































Last Updated on January 2, 2026
Most data problems don’t show up as dramatic failures. They appear as small problems or hide in plain sight. A number that needs to be cross-checked, a record that doesn’t match across systems, or a report that feels slightly off but no one can explain why.
In an industry survey, 91% of the participants admitted that the data used for key decisions in their companies is often (51%) or sometimes (40%) inaccurate.
Teams work around these gaps every day, assuming this is just how the business runs. But what they don’t realize is that this is where the real cost often sits. Data accuracy impact is immediate and, often, big.
When accuracy and consistency of data slip, so does the organization’s ability to make fast, confident decisions. And its impact shows up in slower revenue cycles, inefficient operations, and workflows that rely on manual checks simply because teams don’t trust the data as much as they should.
If you’re dealing with these symptoms, tools like DataMatch Enterprise (DME) by Data Ladder help organizations detect, fix, and prevent data accuracy issues across systems, without replacing existing tech.

Why Accuracy and Consistency Break Down in Mature Data Environments
Data doesn’t become inaccurate overnight. It drifts, usually unnoticed or in ways that feel harmless in the moment.
In mature environments (with multiple systems, long-running processes, and complex ownership) that drift becomes almost inevitable unless it’s actively managed.
Most accuracy and consistency issues trace back to a few recurring patterns. These include:
1. Entity Duplication Across Systems
It typically starts with something small and routine.
Like:
Sales creates an account in the CRM. Finance creates a slightly different version in the billing system. Marketing imports a list where the name is spelled a third way.
And just like that, you’ve got three versions of the same entity floating around.
Here’s how the data accuracy impact typically shows up on the bottom line:
- Sales forecasts skew because pipeline revenue is split across duplicates.
Billing teams chase the wrong “primary” account or waste time reconciling “primary” vs “secondary” records. - Marketing automations target the same customer multiple times, or miss them entirely because segments don’t reflect reality.
- Teams engage in territory planning based on distorted customer count.
Entity duplication is often where data accuracy begins to slip, and it happens quietly.
2. Schema Drift Over Time
No one plans for schema drift. It just happens as teams evolve systems to fit daily needs.
A file named “phone” becomes “telephone” in another system. “SKU” becomes “ItemCode.” One database stores timestamps in UTC, another in local time.
Individually, these differences look pretty harmless. But, over time, small differences like these break matching logic, integrations, and reconciliation workflows. Teams typically begin to notice the problem when:
- Routine syncs fail for reasons no one can immediately explain.
- Dashboards show conflicting totals.
- Analysts spend hours mapping or renaming fields instead of actually analyzing data.
The system still runs, but it becomes less trustworthy month after month.
3. Legacy Systems with Weak or No Validation Rules
Older systems weren’t built with today’s data demands in mind. Most of them (if not all) tend to accept anything: free-text addresses, incomplete phone numbers, malformed IDs.
When this data flows downstream into modern tools that expect structure, everything slows down. The data accuracy impact, in this situation, is usually felt in places like:
- Matching engines that misidentify records (causing false positives and false negatives).
- Automations that halt because mandatory fields don’t meet expected rules.
- Cleanup cycles, where reporting teams manually patch missing or invalid values every month.
Eventually, teams end up with workflows where data accuracy issues are baked into the foundation.
4. Conflicting Reference Data and Silo-Specific Naming Conventions
This one is more cultural than technical.
Two departments may refer to the same product by different names. Or maintain their own versions of reference tables, pricing tiers, region codes, or product families, with each updated on its own schedule. This doesn’t cause any system or process to break outright, but the misalignment creates friction leading to:
- Inconsistent classification of customers and products
- Revenue leakage when discounts or tiers don’t sync
- Operational disputes over “which version is correct” during audits
These inconsistencies matter most when decisions require cross-department alignment. And this is where data accuracy stops being a technical discussion and becomes an operational one.
5. ETL Pipelines That Replicate Errors at Scale
Once an inaccurate value enters an ETL pipeline, the pipeline doesn’t fix it; it replicates it.
ETL’s job is to copy, transform, enrich, and load data into multiple downstream systems. If the source is inconsistent, every replication multiplies the problem. Ultimately, all systems display the same flaw in perfect synchronization.
Common symptoms of it include:
- Errors appearing simultaneously in all tools or systems
- Fixes in one system don’t cascade because the pipeline reintroduces issues
- Teams stop relying on “system of record” claims because every system disagrees
This is how a small mismatch, inconsistency, or lack of data accuracy impact the entire workflow and becomes an organization-wide problem simply because your pipelines are doing their job.
DataMatch Enterprise (DME) can help prevent this breakdown by combining data profiling, deduplication, matching, cleansing, standardization, and cross-system normalization into repeatable enterprise workflows, stopping bad data before it spreads downstream. bad data from flowing downstream.
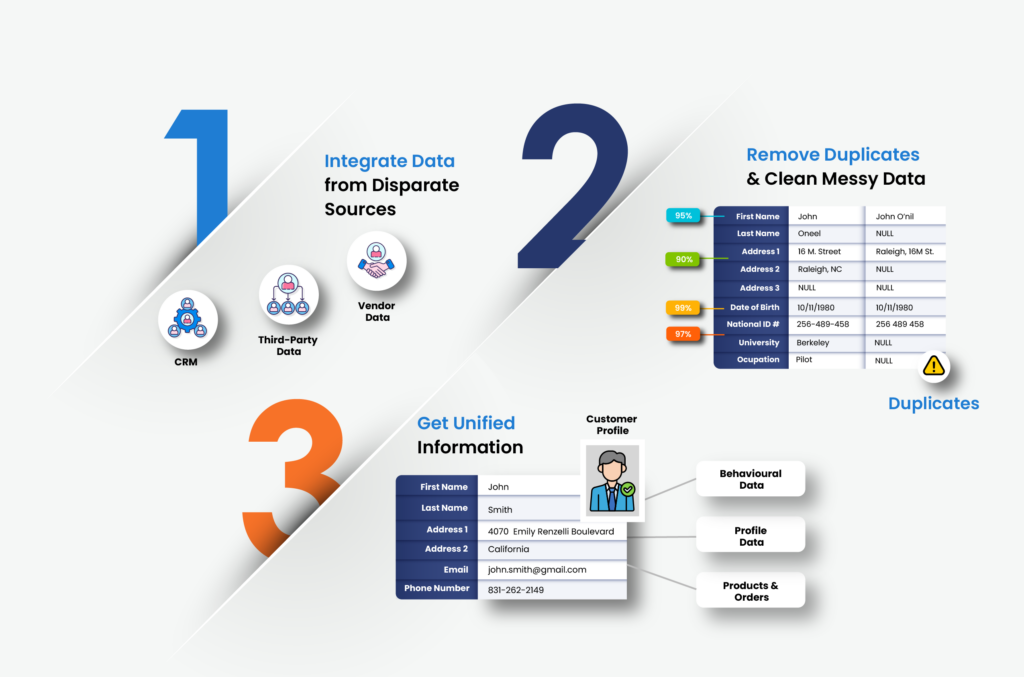
What "Data Accuracy" Really Means
Most people think of data accuracy as “the correct information.” It is true, but that definition is too shallow to be useful. In real business scenarios, data accuracy means:
- The value represents the real-world entity correctly.
- It’s up to date.
- It hasn’t been mistyped, duplicated, corrupted, or guessed.
- And it actually helps the system do what it was designed to do.
For example, a customer’s email address isn’t just a field in a CRM. It determines whether a welcome email lands in the right inbox, whether password resets work, whether support teams can respond promptly, and whether marketing can send a targeted offer. One wrong character in that field breaks multiple workflows.
When talking about data accuracy, it also helps to understand what it is not.
- Completeness: It means the data exists.
- Consistency: It means it matches across systems.
- Timeliness: It means it’s recent.
Accuracy connects all of these. You can have a complete, consistent, and recent record, and still have the wrong phone number or outdated address.
Accurate data is data you can trust without second-guessing it. Everything else creates noise.
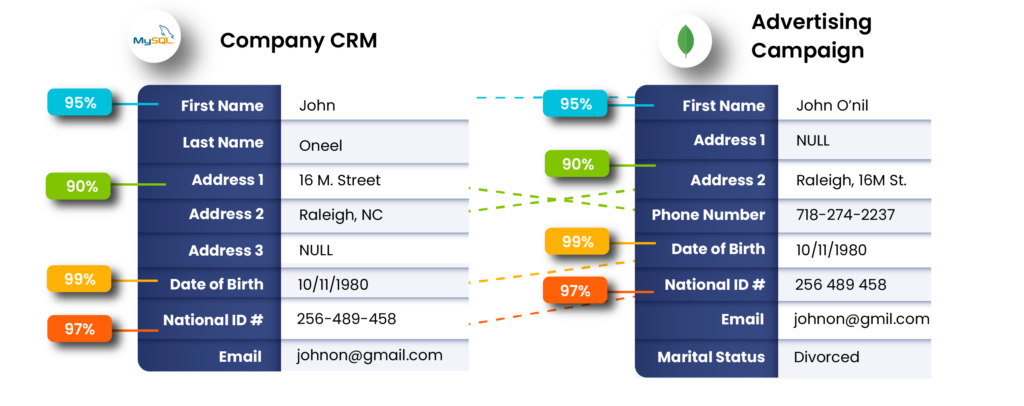
Where the Money Leaks: The Direct Financial Impact of Inaccurate or Inconsistent Data

