





























Last Updated on avril 8, 2022
Confusion entre ETL et préparation des données ? Vous n’êtes pas sûr de la méthode à suivre ? Voici tout ce que vous devez savoir sur l’ETL et la préparation des données.
Cet article couvre :
- Un bref aperçu de l’ETL
- Pourquoi l’ETL n’est plus efficace
- Un aperçu de la préparation des données
- Principales différences entre l’ETL et la préparation des données
- Quelle méthode convient le mieux à votre entreprise
- Préparation des données avec Data Ladder
Un bref aperçu de l’ETL
L’extraction, le chargement et la transformation (ETL) n’ont guère besoin d’être présentés. Développée dans les années 1970, cette technologie de pointe était utilisée pour mélanger des données provenant de sources multiples. Les actions primaires étant :
Extraction : Dériver, copier ou extraire des données d’une source du système.
Transformer : Reformater les données pour les utiliser dans un nouveau système.
Chargement : Introduire les données dans le nouveau système
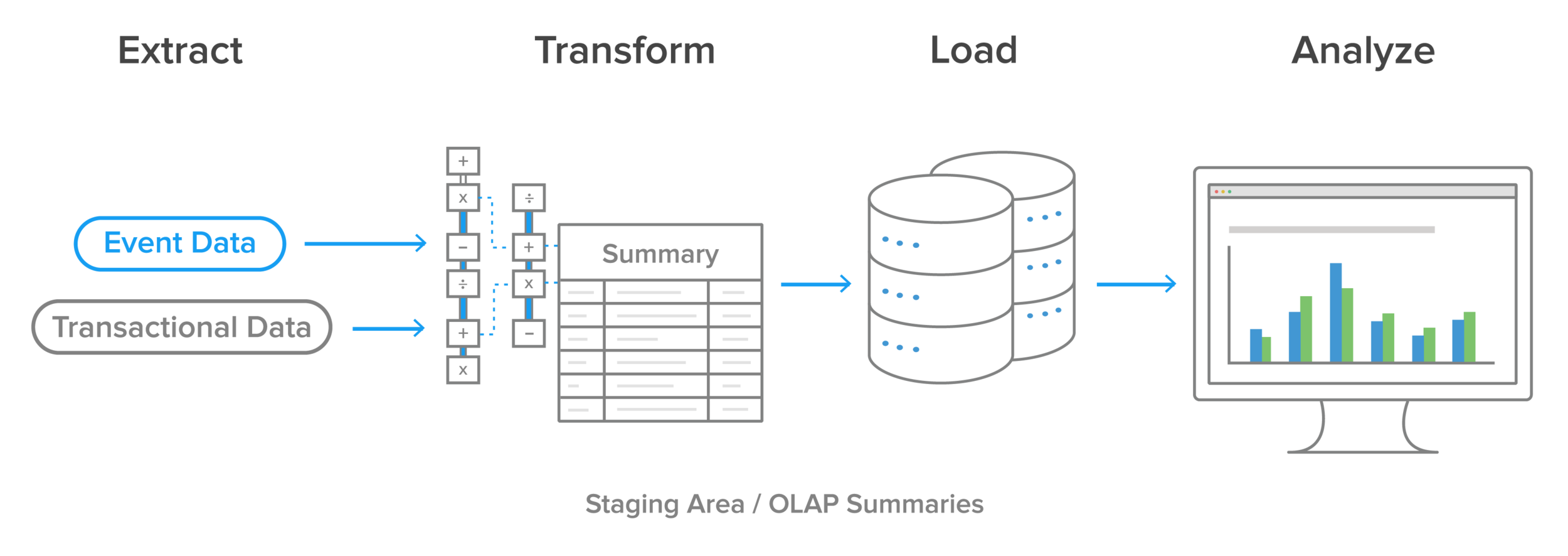
Les solutions ETL ont aidé les entreprises à consolider les données provenant de sources multiples, en particulier dans les années 1980 et 1990, lorsque l’entreposage de données est devenu populaire. L’ETL était utilisé pour intégrer les données de plusieurs systèmes – ordinateurs centraux, PC, tableurs, etc. dans une seule base de données. Le problème ? À mesure que la complexité des données augmentait, les entreprises ont commencé à utiliser différents outils ETL pour gérer différents types d’entrepôts de données.
Au fil du temps, les formats de données, les systèmes et les sources se sont développés – en complexité et en volume – et les méthodes ETL traditionnelles n’ont plus tenu le coup. Bien que le processus ETL de base reste un élément essentiel de l’écosystème des données, ses défis ont donné lieu à des approches et des processus plus récents.
