































Last Updated on January 28, 2026
Source- to-target mapping usually gets attention for about five minutes, right before a pipeline goes live. After that, it’s assumed to be “done.”
Then months later, someone asks a very ordinary question, like:
why did this field flip from active to inactive for these records?
or
why is a value rounded in the warehouse but not in the source?
And answering it takes far longer than it should. Someone pulls up old SQL. Someone else checks the source system. Eventually, you realize that the mapping document you’re looking at doesn’t quite match what the pipeline is doing anymore.
Good source-to-target mapping isn’t about creating a spreadsheet and moving on. It’s about being able to explain your data behavior without reverse-engineering your own work. Mapping has to reflect reality, not just original intent. And that is exactly where most teams struggle.
Why Most Source-to-Target Mappings Fail (Even When They Look Complete)
Mappings don’t fail immediately. Most source-to-target mappings start out reasonably accurate. They usually break later, often quietly, as the pipeline evolves.
It may be because a new source field gets added. A transformation is adjusted to handle an edge cases. Or a downstream team asks for a “temporary” workaround that never quite gets reversed.
Each change makes sense on its own. And the pipeline keeps running. But the mapping document stays frozen at an earlier version of the truth. It no longer provides clarity, and teams compensate for it by validating outputs manually, reconciling reports, and re-checking logic they thought they’d already documented.
When that happens, source-to-target mapping stops acting as a point of control and starts becoming another variable teams have to work around.
If your mapping does any of the following, it will drift over time:
- Lists source and target columns but describes transformations vaguely
- Assumes SQL or ETL logic is “self-documenting”
- Treats the mapping as a design artifact rather than a runtime reference
- Has no clear explanation for how edge cases or new source values are handled
What Source-to-Target Mapping Actually Controls in a Pipeline
Source-to-target mapping is usually described as a way to document how data moves from a source system to a target table. That description isn’t wrong. It just misses the part that causes trouble later.
In practice, mapping captures a set of decisions. It defines how values are interpreted, how defaults are applied, when transformations occur, and which assumptions are baked into the pipeline. Those decisions don’t stay abstract. They show up downstream as changed values, missing records, duplicated entities, or metrics that no longer line up the way people expect.
This is where source-to-target mapping turns into a control point.
Take something simple, for example, like a status field. On paper, the mapping might say that status_code in the source maps to customer_status in the target. The real behavior, however, depends on the details that are often undocumented, like which codes are filtered out, which ones are defaulted, how nulls are handled, and what happens when a new value appears that wasn’t part of the original logic.
None of that is obvious if the mapping only captures the columns and not the decisions behind them.
The same issue appears with aggregations, deduplication rules, derived fields, and precedence logic across multiple sources. The pipeline may be technically correct, but the meaning of the data shifts based on how and when those transformations are applied. If the mapping doesn’t reflect those choices, it stops being a reliable reference even if it looks complete.