Data issues don’t just slow teams down; they also quietly chip away at revenue from multiple directions.
Quite often, by the time leadership notices the problem, the business has already absorbed months (sometimes years) of avoidable losses.
Here’s how and where accuracy and consistency failures typically translate directly into dollars:
a. Revenue loss hidden inside customer and product data issues
Revenue leakage usually starts with small mismatches in customer or product data. Here are some common situations that these small problems can create:
- Missed renewals because contact data is inconsistent across systems.
A renewal reminder goes to an outdated email in the CRM. Ops teams assume the customer is unresponsive. But in reality, the reminder never reached them. - Failed deliveries or order cancelations due to inaccurate addresses.
Orders bounce back because shipping and billing systems don’t align. As a result, costs rise and customer satisfaction drops, both of which hit revenue. - SKU mismatches that create artificial stockouts.
Warehouse has inventory, but the e-commerce or POS system thinks the item is available. Sales momentum stalls for no operational reason. - Cross-sell and upsell models failing because duplicates split customer history.
When a customer’s behavior is scattered across multiple profiles, recommendation models can’t see the full picture. As a result, many high-value opportunities can go unnoticed.
These problems don’t appear in dashboards labeled as “data accuracy impact.” They show up as declining conversions, slower sales cycles, and lost revenue that, on the face of it, looks like a market problem, not a data problem.
b. Cost inflation across operations
Inaccurate or inconsistent data forces organizations to operate with more friction and more headcount than necessary. These costs compound over time. Typical impacts include:
- Duplicate vendor and product records drive unnecessary purchasing.
Procurement end up ordering materials already in stock because the system lists them under a slightly different name or ID. - Manual reconciliation becomes a daily workload.
Finance, ops, and analytics teams spend hours each week validating totals between CRM, ERP, billing, and reporting systems. Multiply that by dozens of employees, and the labor cost becomes substantial. - Support teams repeatedly clean up downstream workflow errors.
Tickets surge due to failures that originate from inconsistent data formats, incomplete inputs, or input attributes entered upstream.
You don’t see these costs on a single line item, but they show up in bloated workloads, rising overtime, and “temporary” manual fixes that turn into permanent processes.
c. Automation and integration failures
Automation delivers ROI only when the data feeding it is predictable. When it isn’t, not only the automation fails, but the cost of operations also increases.
For example:
- RPA workflows break because inconsistent formats trigger exceptions.
Robots pause and route tasks to humans. Over time, exception handling becomes a bigger workload than the automation itself. - API integrations reject records with incomplete or inaccurate fields.
Sync jobs silently fail, systems fall out of alignment, and teams spend days debugging issues caused by one mismatched attribute. - Analytics models trained on conflicting ground truth produce unreliable outputs.
Forecasts swing unpredictably. Lead scoring becomes inconsistent. Inventory predictions drift.
Leaders lose confidence in analytics, which stalls adoption and devalues prior investments in BI and data science.
These failures create operational drag and increase the cost of maintaining data infrastructure.
d. Compliance and reporting exposure
Accuracy and consistency are also regulatory requirements in many industries. When data doesn’t align, organizations face compliance risk, audit pain, and reputational exposure.
Possible critical scenarios include:
- AML/KYC inconsistencies trigger regulatory flags.
Minor discrepancies across customer profiles can escalate into suspicion of non-compliance. - Financial reports become unreliable due to mismatched transaction records.
Month-end close stretches longer, rework increases, and audit teams push back on questionable numbers. - Audit costs rise because data must be manually validated.
What should be a straightforward review becomes a multi-week reconciliation effort.
When it comes to compliance failures, even a single inconsistent record can cascade into expensive outcomes.
e. Weak customer relationships
If a company can’t remember a customer’s history, preferences, or past issues, the relationship weakens immediately. Some common scenarios that indicate weakening customer relationships include:
- Friction in support interactions.
Support teams waste time searching across systems. Customer have to repeat themselves. Resolution time increases. And, ultimately, small issues escalate into frustration. - Broken personalization.
Customers expect brands to “know” them. Weak personalization makes them feel misunderstood, and directly translates into lost revenue. - Drop in retention rate.
Every bad interaction a customer has with a brand (no matter the reason) chips away at loyalty. And, usually, by the time the churn number shows up on the dashboard, the customer has been emotionally checked out for months.
When customers lose trust, they rarely say it outright. They simply disengage. And nothing erodes customer trust faster than interactions built on inaccurate information.
Over the past decade, Data Ladder has helped enterprises identify the various revenue drains in their systems – duplicate entries, disparate records, inconsistent customer/vendor attributes, etc. – before they reach downstream systems, forecasting, or customer-facing workflows.