Les défis de l’ETL :
Un système ETL typique est efficace lorsque les données sont structurées, orientées vers le traitement par lots et ont été régulièrement mises à jour. Cependant, avec des données en continu sensibles au temps, les systèmes ETL ont tendance à échouer, à moins que le système ne soit modifié par une programmation personnalisée. Même dans ce cas, un système ETL dans un environnement en temps réel sera confronté aux exigences de faible latence et de haute disponibilité.
Le processus ETL lui-même est devenu de plus en plus complexe, notamment en raison de l’expansion des formats de données et de la nécessité d’utiliser plusieurs scripts et API pour chaque format afin d’analyser les données. Cela impliquait que si des API ou des pilotes compatibles n’étaient pas disponibles, les spécialistes ETL devaient coder spécifiquement un processus ETL – une tâche fastidieuse si l’on considère qu’une source de données d’une entreprise moyenne comporte des millions de lignes de données.
Bien qu’il existe de nombreux outils ETL disponibles sur le marché, capables de traiter des données complexes et de surmonter les défis de l’ETL, ils nécessitent toujours une courbe d’apprentissage importante et la mise en œuvre de processus supplémentaires pour rendre les données exploitables.
Saisir les solutions de préparation des données.
Qu’est-ce que la préparation des données et en quoi est-elle différente de l’ETL ?
L’ETL et la préparation des données sont souvent confondus comme un seul processus. Bien qu’il y ait une part de vérité à cela, puisque la préparation des données implique le processus d’extraction et de transformation des données et la résolution des mêmes problèmes, il existe des caractéristiques distinctes qui font de la préparation des données une méthode plus flexible que l’ETL.
Lapréparation des données peut être décrite comme le processus consistant à « préparer » ou à rendre les données prêtes pour l’analyse et le rapport. Bien qu’elle soit similaire à l’ETL, il s’agit d’une solution visuelle, en libre-service et facile à utiliser qui donne à un utilisateur professionnel la possibilité de préparer des données, contrairement à l’ETL qui était avant tout un processus informatique géré exclusivement par l’équipe informatique.
Selon Jon Pikington de Dataversity, la préparation des données est ,
« la technologie qui permet aux administrateurs de prendre plus rapidement de meilleures décisions grâce à la qualité des données et à leur accès. »
Les entreprises utilisent la préparation des données pour :
- Permettre aux utilisateurs de préparer facilement leurs données en fonction des exigences de l’analyse.
- Réduire la charge de l’informatique et faire de la préparation des données un processus automatisé.
- Donner du sens à des données complexes
- Faites correspondre, consolidez, nettoyez et résolvez les problèmes liés aux données sans exiger d’expertise technique ou de programmation.
Ainsi, si l’ETL est un processus technique mis en œuvre pour déplacer les données, il ne dispose pas des fonctionnalités supplémentaires que les solutions de préparation des données tendent à offrir. Voici quelques-uns des principaux avantages de la préparation des données :
- Les données sont préparées par ceux qui les connaissent le mieux
Le principal avantage de la préparation des données est le fait que les données peuvent être préparées par les utilisateurs professionnels qui les connaissent le mieux. Par exemple, les utilisateurs professionnels du département marketing peuvent utiliser un outil de préparation des données pour identifier les utilisateurs de médias sociaux les plus actifs qui, s’ils étaient confiés à l’informatique, ne donneraient pas un résultat précis. Les données ne sont pas que des chiffres et du texte. Chaque ensemble de données comporte un contexte inhérent qui ne peut être compris et identifié que par les personnes qui utiliseront ces données.
- Faciliter l’analyse prédictive
L’analyse prédictive fait référence au processus de prévision du comportement et des attentes des entités (clients) par l’étude ou l’analyse d’ensembles de données actuelles. Les entreprises doivent faire correspondre plusieurs sources de données telles que les médias sociaux, les enquêtes en ligne, les comportements d’achat, l’historique des achats, l’historique des billets, etc. pour obtenir une image de leur public, ce qui leur permet de faire des prédictions.
L’ETL ne permet pas ce niveau de rapprochement et de consolidation intelligents des données, ce qui le rend inutile pour toute entreprise qui souhaite obtenir des informations stratégiques. Les outils de préparation des données, quant à eux, permettent aux entreprises de faire correspondre des champs de données complexes dans ou entre plusieurs ensembles de données et de créer une source de vérité unique et consolidée sans avoir besoin de compétences ou de connaissances techniques.
