, “the results of this comparison found that using Data Ladder to match SDE with BOR produced 1,030 more matches than the data match with NSC data. The review of Data Ladder matches did not reveal any patter or significant number of invalid links. Without evidence of inaccurate matches, the Data Ladder matching process appears valid.”
Data Ladder’s matching even when scrutinized with a manual review found just 3 records out of the 1,030 records to be ‘unclear’. If there were 5 unclear or invalid questions for every thousand matches, the match rate would be approximately 99.5%.
How Does Data Ladder Help with Record Linkage Challenges?
Data Ladder is a powerful tool that allows data preparation, data cleansing and data matching as core processes of the data quality framework.
With its flexible, multi-dimensional matching functionalities, Data Ladder can help states with:
 Link student information across several databases: Agencies and SLDS stakeholders often cannot conduct effective data matching because of the restrictions on unique identifiers and sensitive individual data. Because this data is also shared across different agencies, the privacy of the individual is paramount, hence, data matching has to rely on other data elements that are subjected to a high level of duplication and human error.
Link student information across several databases: Agencies and SLDS stakeholders often cannot conduct effective data matching because of the restrictions on unique identifiers and sensitive individual data. Because this data is also shared across different agencies, the privacy of the individual is paramount, hence, data matching has to rely on other data elements that are subjected to a high level of duplication and human error.
A student’s contact information may be duplicated, their details may have spelling or typographical errors. Keeping all these limitations in mind, states and agencies have to still link student information without unique identifiers, while also trying to ensure accuracy in linking.
Data Ladder’s data profiling and data cleaning options allow for deduping data and discovering redundancies that other systems miss. When data is deduped, it can be matched to obtain a higher
level of accuracy as is required by the SLDS.
Enhance PSIS in effectively tracking the educational experience of students in the local school districts: Data Ladder can be used by local districts to keep Public School Information System (PSIS) information accurate. This information is used by the state department for public reporting and analysis which means it is necessary for the data to be accurate, complete, verified and validated before it is submitted to the department.
Seemingly minor errors such as typos, incomplete address data, missing phone numbers etc degrade the quality of data, making it fail the accuracy guideline set by the state department. Using Data Ladder’s Data Preparation framework, local districts can ensure they provide clean and accurate information for tracking educational experiences and for accurate reporting.
Evaluate the impact of students’ experiences in both secondary and postsecondary education on their experiences in the workforce: With programs such as P-20WIN in place, the goal is to track a student’s experience across the spectrum of their educational and professional life. For this purpose, the data needs to be an accurate representation of the individual’s experience & transition through school, and college, their grades (and the factors that impact these grades), their attendance, their employability, their wages, and so on. All this data can be inter-linked to give an overview of the student’s experience, however, the requisite for this possibility lies in accurate and non-duplicated data.
Provide more accurate accountability reporting for the Federal Perkins Program: States are required to provide an annual report for the Federal Perkins Program along with disaggregated data on the performance of student by factors such as race, ethnicity, gender and special population categories. To this effect, a data matching system is required to match these indicators against the students’ performance to evaluate their levels of performance. This matching is done within each measure for all academic years.
Data Ladder can be used by schools, governments, employers, third-party resources within the educational ecosystem to help make sense of student data over the course of their educational and professional lives.
Having worked with and having been tested by several states, Data Ladder remains one of the most powerful data preparation and data matching tools that is affordable, user-friendly and allows any stakeholder of the SLDS system or otherwise, to prepare, clean and match data at the highest data match accuracy rate – unrivaled by any other solution in the industry.