The Compounding Impact of Data Accuracy Issues
An inaccurate field rarely stays in one place. Once it enters the system, it doesn’t just sit quietly; it travels. And every system it touches rewrites, reinterprets, or duplicates that inaccuracy in its own way. That’s how a single mistake becomes a chain of inconsistencies that are far more expensive than the original error.
This “multiplication effect” is one of the biggest hidden drivers of data quality cost.
Example:
Here’s an example of how this amplification happens in real life:
- CRM stores the wrong customer address.
Maybe a rep typed it manually. Maybe the customer updated one channel but not another. Nothing looks broken. - The ERP imports the record but formats the address differently.
Now you have two versions of the same wrong value.
- The billing system creates a billing profile based on whichever system synced last.
That becomes version three. - The data warehouse receives all three versions, and doesn’t know which one to treat as the source of truth.
BI dashboards end up showing different customer segments depending on which field they pull. - Marketing pulls its own export and fixes the address manually for a campaign.
Now you have version four, living outside the systems entirely.
This is how one inaccuracy quietly converts into a web of contradictions, each of which costs the business time, money, or trust.
How this multiplier effect matters for your bottom line?
Inconsistency turns every downstream workflow into a risk surface:
More duplicates
CRM splits customer history
Missed upsells
Different product IDs across systems
Financials don't reconcile
Delayed close
Conflicting customer attributes
analytics models produce unreliable predictions
Multiple “truths” during invoicing
Disputes increase
Payments slow down
This is how an inconsistency problem amplifies the data accuracy impact tenfold, and organizations end up spending far more on reconciling inconsistencies than on fixing the original inaccuracies.
Data Accuracy Diagnostic Framework: How to Evaluate Your Organization’s Exposure
Most teams know they have data issues. What they don’t always know is where the exposure is or how deep it runs.
This framework gives senior leaders a practical way to quantify the cost and see where the biggest risks sit.
These are the same indicators organizations typically identify during data quality audits, and the same red flags that surface right before major modernization projects stall.
Use this as a quick internal diagnostic framework/guide:
Diagnostic Area
What to Measure/Indicators / Thresholds
What It Reveals
Conflicting Records Across Core Systems
% of records with conflicting values Number of fields that fail to match (address, IDs, phone, status). Volume of blank/unknown fields in key entities.
Conflicting data shows inaccuracies multiplying across the ecosystem.
Match Rate Between Major Systems
Healthy environment: 85–95%+ match rate. Anything lower signals systemic inconsistency.
Low match rates slow processes, delay reconciliations, and increase manual workload.
Duplicate Entities
Double mailings, bad segmentation Payment mismatches, AP rework
Forecasting and fulfillment issues. Lost cross-sell opportunities.
Critical threshold: >2–3% duplicates.
Small duplicate percentages create outsized operational and financial drag.
Transactions Requiring Manual Review
Orders needing approval. Invoices flagged for mismatches Payments routed for exceptions Shipments needing address fixes.
Risk threshold: >5–10% manual intervention
A clear signal that data inconsistencies are burdening operations.
Revenue or Delivery Failures Linked to Data Issues
Returned shipments
Delayed invoices
Incorrect pricing
Contracts with outdated info
Many “process problems” are actually rooted in inaccurate or inconsistent data.
Time Spent Reconciling Reports
Time spent fixing numbers during close.
Time spent aligning pipeline/bookings.
Multiple versions of the same KPI circulating.
If teams spend days, not hours, reconciling reports, it signals a core data quality exposure.
By the time a company sees measurable gaps in these areas, the cost of inaccuracy and inconsistency has already reached the bottom line.
This framework helps quantify the exposure so you can size the problem before investing in a solution.
How to Fix Your Data Accuracy Impact? What an Enterprise-Grade Data Accuracy Program Requires
Most teams can fix a broken record or write a quick script to clean a file. But building reliable accuracy at scale is a different game.
Enterprise data flows through dozens of systems, formats, and workflows, and accuracy breaks anywhere you don’t have structure, governance, and repeatability.
A modern data accuracy program needs a few non-negotiable capabilities:

1. Profiling at Ingestion
You can’t fix what you can’t see.
Accurate data starts with profiling every dataset the moment it enters the system. This involves catching validation issues, broken formats, missing values, and out-of-pattern records before they spread downstream. This is where teams usually realize that 30–40% of issues were never visible in the first place.

2. Cross-System Matching and Deduplication
Enterprises need reliable cross-system matching and deduplication to ensure that customers, vendors, and products are represented consistently across platforms. Without it, accuracy collapses as records fragment and multiply.

3. Standardization Across Formats and Codes
Standardization ensures every system speaks the same language, from date formats to category codes, product descriptions, and naming conventions.

4. Reference Data Alignment
Accuracy relies on more than internal data cleanup.
You also need alignment with external reference sets, like postal data, country/region codes, industry lists, regulatory classifications, so your records match the outside world, not just internal rules.

5. Rule-Based Validation and Survivorship
Fixing accuracy once doesn’t solve accuracy forever.
You need reusable rules that automatically validate new data, enforce business logic, and determine which values should “win” when multiple sources conflict. This eliminates manual checks and opinion-driven decisions that slow teams down.

6. Monitoring, Auditability, and Trend Visibility
Maintaining a positive data accuracy impact is an operational capability; not a one-time project.
You need ongoing monitoring that flags declines, surfaces anomalies, and lets teams trace when and where an issue began. This is what prevents accuracy problems from quietly eroding trust again.
7. The Ability to Scale — Really Scale
Enterprise accuracy isn’t meaningful if it breaks at volume.
The program must process millions of records quickly, maintain performance as datasets grow, and integrate cleanly with existing systems and pipelines.

This is exactly where DataMatch Enterprise excels. It enables organization to:
- Profile and assess data quality.
- Standardize and normalize fields.
- Match and merge entities accurately.
- Build repeatable cleansing pipelines.
If you want an accuracy workflow that scales with your business, Data Ladder helps you build that foundation.
Conclusion: Data Accuracy Is Now a Revenue Strategy
For years, data accuracy and consistency were treated as housekeeping; something teams would “get to” once the urgent work was done. But today, they sit at the center of how revenue is generated, how risk is managed, and how operations actually run.
When your data is accurate, everything downstream moves faster and with more confidence.
Revenue cycles tighten. Integration issues fade. Teams stop relying on manual checks. Decisions become clearer because they’re grounded in facts everyone trusts.
And when your data is wrong, the cost doesn’t stay in the database. It shows up in delayed billing, missed opportunities, compliance exposure, and teams burning hours fixing problems that shouldn’t exist in the first place.
If your organization is seeing rising reconciliation work, inconsistent reports, or a growing gap between what your systems say and what the business experiences, it’s a warning sign.
Book a personalized consultation with our data expert today to find out how we can help you ensure consistency and maintain positive data accuracy impact.
You can also download a free data matching software trial to try working it out yourself.



