





























Last Updated on mars 30, 2022
Alors que les entreprises investissent des milliards de dollars dans le big data dans l’espoir de transformer les données en argent, le besoin de logiciels, de solutions et d’outils de préparation des données efficaces et faciles à utiliser augmente également. Il devient de plus en plus difficile pour les entreprises de préparer les données à l’aide de méthodes traditionnelles, d’autant plus que les big data sont de nature très complexe. Les procédures ETL de base ne font plus l’affaire. D’où la nécessité d’un outil de préparation des données puissant et de premier ordre.
Ce guide rapide sur la préparation des données aidera les débutants en science des données, les experts, les utilisateurs professionnels et les décideurs à mieux comprendre le processus de préparation des données, son importance dans notre environnement professionnel et comment une solution de premier ordre peut vous aider à atteindre vos objectifs de préparation des données. Nous répondrons en profondeur à des questions telles que :
- Qu’est-ce que la préparation des données ?
- Pourquoi la préparation des données est-elle importante ?
- Comment préparer les données ?
- Les défis du processus de préparation des données
- Principaux avantages de la préparation des données
- Meilleures pratiques
Plongeons-y !
Qu’est-ce que la préparation des données ?
La définition standard de la préparation des données est la suivante :
« Le processus de collecte, de combinaison, de structuration et d’organisation des données. »
Mais à l’ère du big data, la préparation des données ne se limite pas à leur organisation.
C’est une nécessité qui alimente la prise de décision.
Il s’agit d’une exigence pour donner un sens aux 65 milliards de dollars d’investissement dans l’analyse des big data.
Il s’agit également d’une nouvelle approche très attendue de la préparation des données en libre-service, qui permet aux utilisateurs professionnels d’optimiser leurs données pour l’usage auquel elles sont destinées.
En pratique, la préparation des données est un flux de travail composé de :
- Profilage des données: Évaluation de vos données afin de déterminer la nature et l’ampleur des problèmes, tels que les champs non structurés, les valeurs manquantes, les noms mal orthographiés, les fautes de frappe excessives, l’utilisation de caractères non imprimables, etc.
- Nettoyage des données: Utilisation de règles commerciales prédéfinies pour nettoyer les données désordonnées.
- Déduplication des données: Les doublons sont un problème grave à résoudre. Si vous pouvez gérer des données désordonnées, ce sont les données en double qui peuvent causer des ravages imprévus.
- Validation des données: Le processus de vérification ou de validation de vos données par rapport aux normes de l’autorité. Par exemple, la validation des données d’adresse avec celles de l’USPS.
- Transformation des données : Transformer des données brutes et désordonnées en données propres et utilisables.
- Fusion des données et survivance: Fusionner plusieurs sources de données pour créer des fiches définitives.
L’image ci-dessous est un exemple du type de mauvaises données pour lesquelles vous aurez besoin d’une solution de préparation des données pour les résoudre.

Chacune de ces sous-activités est un processus complexe qui prend des jours et des mois à accomplir. C’est l’une des raisons pour lesquelles les scientifiques des données finissent par passer 80 % de leur temps à réparer les données. Malgré des investissements massifs dans l’analyse des big data, les entreprises ont encore du mal à préparer leurs données.
Il convient de noter que la préparation des données ne consiste pas simplement à exécuter vos ensembles de données à l’aide d’un outil ou d’un logiciel.
En théorie, la préparation des données implique :
- Identifier un problème
- Reconnaître le problème
- Comprendre l’impact du problème sur l’entreprise
- Évaluation d’une approche organisationnelle de la qualité des données
- Analyse de la stratégie actuelle en matière de données
- Mise en œuvre d’un plan de qualité des données
- Déplacer les dépendances de l’équipe informatique vers les utilisateurs professionnels.
