





























Last Updated on septembre 13, 2022
Lorsque vous extrayez des données de diverses applications installées dans toute l’entreprise, vous vous attendez à recevoir une définition et un format cohérents de ces mêmes informations. Mais en réalité, c’est rarement le cas. Les variations présentes dans les ensembles de données – entre les applications et même au sein d’une même application – rendent presque impossible l’utilisation des données à toutes fins – des opérations de routine à la veille économique.
Aujourd’hui, une entreprise moyenne utilise plusieurs applications SaaS et internes. Chaque système est assorti de son propre ensemble d’exigences, de restrictions et de limitations. C’est la raison pour laquelle les données hébergées dans différentes applications contiennent forcément des divergences. Et si l’on tient compte des fautes d’orthographe, des abréviations, des surnoms et des erreurs de frappe, on se rend compte que les mêmes valeurs peuvent avoir des centaines de représentations différentes. C’est là qu’il devient impératif de normaliser les données afin de les rendre utilisables à toutes fins utiles.
Dans ce blog, nous allons tout apprendre sur la normalisation des données : ce qu’elle est, pourquoi et quand vous en avez besoin, et comment vous pouvez la faire. Commençons.
Qu’est-ce que la normalisation des données ?
Dans le monde des données, une norme désigne un format ou une représentation auquel chaque valeur d’un certain domaine doit se conformer. Par conséquent, normaliser les données signifie :
Le processus de transformation d’une représentation incorrecte ou inacceptable de données en une forme acceptable.
Le moyen le plus simple de savoir ce qui est « acceptable » est de comprendre les exigences de votre entreprise. Idéalement, les organisations doivent veiller à ce que le modèle de données utilisé par la plupart – sinon toutes – les applications soit conforme à leurs besoins commerciaux. La meilleure façon de parvenir à la normalisation des données est d’aligner la représentation, la structure et la définition de vos données sur les exigences de l’organisation.
Types et exemples d’erreurs de normalisation des données
Voici quelques exemples de la façon dont des données non normalisées peuvent se retrouver dans le système :
- Le numéro de téléphone du client est enregistré sous forme de chaîne de caractères dans un système alors qu’il ne peut être qu’un numéro à 8 chiffres dans un autre système – ce qui entraîne une incohérence dans le type de données.
- Le nom du client est enregistré dans un seul champ dans un système alors qu’il est couvert par trois champs distincts dans un autre système pour le prénom, le second prénom et le nom de famille, ce qui entraîne une incohérence structurelle.
- La date de naissance du client a le format MM/JJ/AAAA dans un système, alors qu’elle a le format Mois Jour, Année dans un autre système – ce qui entraîne une incohérence de format.
- Le sexe du client est enregistré en tant que Female ou Male dans un système, alors qu’il est enregistré en tant que F ou M dans un autre système – ce qui entraîne une incohérence des valeurs du domaine.
Outre ces scénarios courants, les fautes d’orthographe, les erreurs de transcription et l’absence de contraintes de validation peuvent accroître les erreurs de normalisation des données dans vos ensembles de données.
Pourquoi devez-vous normaliser les données ?
Chaque système a son propre ensemble de limitations et de restrictions, ce qui conduit à des modèles de données uniques et à leurs définitions. C’est pourquoi il peut être nécessaire de transformer les données avant qu’elles ne puissent être consommées correctement par un processus métier.
En général, on sait qu’il est temps de normaliser les données quand on le souhaite :
1. Conformer les données entrantes ou sortantes
Une organisation possède de nombreuses interfaces qui permettent d’échanger des points de données provenant de parties prenantes externes, telles que des fournisseurs ou des partenaires. Chaque fois que des données entrent dans une entreprise ou sont exportées, il devient nécessaire de les conformer à la norme requise, sinon le fouillis de données non normalisées ne fait que s’amplifier.
2. Préparer les données pour la BI ou l’analytique
Les mêmes données peuvent être représentées de plusieurs façons, mais la plupart des outils de BI ne sont pas spécialisés pour traiter toutes les représentations possibles des valeurs de données et peuvent finir par traiter différemment des données de même signification. Cela peut conduire à des résultats BI biaisés ou inexacts. Par conséquent, avant de pouvoir alimenter vos systèmes de BI en données, celles-ci doivent être nettoyées, normalisées et dédupliquées, afin que vous puissiez obtenir des informations correctes et utiles.
