































Last Updated on April 10, 2026
Poor data standardization is a hidden profit killer. When customer names, products, or sales figures appear in different formats across systems (and often even within the same application), it hampers decision-making, inflates operational costs, and exposes businesses to unnecessary risks.
Inconsistent data slows down everything from routine operations to advanced analytics and leaves organizations vulnerable to costly mistakes. However, for enterprises relying on multiple SaaS platforms and in-house applications, data discrepancies across systems are almost inevitable. This is why data standardization is imperative.
By enforcing data standardization, businesses can eliminate these discrepancies, streamline data flaws, and ensure that every decision is based on consistent, high-quality information. The result is not just cleaner data, but improved efficiency, more accurate insights, and stronger, data-driven outcomes.
What is Data Standardization?

In the data world, a standard refers to a uniform format or structure that all data values in a given domain must conform to. Data standardization is the process of transforming an incorrect or unacceptable representation of data into an acceptable form.
The easiest way to know what is ‘acceptable’ is to understand your business requirements. Ideally, organizations must ensure that the data models utilized by most – if not all – applications should conform to their business needs. The best way to achieve standardization of data is to align your data representation, structure, and definition to organizational requirements.
Contrary to what many may believe, data standardization isn’t just tidying up information in your databases – it’s about building a foundation of clean, reliable data that powers growth. Standardizing the way data is represented ensures that all systems speak the same language. This makes it easier for data professionals to extract meaningful insights, make accurate decisions, improve customer experiences, and streamline operations.
Types and Examples of Data Standardization Errors

From mismatched formats to structural inconsistencies, unstandardized data can manifest in various forms, slowing down processes and making it difficult to extract value. Here are some common examples of data standardization errors:
1. Data Type Inconsistency:
This occurs when different systems store the same information as different data types. For example, one system might store a Customer’s Phone Number as a string (text) with characters like dashes or parentheses, while another system only allows it to be a number with exactly 10 digits. This inconsistency can lead to errors during data integration and processing.
2. Structural Inconsistency:
Structural inconsistencies happen when the format or organization of data fields differs between systems. For example, one application might store Customer Name as a single field, while another breaks it down into first, middle, and last names. This data inconsistency makes it difficult to combine or analyze data effectively.
3. Format Inconsistency:
This type of data standardization error arises when the same type of data is presented in different formats across systems. For instance, a Customer’s Date of Birth might has the format MM/DD/YYY (numeric format – such as 09/15/2024) in one system and Month Day, Year (textual format, like September 15, 2024) in another system. These differing formats can make it challenging to compare, aggregate, or analyze data across systems if a consistent standard is not applied.
4. Domain Value Inconsistency:
Domain value inconsistency occurs when data values are represented differently across systems. For example, Customer Gender might be listed as “Female” or “Male” in one system, while another uses “F” or “M”. It creates confusion during data analysis.
5. Human Errors and Data Entry Mistakes:
Apart from these common scenarios, misspellings, abbreviations, typos, transcribing errors, and lack of validation constraints can also increase data standardization errors and result in incomplete or inaccurate datasets.
Why Do You Need to Standardize Data?