En travaillant avec des entreprises du classement Fortune 500, nous avons constaté que les entreprises qui sont conscientes des problèmes commerciaux sous-jacents aux données ont de bonnes chances de réussir la préparation des données. Ces organisations connaissent le problème et son impact sur l’entreprise. D’autre part, les organisations qui n’ont pas évalué, compris et reconnu les problèmes liés à leurs données ont eu du mal à réussir la préparation des données.
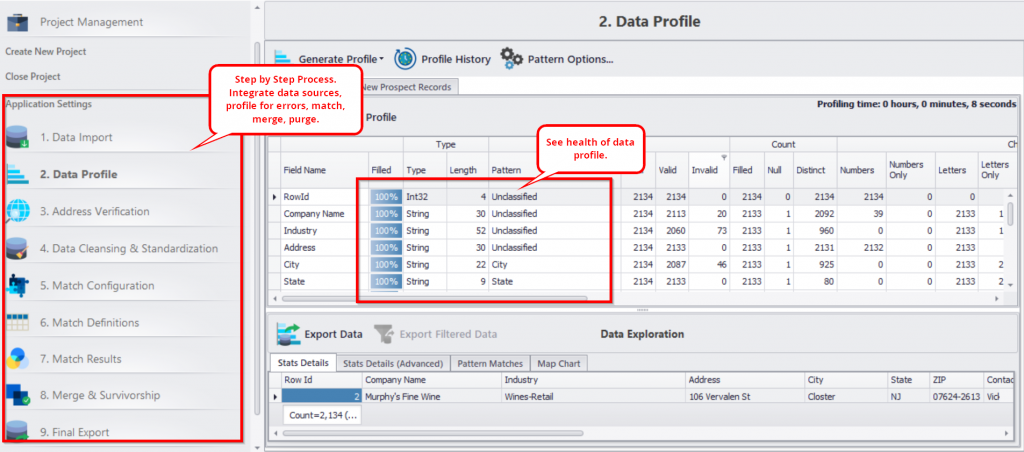
Voici un aperçu du processus de préparation des données utilisé dans DataMatch Enterprise, l’outil phare de préparation des données de Data Ladder.
Identifier le besoin et poser les bonnes questions commerciales
Aussi étrange que cela puisse paraître, la préparation des données ne commence pas exactement par les données – elle commence par l’identification d’un besoin dans le processus décisionnel de l’entreprise. Il s’agit tout d’abord de comprendre l’impact d’un certain ensemble de données sur les stratégies de marketing, le déploiement des ressources, la distribution des produits et tout autre domaine des opérations de l’entreprise. La prise de décisions éclairées et correctes est le besoin primordial des entreprises qui fonctionnent à partir d’informations – si l’entreprise n’a pas accès à ces informations, elle est condamnée.
Mais lorsqu’il s’agit de poser les questions, il est nécessaire d’être précis. Vous ne pouvez pas adopter une approche globale de la préparation ou de la qualité des données.
Vous ne pouvez pas réparer un million d’enregistrements de clients simplement parce que vous voulez des données propres. Le coût de la découverte et de la préparation des données ne doit pas être supérieur à la valeur obtenue, sinon l’effort n’est pas rentable.
Il doit y avoir un objectif.
L’objectif doit être lié à la rentabilité et à l’efficacité.
Il faut évaluer les données et leur capacité à soutenir cet objectif.
L’objectif devrait permettre de répondre à des questions commerciales telles que :
- Est-ce que nous gagnons de l’argent avec cet objectif ? (Un nouveau produit, une nouvelle activité promotionnelle, un nouvel objectif marketing, etc.)
- Cet objectif nous aide-t-il à réussir la satisfaction des clients ou même l’acquisition et la fidélisation ?
- Pourquoi essayons-nous d’atteindre cet objectif ?
- Comment allons-nous mesurer le succès ou l’échec d’un projet ?
- De quels outils ou ressources disposons-nous pour réaliser cet objectif ?
- De quels outils ou ressources supplémentaires aurons-nous besoin et pourquoi ?
- Quel sera le coût de ces outils et quel est le retour sur investissement que nous attendons de ces dépenses ?