3. Consolider les entités pour éliminer les doublons
La duplication des données est l’un des plus grands risques pour la qualité des données auxquels les entreprises sont confrontées. Pour des opérations commerciales efficaces et sans erreur, vous devez éliminer les enregistrements en double qui appartiennent à la même entité (qu’il s’agisse d’un client, d’un produit, d’un emplacement ou d’un employé). Un processus efficace de déduplication des données exige que vous vous conformiez aux normes de qualité des données.
4. Partager les données entre les départements
Pour que les données soient interopérables entre les départements, elles doivent être dans un format compréhensible par tous. Dans la plupart des cas, les organisations disposent d’informations sur les clients dans les systèmes de gestion de la relation client, qui sont comprises par les responsables des ventes et du marketing. Cela peut entraîner des retards dans l’accomplissement des tâches et bloquer la productivité de l’équipe.
Nettoyage des données ou normalisation des données
Les terminologies de nettoyage des données et de normalisation des données sont généralement utilisées de manière interchangeable. Mais il y a une légère différence entre les deux.
Le nettoyage des données est le processus qui consiste à identifier les données incorrectes ou sales et à les remplacer par des valeurs correctes, tandis que la normalisation des données est le processus qui consiste à transformer les valeurs des données d’un format inacceptable en un format acceptable.
L’objectif et le résultat de ces deux processus sont similaires : vous voulez éliminer les inexactitudes et les incohérences de vos ensembles de données. Ces deux processus sont essentiels à votre initiative de gestion de la qualité des données et doivent aller de pair.
Comment normaliser les données ?
Un processus de normalisation des données comporte quatre étapes simples : définir, tester, transformer et retester. Examinons chaque étape un peu plus en détail.
1. Définir une norme
Dans un premier temps, vous devez identifier la norme qui répond aux besoins de votre organisation. La meilleure façon de définir une norme est de concevoir un modèle de données pour votre entreprise. Ce modèle de données représente l’état le plus idéal auquel les valeurs des données d’une certaine entité doivent se conformer. Un modèle de données peut être conçu comme :
- Identifiez les données essentielles au fonctionnement de votre entreprise. Par exemple, la plupart des entreprises saisissent et gèrent des données relatives aux clients, aux produits, aux employés, aux sites, etc.
- Définissez les champs de données de chaque actif identifié et décidez également des détails structurels. Par exemple, vous pouvez souhaiter stocker le nom, l’adresse, l’adresse électronique et le numéro de téléphone d’un client, le champ Nom couvrant trois champs et le champ Adresse deux champs.
- Attribuez un type de données à chaque champ identifié dans le poste. Par exemple, le champ Nom est une valeur de type chaîne de caractères, le champ Numéro de téléphone est une valeur entière, et ainsi de suite.
- Définissez des limites de caractères (minimum et maximum) pour chaque champ. Par exemple, un nom ne peut pas comporter plus de 15 caractères et un numéro de téléphone ne peut pas comporter plus de 8 chiffres, etc.
- Définissez le modèle auquel les champs doivent se conformer – ce modèle peut ne pas être applicable à tous les champs. Par exemple, l’adresse électronique de chaque client doit respecter le regex : [chars]@[chars].[chars].
- Définir le format dans lequel certains éléments de données doivent être placés dans un champ. Par exemple, la date de naissance d’un client doit être spécifiée sous la forme MM/JJ/AAAA.
- Définissez l’unité de mesure des valeurs numériques (le cas échéant). Par exemple, l’âge du client est mesuré en années.
- Définissez le domaine de valeurs pour les champs qui doivent être dérivés d’un certain ensemble de valeurs. Par exemple, l’âge du client doit être un chiffre compris entre 18 et 50, le sexe doit être Masculin ou Féminin, et ainsi de suite.