Every system has its own set of limitations and restrictions, which lead to unique data models and their definitions. For this reason, organizations may need to transform data before it can be correctly consumed by any business process. Standardization is also necessary to address inconsistencies and errors and achieve accurate, reliable data for effective decision-making.
Standardizing data is not just a technical necessity; it’s a strategic requirement for any business aiming to harness the full potential of its data. Here are key reasons why data standardization is essential:
1. To Conform Incoming or Outgoing Data
Organizations frequently exchange data points with external stakeholders such as vendors or partners. This is done through multiple interfaces. Without standardization, the incoming and outgoing data can vary in format and structure and create integration challenges and data quality issues. For example, if your CRM system receives customer data from a partner in different formats (e.g., phone numbers as text vs. numeric) inconsistencies can arise in datasets.
Standardizing data ensures that all incoming and outgoing information adheres to the same format and definitions. It ensures uniformity, reduces errors, and streamlines data integration processes.
2. To Prepare Data for Business Intelligence (BI) or Analytics
As discussed above, same data can be represented in multiple ways. However, most BI tools are not specialized to process every possible representation of data values. As a result, it may end up treating the same data differently. This can lead to biased or inaccurate BI results. Therefore, the data must be cleaned, standardized, and deduplicated before it is fed into the BI systems to ensure correct, valuable insights that drive better decision-making and strategy formulation.
3. To Consolidate Entities to Eliminate Duplicates
Data duplication is one of the biggest data quality hazards businesses deal with. For efficient and error-free business operations, you must eliminate duplicate records that belong to the same entity (whether for a customer, product, location, or employee), and an effective data deduplication process requires you to comply with data quality standards.
Standardization helps consolidate records, eliminate redundancies, and ensures that each entity is represented only once, which enhances data accuracy and operational efficiency.
4. To Share Data Between Departments
For data to be interoperable between departments, it has to be in a format that is understandable by everyone. However, in reality, different departments within an organization may use varied data systems and formats. This can delay task completion and create roadblocks in team productivity.
Data standardization facilitates seamless data sharing and communication and ensures that information is interoperable across departments.
The Benefits of Data Standardization

Data standardization offers a range of advantages, making it an essential process for any organization aiming to improve and optimize its data management practices. It ensures:
- Consistency: Data standardization converts all data entries into the same format, reduces errors, and improve accuracy.
- Efficiency: Standardized data dramatically speeds up various business processes and prevents costly delays caused by manual data correction.
- Interoperability: Data standardization enables seamless data sharing across departments and systems.
- Compliance: Standardizing data helps meet regulatory requirements that certain industries may have for data handling and governance.
Data standardization can fundamentally transform how organizations operate.
Standardized data enables data-driven decision-making, improves operational efficiency, and ensures adherence to industry regulations and protocols. It’s an investment that yields long-term gains by reducing costs associated with poor data management and positioning organizations for success.
Data Cleansing versus Data Standardization

The terms data cleansing and data standardization are often used interchangeably. But there is a slight difference between the two.
Data Cleansing
Data cleansing is the process of identifying incorrect or dirty data and replacing it with correct values. This involves tasks such as:
- Removing Duplicates: Identifying and eliminating duplicate records to ensure each data point is unique.
- Correcting Errors: Fixing typographical errors, misspellings, and incorrect entries.
- Filling in Missing Data: Addressing gaps in the dataset by inputting missing values (where appropriate) or using data imputation techniques.
Data Standardization
Data standardization refers to the process of converting data values into an acceptable, consistent format across different systems and datasets. This involves:
- Consistent Formatting: Ensuring that data is represented in a uniform format, such as using the same date or phone number format across all systems.
- Uniform Definitions: Aligning definitions and values, such as using standardized codes or terms for categories, such as “Male” or “M” for gender.
Despite these differences, the purpose (and outcomes) of both these processes is similar – to eliminate inaccuracy and inconsistency from datasets. Both processes are vital to data quality management initiatives and must go hand-in-hand.
How to Standardize Data?