En règle générale, commencez par une question commerciale, formulez une hypothèse, effectuez une analyse exhaustive de l’impact de vos décisions et, enfin, tirez les conclusions de votre équation commerciale.
Comprendre vos données
Avant même de pouvoir commencer à exécuter une stratégie commerciale, vous devez comprendre vos données.
- Avez-vous des données brutes, non traitées ?
- Avez-vous des données techniquement correctes mais dupliquées ?
- Avez-vous des données propres et utilisables avec lesquelles travailler ?
- Avez-vous des données cloisonnées provenant de sources disparates ?
- Avez-vous une sélection du type de données dont vous aurez besoin pour cet objectif ?
- Avez-vous besoin d’intégrer de grandes sources de données telles que les médias sociaux, les données transactionnelles ou comportementales pour obtenir une vue unifiée de vos clients ?
- Disposez-vous d’un logiciel de préparation des données robuste, capable de vous permettre de travailler avec vos données sur votre domaine de cloud ou de serveur ?
Il est important de mentionner trois défis courants auxquels les entreprises sont généralement confrontées lorsqu’il s’agit de préparer leurs données pour l’usage auquel elles sont destinées. Ces problèmes peuvent être résolus par une solution de préparation des données, mais vous devrez mesurer l’ampleur de l’activité et le type de formation ou de courbe d’apprentissage dont vous aurez besoin pour utiliser le logiciel. De nombreuses entreprises dépensent des millions de dollars uniquement pour faire travailler des spécialistes formés sur un logiciel de préparation des données. Par conséquent, soyez sûr de ce que vous devez faire avant d’investir une somme importante dans une solution populaire de qualité des données.
Pourquoi la préparation des données est-elle importante ?
Bien que tout le monde parle de la préparation des données, personne ne fait rien à ce sujet. Après avoir identifié vos objectifs ou les problèmes à résoudre, la préparation des données est la clé de la résolution du problème. C’est facilement la différence entre le succès et l’échec, entre des idées utilisables et un texte inintelligible, entre une décision éclairée et des hypothèses ou théories inutiles.
Par exemple, un client a dû utiliser ses données pour lancer une stratégie de personnalisation de la clientèle. L’organisation se considérait comme axée sur les données parce qu’elle avait créé des lacs de données pour stocker les données sur les ménages de ses clients et voulait maintenant utiliser ces données pour offrir des services de personnalisation. S’ils étaient conscients des problèmes liés aux données brutes, ils n’étaient pas préparés à faire face au nombre excessif de doublons et de déchets qui rendaient près de 40 % de leurs données inutiles. Avant de lancer leurs objectifs de personnalisation, ils devaient d’abord préparer et nettoyer leurs données.
Ainsi, alors que les entreprises disposent d’énormes lacs de données, ils finissent par devenir des décharges de données parce que l’idée initiale était que « plus de données, c’est mieux ». Cette approche ne fonctionne plus. Vous avez besoin de la préparation des données et de ses sous-activités pour vous assurer que vous disposez de données utilisables pour travailler.
Dans le cas contraire, l’absence de données propres pourrait entraîner :
- Inefficacité opérationnelle : Les équipes et les processus seront affectés car ils ne disposeront pas du bon ensemble de données pour travailler et contribuer à l’objectif.
- Mauvaise satisfaction du client : Une entreprise qui gère mal ses données peut commettre des erreurs embarrassantes et manquer des occasions, ce qui se traduira par une faible satisfaction de la clientèle.
- Coûts inutiles : Les conséquences d’une mauvaise gestion des données se traduiront par toutes sortes de coûts qui pourraient être préjudiciables à votre entreprise – amendes légales, problèmes de sécurité des données, pénalités de conformité des données, retours de courrier, perte de clients, etc.
- Croissance ralentie : C’est un marché dynamique. Si vous ne misez pas sur les données, vous ne pourrez pas vous développer. Les entreprises futuristes se concentrent sur l’optimisation de leurs données.
