















































DME allows you to prepare your data before deduping it, which involves advanced data profiling , cleansing, and standardization. With DME, you can execute the necessary steps to ensure deduplication accuracy, such as pattern recognition, word replacement, letter case transformation, and address standardization.
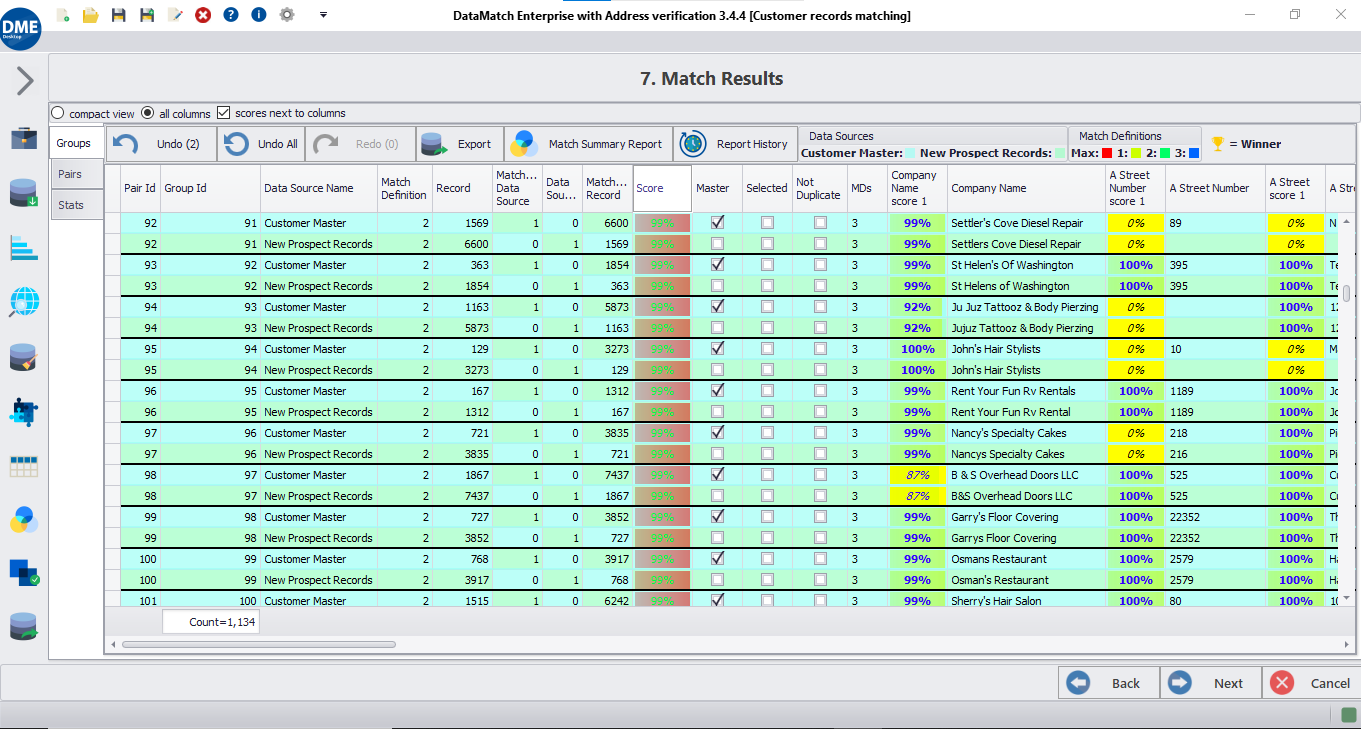
DME leverages advanced field and record matching techniques that consider misspellings, human typographical errors, and conventional variations in data values. DME can assess similarity between records right down to the character level. Moreover, advanced fuzzy matching techniques are also used to compare words and long sentences.

Data analysts

Business users

IT Professionals

Novice users


Merging Data from Multiple Sources – Challenges and Solutions

Big Data Analytics Is Booming – But Is Your Data Ready for It?
Amazon generates 35% of its revenue from data-powered recommendations. Netflix enjoys an 89% retention rate by personalizing every experience using viewer behavior, preferences, and interaction

Data Ethics in the Age of AI: Why Responsible Matching Matters More Than Ever
When AI systems deliver inaccurate or inequitable results, many people immediately assume that something went wrong in the algorithms. Rarely do we look upstream –
Big Data Analytics Is Booming – But Is Your Data Ready for It?
Amazon generates 35% of its revenue from data-powered recommendations. Netflix enjoys an 89% retention rate by personalizing every experience using viewer behavior, preferences, and interaction
Data Ethics in the Age of AI: Why Responsible Matching Matters More Than Ever
When AI systems deliver inaccurate or inequitable results, many people immediately assume that something went wrong in the algorithms. Rarely do we look upstream –

Why Data Interoperability Challenges Are Holding Back Your Insights – And What to Do About It
Every modern organization thinks it’s interoperable—until the data says otherwise. Your systems are technically connected. APIs are firing. Data is flowing. But when you zoom