- Flexibilité dans le nettoyage des données
Les outils ETL reposent sur des règles et des flux de travail structurés. Les problèmes tels que les noms abrégés, les caractères supplémentaires, les fautes d’orthographe ou même les ponctuations dans les numéros de téléphone doivent être prédéfinis pour que l’ETL les détecte. La plupart du temps, cependant, certaines erreurs sont si trompeuses par nature (par exemple l’utilisation de surnoms par rapport aux vrais noms) qu’il est difficile de les prédéfinir et de créer des règles pour elles. Deuxièmement, l’ETL implique qu’un utilisateur doit connaître les failles de ses données avant de pouvoir les corriger – mais il existe de nombreux cas où un utilisateur ne connaît tout simplement pas les problèmes qui affectent ses données.
Les outils de préparation des données n’imposent pas de telles règles aux utilisateurs. En fait, les meilleurs outils de préparation des données du marché ont des algorithmes prédéfinis qui capturent tous les problèmes possibles d’un champ de données et permettent à l’utilisateur de voir les problèmes de ses données. L’outil donne à l’utilisateur une représentation visuelle de la santé de ses données – les colonnes contenant des données manquantes ou invalides, les champs comportant des fautes d’orthographe ou de caractères, les espaces supplémentaires entre les caractères, etc. peuvent tous être vus et corrigés par l’utilisateur avant d’utiliser les données.
Comme vous pouvez maintenant le constater, l’ETL et la préparation des données, bien qu’ils remplissent essentiellement les mêmes fonctions, ont des utilisations distinctes. Alors que l’ETL est un processus d’extraction de données en arrière-plan, un outil de préparation des données est un outil commercial qui permet aux utilisateurs d’affiner et de préparer leurs données pour une utilisation commerciale.
Utilisation de l’API d’un outil de préparation de données avec un tube ETL – Un exemple
De nombreuses entreprises utilisent à la fois l’ETL et la préparation des données pour gérer efficacement leurs données. Cela est possible en intégrant l’API de l’outil de préparation des données au tuyau ETL de l’écosystème de données de l’organisation. De cette façon, les données en temps réel sont nettoyées et appariées avant que l’outil ETL ne charge ces données dans une nouvelle source de données.
Voici un petit exemple d’un des clients de Data Ladder qui utilise à la fois l’ETL et notre logiciel de préparation de données pour atteindre ses objectifs.
Pensez à un scénario ETL dans lequel l’organisation dispose d’une tonne de données de base/maîtresses, et traite des milliers, des dizaines de milliers, des centaines de milliers ou des millions de transactions par jour/semaine, etc. et souhaite diffuser ces données en continu par rapport à ses données de base, en enrichissant ces dernières avec les détails des transactions.
Le cas d’utilisation du streaming est l’analyse prédictive. L’organisation dispose de données de base, mais elle recueille également de grandes quantités de données supplémentaires, afin d’enrichir ses données de base, telles que les intérêts des consommateurs, le score de crédit, les informations de géolocalisation. etc., les solutions ETL ne font pas très bien le rapprochement. Ils veulent donc enrichir ces données de base avec des tonnes de nouvelles données, en temps réel, à la volée, et cela ne fonctionnera pas si le nom de leur base de données de base est Peggy Sheridan et le nom de ces nouvelles données est Margaret Sheridan.
Le tube ETL de l’organisation peut utiliser l’API de Data Ladder pour invoquer le nettoyage et la correspondance afin d’extraire l’identifiant unique de leurs données de base, d’ajouter cet identifiant unique aux nouvelles données correspondantes et de mettre à jour leurs données de base avec ces nouveaux attributs.
Comment Data Ladder aide-t-il à la préparation des données ?
Le logiciel phare deData Ladder, DataMatch Enterprise, permet de préparer facilement les données en permettant aux utilisateurs de :
Intégrer des données : Intégrez les données de plus de 150 applications et obtenez les ensembles de données dont vous avez besoin pour vos analyses et rapports.
Profil des données : Identifiez visuellement les failles de vos données. Vous pouvez voir les problèmes qui affectent vos données, notamment les fautes d’orthographe, les erreurs de chiffres, les problèmes de ponctuation et bien plus encore.
Nettoyer les données : Lenettoyage des données est réalisé en appliquant simplement des règles prédéfinies sur vos données. Les doublons sont supprimés, les adresses électroniques invalides sont mises en évidence et corrigées, les adresses physiques sont vérifiées et validées, ainsi que de nombreuses autres fonctions. L’objectif est de vous aider à obtenir des données auxquelles vous pouvez faire confiance.