- Des informations erronées : Presque toutes les entreprises sont engagées dans une forme ou une autre de modélisation des données à des fins d’analyse et de compréhension. Des données inexactes qui n’ont pas été soumises à un processus de préparation des données seront à l’origine d’informations erronées – dont nous ne connaissons que trop bien les conséquences.
Dans sa forme la plus simple, la préparation des données nous aide à comprendre les informations contenues dans les données que nous ne pouvons pas comprendre en les regardant simplement. C’est tout. Et c’est le but le plus important de cette activité.
Comment préparer les données ?
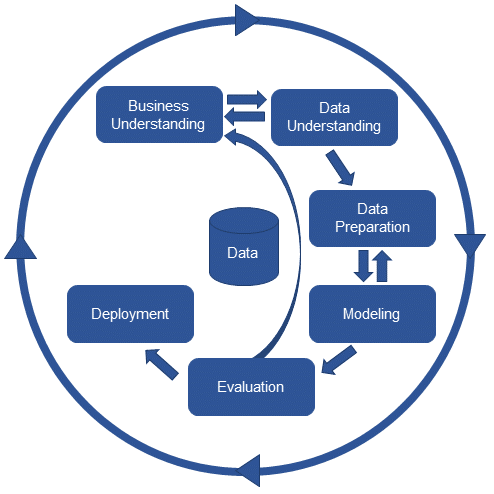
La préparation des données a été en grande partie un effort manuel. Après qu’un ensemble de données a été sélectionné pour être utilisé, il est passé par un logiciel de préparation des données où des opérations spécifiques sont appliquées aux fichiers. Par exemple, l’une de ces opérations peut consister à supprimer manuellement des données textuelles dans un champ numérique pour lequel des formules ou une combinaison de fonctions seront utilisées. Si cela fonctionnait pour des ensembles de données de petite taille et peu complexes, aujourd’hui, avec l’augmentation du volume et de la complexité des données, les spécialistes des données trouvent extrêmement frustrant de passer la majeure partie de leur temps à préparer ces données.
Il y a de fortes chances que votre entreprise utilise déjà un processus ETL pour donner un sens aux données. Cependant, l’ETL est très limité et ne permet pas aux utilisateurs professionnels d’exploiter efficacement leurs données. Lisez le post suivant pour connaître la différence entre l’ETL et la préparation des données.
C’est pourquoi le nombre de fournisseurs de logiciels a augmenté au fil des ans. La plupart de ces outils offrent désormais une fonction de libre-service qui permet aux utilisateurs professionnels de participer au processus de préparation des données.
Un outil comme DataMatch Enterprise, par exemple, simplifie le processus de préparation des données en guidant l’utilisateur à travers un flux de travail qui lui permet de nettoyer, déduire et fusionner facilement les données – un processus qui prend habituellement des jours et des mois ne prendrait que quelques minutes.
Les outils de préparation des données facilitent également le traitement des données incohérentes stockées en silos. Il y a quelques décennies, vous deviez fixer les données dans leur système individuel et essayer de fusionner certaines parties de ces données manuellement, sans pour autant obtenir l’analyse dont vous aviez besoin.
Désormais, vous pouvez facilement intégrer des ensembles de données illimités, les fusionner, les purger, les préparer comme bon vous semble. Il s’agit d’une activité de type « glisser-déposer », qui ne nécessite qu’une expertise technique très limitée.
Les défis du processus de préparation des données :
Si la préparation des données a été facilitée, les défis qu’elle pose restent les mêmes, voire plus complexes et gênants. Certains des principaux défis que les entreprises doivent relever sont les suivants :
Données en silos et sources disparates : Les entreprises souhaitent désormais créer des vues unifiées du client afin de créer des expériences de personnalisation ou d’obtenir une vue d’ensemble des opportunités cachées. Par exemple, un détaillant souhaitait consolider les données provenant de plusieurs sources de données afin d’offrir une expérience numérique fluide à ses clients provenant de différentes régions européennes.