Un modèle de données conçu peut ensuite être placé dans un diagramme de classe ERD pour aider à visualiser la norme définie pour chaque actif de données et comment ils sont liés les uns aux autres. Un exemple de modèle de données pour une entreprise de vente au détail est présenté ci-dessous :
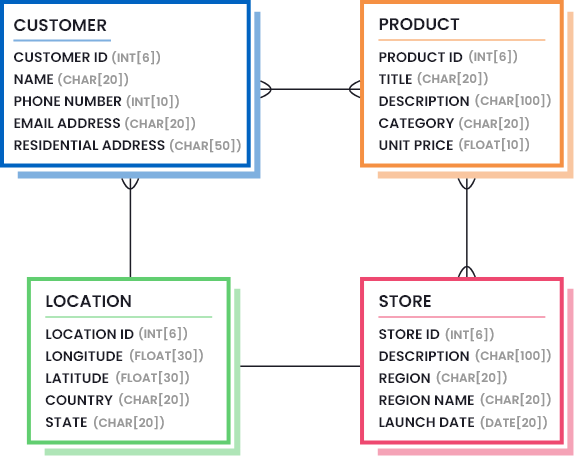
2. Test de la norme
Les techniques de normalisation des données commencent à la deuxième étape, puisque la première étape se concentre sur la définition de ce qui devrait être – quelque chose qui est fait une fois ou revu et mis à jour de façon incrémentielle de temps en temps.
Vous avez défini la norme et il est maintenant temps de voir dans quelle mesure les données actuelles s’y conforment. Nous examinons ci-dessous un certain nombre de techniques qui permettent de tester les valeurs de données pour détecter les erreurs de normalisation et de créer un rapport de normalisation qui peut être utilisé pour résoudre les problèmes.
a. Analyse syntaxique des enregistrements et des attributs
La conception d’un modèle de données est la partie la plus cruciale de la gestion des données. Mais malheureusement, de nombreuses organisations ne conçoivent pas de modèles de données et ne définissent pas de normes de données communes à temps, ou encore les applications qu’elles utilisent ne disposent pas de modèles de données personnalisables – ce qui les conduit à capturer des données sous des noms de champs et des structures variables.
Lorsque vous interrogez des informations provenant de différents systèmes, vous pouvez remarquer que certains enregistrements renvoient le nom d’un client sous la forme d’un champ unique, tandis que d’autres renvoient trois, voire quatre champs couvrant le nom du client. C’est pourquoi, avant de pouvoir rechercher les erreurs dans un ensemble de données, vous devez commencer par analyser les enregistrements et les champs pour obtenir les composants qui doivent être testés pour la normalisation.
b. Rapport sur le profil des données du bâtiment
L’étape suivante consiste à faire passer les composants analysés par un système de profilage. Un outil de profilage des données présente différentes statistiques sur les attributs des données, telles que
- Combien de valeurs dans une colonne respectent le type, le format et le modèle de données requis ?
- Quel est le nombre moyen de caractères présents dans une colonne ?
- Quelles sont les valeurs minimales et maximales présentes dans une colonne numérique ?
- Quelles sont les valeurs les plus courantes présentes dans une colonne et combien de fois apparaissent-elles ?
c. Correspondance et validation des modèles
Bien que les outils de profilage des données fassent état des correspondances de motifs, étant donné qu’il s’agit d’une partie importante des tests de normalisation des données, nous allons en parler un peu plus en profondeur. Pour faire correspondre des motifs, vous devez d’abord définir une expression régulière standard pour un champ. Par exemple, une expression régulière pour les adresses électroniques peut être : ^[a-zA-Z0-9+_ .-]+@[a-zA-Z0-9 .-]+$. Toutes les adresses électroniques qui ne suivent pas le modèle donné doivent être signalées pendant le test.
d. Utilisation des dictionnaires
La normalisation de certains champs de données peut être testée en comparant les valeurs avec des dictionnaires ou des bases de connaissances. Vous pouvez également les exécuter contre des dictionnaires créés sur mesure. Il s’agit souvent de faire correspondre des fautes d’orthographe, des abréviations ou des noms raccourcis. Par exemple, les noms de sociétés comprennent généralement des termes tels que LLC, Inc, Ltd, et Corp, etc. En les comparant à un dictionnaire rempli de ces termes standard, vous pourrez identifier ceux qui ne respectent pas la norme requise ou qui sont mal orthographiés.