Here’s a simple example showing how proper mapping can transform a basic, error-prone setup to a best-practice approach that ensures clean, validated data across multiple systems:
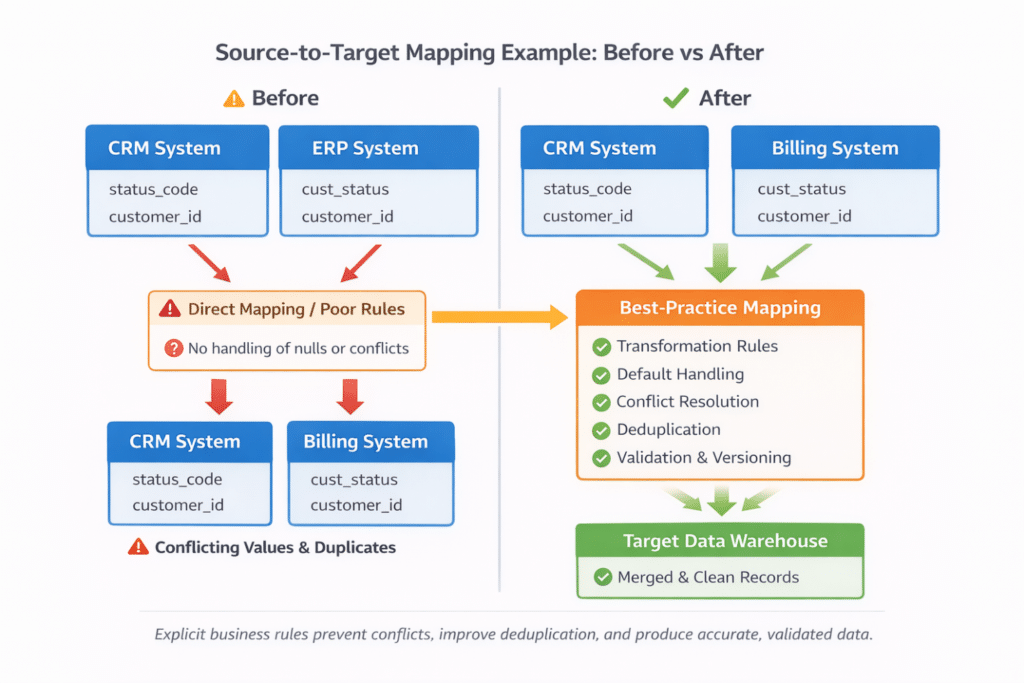
This is why experienced teams treat source-to-target mapping as a way to make data behavior explicit. When someone asks why a value looks different in the target, the mapping should answer that question directly, without having to trace through jobs, scripts, or orchestration logic.
Enterprise-Scale Challenges That Make Mapping Critical
Mapping issues are amplified in large, complex organizations due to:
- Multiple source systems: CRMs, ERPs, billing platforms, and data lakes often feed the same targets, introducing inconsistencies and overlaps
- Schema drift and frequent upstream changes: Source structures evolve, temporary fixes become permanent, and assumptions can break silently
- Cross-team ownership: Different teams manage different systems, pipelines, and reports, making it easy for changes to go undocumented
When these factors combine, poor mapping directly impacts:
- Data quality: Errors propagate silently across the enterprise
- Reporting accuracy: Dashboards and analytics show inconsistent or misleading numbers
- Entity resolution & data matching outcomes: Deduplication, survivorship, and merging logic break, reducing trust in consolidated data
Source-to-Target Mapping Best Practices That Actually Hold Up in Production
If you’ve ever had to debug a pipeline months after it goes live, you know what separates a mapping that works from one that doesn’t. Here are some source-to-target mapping best practices that are the baseline for production-grade data pipelines:
1. Start with Business Rules, Not Just Schema Alignment
Aligning source and target schemas is only the beginning. On its own it does not explain what the data means or how it behaves.
The real meaning of a field is defined by business rules: filters, defaults, conditional logic, and assumptions about valid values. However, in many organizations, these rules exist only informally; in analysts’ heads, inside SQL queries, or scattered across ETL jobs.
That is a fragile foundation.
A strong source-to-target mapping makes transformation logic explicit. It documents assumptions, defaults, conditional paths, default behaviors, and exclusions in language that can be understood without reading code.
This is important because ambiguity is costly. If two engineers could reasonably interpret a mapping differently, it’s not production-grade. A mapping with explicit rules is auditable, repeatable, and explainable.
2. Treat Source-to-Target Mapping as a Living Artifact
Data pipelines are not static, and, therefore, source-to-target mappings cannot be treated as static either.
Schemas change over time. New source systems are added. Analytics requirements evolve. And temporary logic introduced under time pressure often becomes permanent. When these changes are not reflected in the mapping, the document slowly drifts away from reality.
Effective teams treat source-to-target mapping as a living artifact that evolves alongside the pipeline. Versioning is essential, not optional. Changes to transformation logic, source precedence, or field behavior should be reflected in the mapping at the same time they are implemented in production.
More mature teams also consider the downstream impact of change. They ask which reports, dashboards, or models depend on a given field and what might break if its behavior changes.
Rule of Thumb
If your mapping document is older than your last pipeline change, it’s already wrong.
3. Build Validation into the Mapping Process
A mapping that looks correct can still produce incorrect data. In fact, this is one of the most common data mapping failure modes in production pipelines.
Mapping defines intended behavior. Validation confirms whether that behavior is actually occurring.