Mais la consolidation des données provenant de sources multiples n’est pas chose aisée. Les données stockées dans des sources disparates varient en termes de structure, de forme et de finalité. Plus important encore, les erreurs de données variaient selon les cultures. Les noms italiens, par exemple, étaient plus souvent mal orthographiés que les noms américains. Il faut beaucoup de temps pour préparer ces données et les rendre utiles au détaillant. Même si un outil de préparation des données est utilisé, un certain travail manuel sera nécessaire pour examiner les noms provenant de différentes cultures et s’assurer qu’aucune erreur n’est commise.
Données dupliquées : Presque toutes les entreprises avec lesquelles nous avons travaillé ont signalé que la duplication des données était un obstacle majeur à la réussite de leur préparation des données. Bien qu’il existe des dizaines d’outils de préparation des données qui vous permettent de corriger les anomalies de données, très peu d’entre eux ont la capacité de corriger les données dupliquées avec un taux de correspondance de 100 %. En fait, le rapprochement des données est une solution très demandée, car très peu de fournisseurs parviennent à atteindre une précision de 95 %.
Un institut gouvernemental avec lequel nous avons travaillé a découvert que sa solution interne de déduplication des données ne pouvait faire que la moitié du travail de suppression des doublons. Lorsqu’ils ont utilisé DataMatch, ils ont pu supprimer 40 % supplémentaires de données en double.
Données incohérentes : Aka données sales. La qualité des données est toujours douteuse tant que ce sont des humains qui saisissent les noms et adresses des clients, les codes des produits et les prix. Inévitablement, les méthodes manuelles entraînent des erreurs dont la résolution demande un effort manuel considérable. La situation est encore plus compliquée et désordonnée lorsque vous devez combiner des données d’entreprise avec des données externes provenant de sources tierces. Par exemple, les données relatives aux médias sociaux d’un client sont tout sauf cohérentes. Certains peuvent utiliser des abréviations dans leur nom, d’autres un autre nom… et la liste est longue.
Ces problèmes ont poussé à l’essor des logiciels de préparation des données en libre-service et dans le nuage, qui permettent aux utilisateurs d’intégrer des données provenant de sources multiples, de créer des règles commerciales en fonction de leurs besoins en matière de données et de réunir les utilisateurs informatiques et commerciaux pour résoudre les problèmes de qualité des données.
Meilleures pratiques pour la préparation des données
Maintenant que le monde se dirige vers des objectifs d’IA, d’apprentissage automatique et de business intelligence, il doit se concentrer sur la préparation des données pour atteindre ces objectifs. L’utilisation d’un logiciel ou d’un outil de préparation des données ne constitue toutefois qu’une partie de la solution. Vous devrez intégrer des pratiques supplémentaires pour la préparation des données qui doivent inclure :
- Faire de la qualité des données une priorité : Les problèmes et les défis liés à la préparation des données sont causés par le manque d’attention portée à la qualité des données. Les entreprises peuvent parler de la qualité des données, mais elles n’en font pas une priorité organisationnelle. Vous continuerez à réparer les mêmes erreurs à plusieurs reprises si vous ne rectifiez pas la source du problème. Par exemple, votre équipe de vente compromet la qualité des données en saisissant des informations inexactes, en omettant des informations importantes ou en commettant des erreurs humaines lors de la saisie des données. Pour y remédier, votre équipe devra être formée à la qualité des données, ce qui l’aidera à comprendre l’impact d’une coquille ou d’une information manquante sur les processus en aval.
- L’informatique peut aider les utilisateurs professionnels en organisant des séances de formation et d’apprentissage : Il s’agit d’un bon moyen de combler le fossé entre l’informatique et les utilisateurs professionnels. Le service informatique peut planifier des formations sur la qualité des données et des sessions d’apprentissage pour aider les utilisateurs professionnels à comprendre l’importance de la qualité et de la préparation des données. Au fur et à mesure que les utilisateurs professionnels se familiarisent avec le problème, les utilisateurs autorisés peuvent être équipés des bons outils de préparation des données pour commencer à préparer leurs données pour une utilisation professionnelle sans dépendre de l’informatique.