Appariement des données : Faites correspondre les données à l’intérieur, entre ou à travers plusieurs sources de données en utilisant une combinaison d’algorithmes de correspondance flous et l’algorithme propriétaire du logiciel.
Fusionner : Fusionnez les données corrigées et appariées dans un seul fichier maître et faites-en votre seule source de vérité avant de charger ces nouvelles informations dans un nouveau système ou une nouvelle source.
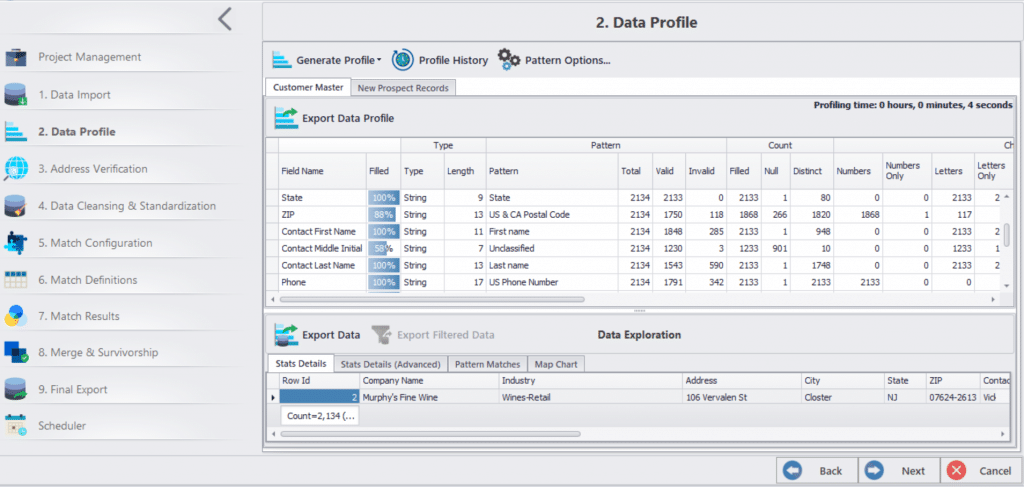 En outre, vous pouvez utiliser DataMatch Enterprise pour profiler et corriger vos données en fonction de règles prédéfinies ou de règles commerciales supplémentaires que vous souhaitez créer. Le meilleur ? Il n’est pas nécessaire de connaître un quelconque langage de programmation pour préparer vos données à l’aide de DataMatch Enterprise.
En outre, vous pouvez utiliser DataMatch Enterprise pour profiler et corriger vos données en fonction de règles prédéfinies ou de règles commerciales supplémentaires que vous souhaitez créer. Le meilleur ? Il n’est pas nécessaire de connaître un quelconque langage de programmation pour préparer vos données à l’aide de DataMatch Enterprise.
Quelle est la meilleure solution pour votre entreprise ?
Le choix est assez simple. Si vous disposez d’une équipe informatique avant-gardiste capable de surmonter les complexités des données modernes et d’actualiser constamment les données grâce à des ajustements et à un suivi réguliers du processus ETL, alors vous pouvez compter sur l’ETL pour trier vos données. Dans de nombreuses situations, une solution ETL reste préférable, notamment lorsque des milliards de lignes de données sont transformées et chargées en vrac dans des entrepôts de données et que la nature des données ne change pas de manière significative au fil du temps. Notez cependant que l’ETL est un processus qui prend du temps. Même si vous utilisez un logiciel commercial, vous devrez le programmer de manière significative pour répondre à vos besoins.
Les outils de préparation des données tels que celui de DataMatch Enterprise offrent beaucoup plus de souplesse, ce qui permet aux entreprises d’obtenir des résultats opportuns et d’utiliser les données pour des analyses et des rapports approfondis de la part des chefs d’entreprise eux-mêmes. Aucun réglage supplémentaire, aucune connaissance en programmation ou aucune compétence supplémentaire n’est nécessaire pour donner du sens aux données.
Conclusion
L’écosystème des données est complexe et nécessite une combinaison de plusieurs outils et processus pour obtenir des résultats. Il est prudent de comprendre quel logiciel ou outil est le mieux adapté aux besoins de votre entreprise. Vous pensez qu’un outil ETL est ce dont vous avez besoin, mais il ne s’agit peut-être que de la préparation des données. Le choix dépend de vos objectifs commerciaux, de vos ressources et du type d’informations que vous souhaitez obtenir de vos données.
Pour savoir comment notre outil de préparation des données peut vous aider à générer des analyses et des rapports précis, contactez dès aujourd’hui notre architecte de solutions.