Data standardization is a structured process to ensure consistency across your datasets. It includes four simple steps: define, test, transform, and retest. Let’s go over each step in a bit more detail.
1. Define a Standard
The first step in data standardization process is to establish clear standards that align with your organizational needs. The best way to define a standard is by designing a data model for your enterprise. This data model will represent the most ideal state that data values for a certain entity must conform to.
Designing a data model involves:
- Identifying Key Data Assets: Determine the data elements that are vital to your business operations, such as customer details, product information, or financial records.
- Defining Data Fields and Structure: Outline what information each data field should contain and how it should be structured. For example, a customer profile might include fields for Name, Address, Email, and Phone Number – where the Name field spans over three fields and Address field spans over two.
- Setting Data Types and Limits: Assign a data type to every field identified in the asset. For example, the Name field is a string value, Phone Number is an integer value, and so on. Also, specify the character or numeric limits. For instance, a phone number might be restricted to 10 digits and a name to 15 characters, etc. You may also set minimum character limits.
- Establishing Patterns and Formats: Determine the patterns and formats that data fields must adhere to – this may not be applicable to all fields. For example, every customer’s email address should adhere to the regex: [chars]@[chars].[chars] or date must follow the MM/DD/YYYY format.
- Defining Measuring Unit for Numeric Values (if applicable): For example, customer’s Age is measured by Years.
- Creating Value Domains: Define acceptable values for fields that have predefined options, such as Customer Age must be a digit within 18 and 50, Gender must be Male or Female, Status must be Active or Inactive, and so on.
Once designed, the data model can be placed in an ERD class diagram to help visualize the defined standard for every data asset and how they relate to each other. An example standardized data model for a retail company can be:
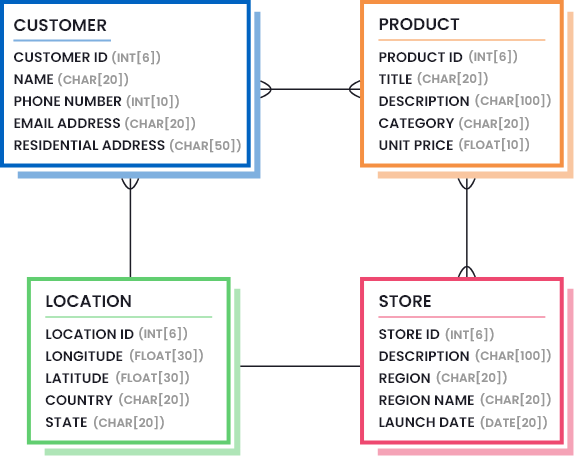
2. Test for Standard
Actual data standardization starts at the second step, since the first step only focuses on defining the standards – something that is done once or incrementally reviewed and updated every once in a while.
Once you have defined the standards, the next step is to assess how well your current data conforms to them. Below, we go through a number of techniques that test data values for standardization errors and build a standardization report that highlights inconsistencies and thus, can be used for fixing the issues.
a. Parsing Records and Attributes
Designing a data model is the most crucial part of data management. But unfortunately, many organizations do not design data models and set common data standards in time or the applications they use do not have customizable data models – leading them to capture data in varying field names and structure.
When you collect information from different systems, you might notice that some records return a customer’s name as a single field while others return three or even four fields covering a customer’s name. For this reason, before any dataset can be screened for errors, you must start by parsing records and fields to attain the components that needed to be tested for standardization.
Parsing records and attributes help figure out how data is stored (structured) across different systems and uncover inconsistent data models.
Example: One system might list customer names as a single field, while another separates them into “First Name” and “Last Name” fields. Parsing these records allows you to identify mismatches and ensure the data follows a uniform structure across systems.
b. Building a Data Profile Report
The next step is to run the parsed components through a profiling system. A data profiling tool reports on different statistics about data attributes, such as:
- How many values in a column follow the required data type, format, and pattern?
- The average number of characters present in a column.
- The most minimum and maximum values present in a numeric column.
- The most common values present in a column and their frequency (how many times do they appear?)
A data profile report provides key insights into the quality of data. Most importantly, it reveals inconsistencies that might not be immediately obvious.
Example: A data profile report might reveal that 20% of a customer address column contains values that exceed the maximum character length defined in your standard, which indicates a need for further cleansing.
c. Matching and Validating Patterns
Pattern matching is crucial to verify that data adheres to the established standards.
Although data profiling tools do report on pattern matches, we are discussing it separately (in a little more depth) because it is an important part of data standardization testing. Pattern mismatches can reveal inconsistent or incorrect data entries that need fixing.