- Suivez le processus de préparation des données : Si vous utilisez un logiciel de préparation des données comme DataMatch Enterprise, vous suivez un processus étape par étape qui fait passer vos données du stade brut au stade final en 8 modules. Si vous n’utilisez pas d’outil et que vous le mettez en œuvre vous-même, veillez à suivre le flux de travail indiqué ci-dessous.
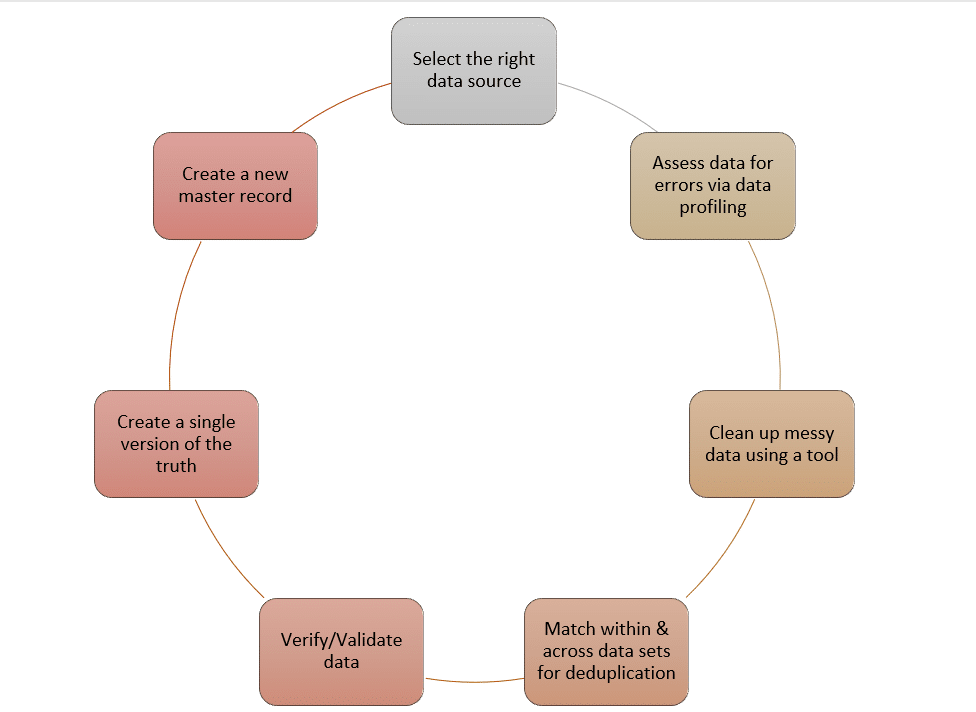
La tâche est énorme. Mais toute organisation intelligente sait que l’objectif n’est pas une perfection à 100 % ou une approche globale. L’objectif est de garantir une culture et une approche de la qualité des données où les problèmes sont prévenus avant de devenir des nuisances difficiles.
Conclusion
La préparation des données n’est qu’une partie de la première étape de la gestion des données et, bien qu’il existe de puissants outils de préparation des données qui font le gros du travail, les entreprises auront toujours besoin d’êtres humains pour vérifier, valider et s’assurer que le résultat est celui souhaité. Il est important de reconnaître que les outils ne sont aussi intelligents que les humains qui les utilisent. Puisque l’avenir est à l’IA et au ML, il est impératif que les entreprises entament une approche ciblée dans la préparation des données, en transformant leurs données en un carburant qui fait avancer l’organisation.

Comment fonctionnent les meilleures solutions de correspondance floue de leur catégorie : Combinaison d’algorithmes établis et exclusifs
Commencez votre essai gratuit aujourd’hui
Aïe ! Nous n’avons pas retrouvé votre formulaire.