En savoir plus sur l’utilisation de wordsmith pour éliminer le bruit et normaliser les données en vrac.
e. Adresses de test pour la normalisation
Lorsque vous testez des données à des fins de normalisation, vous pouvez être amené à tester des champs spécialisés, tels que des lieux ou des adresses. La normalisation des adresses est le processus qui consiste à vérifier le format des adresses par rapport à une base de données faisant autorité – comme l’USPS aux États-Unis – et à convertir les informations relatives aux adresses dans un format acceptable et normalisé.
Une adresse normalisée doit être correctement orthographiée, formatée, abrégée, géocodée, ainsi que complétée par des valeurs ZIP+4 précises. Toutes les adresses qui ne sont pas conformes à la norme requise (en particulier les adresses qui sont censées recevoir des livraisons et des envois) doivent être signalées afin qu’elles puissent être transformées si nécessaire.
Lire la suite : Un guide rapide de la normalisation et de la vérification des adresses.
Enterprise Content Solutions uses DataMatch Enterprise
Enterprise Content Solutions found 24% higher matches than other vendors for inconsistent address records.
Read case study3. Transformer
Dans la troisième étape du processus de normalisation des données, il est enfin temps de convertir les valeurs non conformes dans un format normalisé. Cela peut inclure :
- Transformer les types de données des champs, par exemple convertir le numéro de téléphone d’une chaîne de caractères en un type de données entier et éliminer tous les caractères ou symboles présents dans les numéros de téléphone pour obtenir un numéro à 8 chiffres.
- Transformer les modèles et les formats, par exemple en convertissant les dates présentes dans l’ensemble de données au format MM/JJ/AAAA.
- Transformation des unités de mesure, comme la conversion des prix des produits en USD.
- Expansion des valeurs abrégées pour compléter les formulaires, par exemple en remplaçant les états américains abrégés : NY pour New York, NJ pour New Jersey, et ainsi de suite.
- Suppression du bruit présent dans les valeurs des données pour obtenir des informations plus significatives, par exemple en supprimant les termes LLC, Inc. et Corp. des noms de sociétés pour obtenir les noms réels sans aucun bruit.
- Reconstruire les valeurs dans un format standardisé au cas où elles devraient être mises en correspondance avec une nouvelle application ou un hub de données, comme un système de gestion des données de base.
Toutes ces transformations peuvent être effectuées manuellement – ce qui peut prendre du temps et être improductif – ou vous pouvez utiliser des outils automatisés qui peuvent vous aider à nettoyer les données en automatisant pour vous les phases de test et de transformation standard.
4. Retester pour la norme
Une fois le processus de transformation terminé, il est bon de tester à nouveau l’ensemble de données pour détecter les erreurs de normalisation. Les rapports avant et après normalisation peuvent être comparés pour comprendre dans quelle mesure les erreurs de données ont été corrigées par les processus configurés et comment ils peuvent être améliorés pour obtenir de meilleurs résultats.
Utilisation d’outils de normalisation des données en libre-service
Aujourd’hui, les données sont saisies manuellement, mais aussi capturées et générées automatiquement. Dans le cadre du traitement de grands volumes de données, les organisations se retrouvent avec des millions d’enregistrements contenant des modèles, des types de données et des formats incohérents. Et chaque fois qu’elles veulent utiliser ces données, les équipes sont bombardées d’heures de vérification manuelle du format et de correction des moindres détails avant que les informations puissent être jugées utiles.
De nombreuses entreprises se rendent compte de l’importance de fournir à leurs équipes des outils de normalisation des données en libre-service, avec des fonctions intégrées de nettoyage des données. L’adoption de tels outils peut aider votre équipe à exécuter des techniques complexes de nettoyage et de normalisation des données sur des millions d’enregistrements en quelques minutes.
DataMatch Enterprise est l’un de ces outils qui aide les équipes chargées des données à rectifier les erreurs de normalisation des données avec rapidité et précision, et leur permet de se concentrer sur des tâches plus importantes. Pour en savoir plus sur la façon dont DataMatch Enterprise peut vous aider, vous pouvez télécharger un essai gratuit aujourd’hui ou réserver une démonstration avec un expert.