To match patterns, you need to first define a standard regular expression (regex) for a field. This helps flag any entries that do not conform to this pattern during testing.
Example: For email addresses, a regular expression such as ^[a-zA-Z0-9+_.-]+@[a-zA-Z0-9.-]+$ can be applied to identify email addresses that do not follow the given pattern.
d. Using Dictionaries for Validation
Certain data fields can be tested for standardization by running values against dictionaries or knowledge bases. You can also run them against custom-created dictionaries. This is often done to identify inconsistencies like misspellings, non-standard abbreviations, or shortened names that require correction.
Example: Company names usually include terms like LLC, Inc., Ltd., and Corp. Running them against a dictionary full of such standard terms can help identify which ones do not follow the required standard or are spelled incorrectly.
Read more about Using wordsmith to remove noise and standardize data in bulk.
e. Testing Specialized Fields
While testing data for standardization, you may need to test specialized fields, such as locations or addresses.
Address standardization involves checking the format of addresses against an authoritative database – such as USPS (in the US) or other postal services – and converting address information into acceptable, standardized format.
A standardized address should be correctly spelled out, formatted, abbreviated, geocoded, as well as appended with accurate ZIP+4 values. All addresses that do not conform to the required standard (especially addresses that are supposed to receive deliveries and shipments) must be flagged so that they can be transformed as needed.
Address testing tools can validate whether data aligns with postal standards. This ensures that shipments are sent to the correct locations and helps avoid unnecessary delays or costs.
Read more: A quick guide to address standardization and verification.
Enterprise Content Solutions uses DataMatch Enterprise
Enterprise Content Solutions found 24% higher matches than other vendors for inconsistent address records.
Read case study3. Transform
In the third step of the data standardization process, it is finally time for implementing data standards and convert the non-conforming values into a standardized format. This can include:
- Converting Field Data Types, such as, converting Phone Numbers stored as strings into integers and eliminating any characters or symbols present in phone numbers to attain the 10-digit number.
- Transforming Data Patterns and Formats, such as converting date formats from DD/MM/YYYY or Month Day, Year to MM/DD/YYYY.
- Updating Measurement Units, such as converting product prices to a consistent currency like USD. The purpose is to standardize units of measurement.
- Expanding Abbreviations to complete forms, such as replacing NY to New York, NJ to New Jersey, and so on.
- Removing Noise present in data values to attain more meaningful information, such as removing LLC, Inc., and Corp. from company names to get the actual names without any noise. The purpose is to eliminate redundant, irrelevant, or useless information from data fields.
- Reconstructing the Values in a standardized format in case they need to be mapped to a new application or a data hub, like a master data management system.
All these transformations can be done manually. However, it will be a time consuming and unproductive process. Thankfully, there are automated tools that can help simplify the task and clean data for you by automating the standard testing and transforming phases.
4. Retest for Standardization
It is a good practice to retest the dataset for standardization errors once the transformation process is complete.
For this, compare the pre and post standardization reports to understand the extent to which data errors were fixed by the configured processes (evaluate the effectiveness of the transformation process) and any areas for improvement to reach even better results.
Using Self-Service Data Standardization Tools
Nowadays, data is manually entered, as well as automatically captured and generated. In the midst of handling large volumes of data, organizations are stuck with millions of records containing inconsistent patterns, data types, and formats. And whenever they want to use this data, teams are bombarded with hours of manual format checking and correcting every little detail before the information can be deemed useful.
Many businesses are realizing the importance of providing their teams with self-service data standardization tools that come with inbuilt data cleansing features too. Adopting such tools can help your team execute complex data cleansing and standardizing techniques on millions of records in a matter of minutes.
DataMatch Enterprise is one such tool that facilitates data teams in rectifying data standardization errors with speed and accuracy, and allows them to focus on more important tasks. To know more about how DataMatch Enterprise can help, you can download a free trial today or book a demo with an expert.