Source-to-target mapping best practices include defining validation rules alongside the mapping. These checks help teams detect drift early, before incorrect data propagates downstream.
Common validation checks include:
- Record count reconciliation between source and target
- Domain value coverage after code translations
- Key uniqueness after deduplication
- Aggregation tolerance checks for derived metrics
When mapping and validation are treated as a single process, discrepancies are easier to detect and easier to explain.
| Mapping Scenario | Validation Check |
| Aggregation | Totals match within defined tolerance |
| Code translation | All source values map to valid domains |
| Deduplication | Target keys remain unique |
4. Design for Traceability
When questions arise about data, teams need to be able to trace values back to their origins.
They need to know where a value came from, which transformations were applied, and which sources contributed to it. Reconstructing this information after an issue has already surfaced is slow and often incomplete.
For that reason, it’s critical to ensure that each target field is traceable back to its source fields, with all intermediate transformations clearly documented.
This level of traceability supports regulatory compliance, audit readiness, and root-cause analysis. It also plays an increasingly important role in building trust in analytics and AI-driven outputs.
If lineage exists only implicitly in code, the organization is just one incident away from losing confidence in its data.
5. Standardize Naming, Data Types, and Semantics Early
Inconsistent naming and semantics quietly increase mapping complexity.
The same concept may appear under different names across systems. Similar fields may use different data types. Values may look identical while representing slightly different meanings.
Every inconsistency introduces ambiguity, adds friction, and increases the risk of mapping errors.
Effective teams address this by defining canonical naming standards, controlled vocabularies, and consistent data type rules early in the integration process. These standards reduce confusion, simplify mappings, and align them with broader data quality and master data initiatives.
Fixing semantic inconsistency downstream is far more expensive than preventing it upstream. And that’s exactly what experienced teams do.
6. Move Beyond Spreadsheets for Enterprise Mapping
Spreadsheets are popular because they are familiar and fast. But they’re also one of the biggest reasons source-to-target mappings fail at scale.
Spreadsheets may be sufficient for small, short-lived projects. At enterprise scale, however, they become a liability.
They cannot enforce validation rules, track lineage automatically, or support reliable version control. As a result, collaboration becomes difficult, and maintaining accuracy across large, evolving pipelines becomes increasingly unrealistic.
At enterprise scale, tooling decisions are not about convenience. They are about reducing risk, maintaining speed, and preserving trust in the data. If your mapping process depends entirely on spreadsheets alone, drift is not merely a possibility. It is the expected outcome.
| Capability | Spreadsheets | Purpose-Built Mapping Tools |
| Version control | Manual | Built-in |
| Validation | None | Rule-based |
| Lineage | Manual | Automated |
| Scalability | Limited | Designed for scale |
How Data Ladder Supports Mapping Challenges
Maintaining high-quality mappings and reliable data behavior is difficult without tooling that enforces quality and consistency. Data Ladder’s DataMatch Enterprise can help organizations achieve better mapping outcomes through:
- Data Profiling and Cleansing: Helps ensure that source values are consistent and accurate before they’re mapped or transformed.
- Advanced Matching and Deduplication: Uncovers and reconciles inconsistencies across multiple data sources, which often simplifies downstream mapping logic.
- Field-Level Validation and Standardization: Help enforce domain constraints (e.g., valid code sets, standardized formats) that are critical for reliable mapping.
- Merge and Survivorship Logic: Supports the creation of consolidated, trusted records that can serve as reliable inputs to target systems.
- Scalability for Complex Pipelines: Ensures even hundreds of fields and multiple sources remain understandable.
DME acts as a data quality and matching layer that complements source-to-target mapping. It improves confidence in inputs and outputs and, if positioned correctly, can support better mapping outcomes. Download a free Data Ladder trial or book a personalized demo to see how.
Bottom Line
Source-to-target mapping best practices are ultimately about preventing silent change.
Mature data teams do not rely on tribal knowledge, outdated documents, or reverse engineering. They rely on mappings that make data behavior explicit, are validated continuously, support traceability, and stay in sync with the pipeline as it evolves.
When source-to-target mapping is treated this way, it no longer remains an administrative task and becomes a practical mechanism for control, trust, and long-term scalability.



