































Last Updated on July 3, 2026
Data matching software identifies and links records that represent the same real-world entity across one or more datasets, even when names, addresses, or identifiers are formatted inconsistently or partially missing. The right tool depends less on which platform has the longest feature list and more on which one fits the specific matching problem a team is trying to solve.
Most data matching software get compared with a generic feature checklist, star rating, or pricing tiers. While this is a good start, what this format misses is the thing buyers actually need to know i.e. whether the tool fits the specific problem they are trying to solve.
The eight tools in this guide cover a wide range of use cases, from probabilistic record linkage on 100-million-record datasets to no-code CRM deduplication for a marketing ops team. They are not interchangeable, and ranking them on a single scale would not tell you much. Instead, each entry leads with the use case it handles best, followed by a clear read on where it falls short.
Before the comparisons, there is a terminology section worth reading that will help you understand how we’ve rated these tools. The way vendors use terms like data matching, entity resolution, and fuzzy matching has become genuinely inconsistent, and that inconsistency leads to poor buying decisions.
What Counts as Data Matching Software?
Ask five vendors to define data matching and you will get five different answers. Some will describe what is technically a fuzzy matching algorithm. Others will use it interchangeably with entity resolution or even master data management. That inconsistency is not accidental as broader definitions tend to expand the addressable market for any given product.
Before evaluating tools, it is worth being precise about what these terms actually describe and where the boundaries are. The distinctions matter because the tools that handle each problem well are not the same tools. Buying a fuzzy matching software when you need entity resolution or an MDM platform when you need a matching engine are both expensive mistakes.
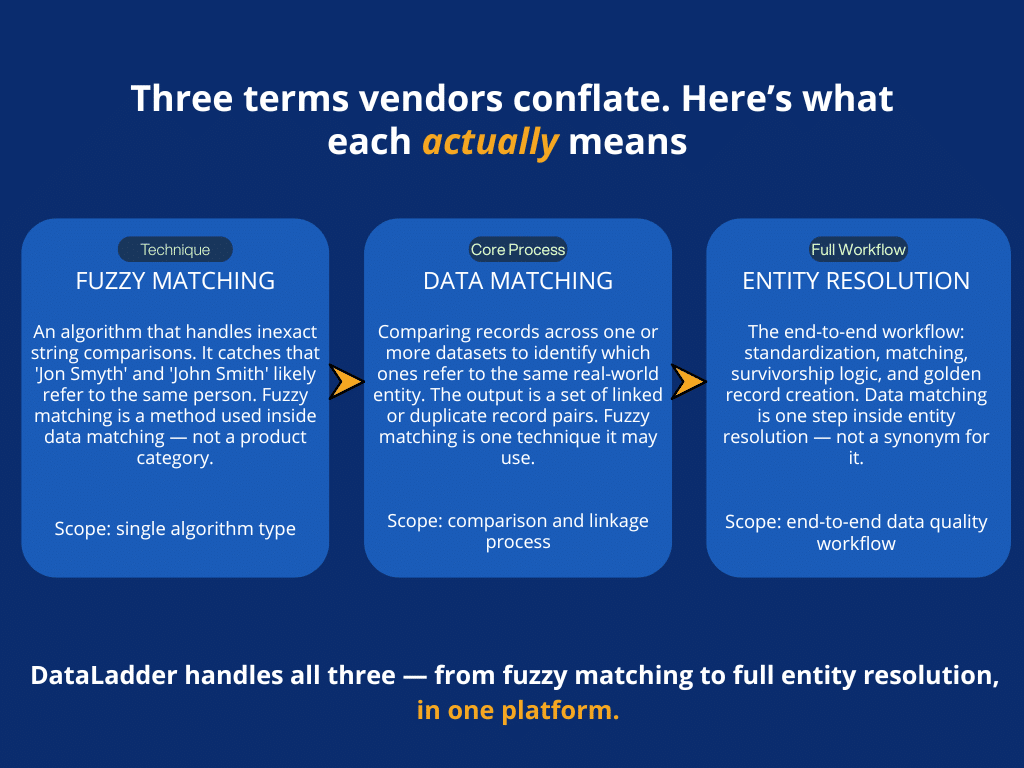
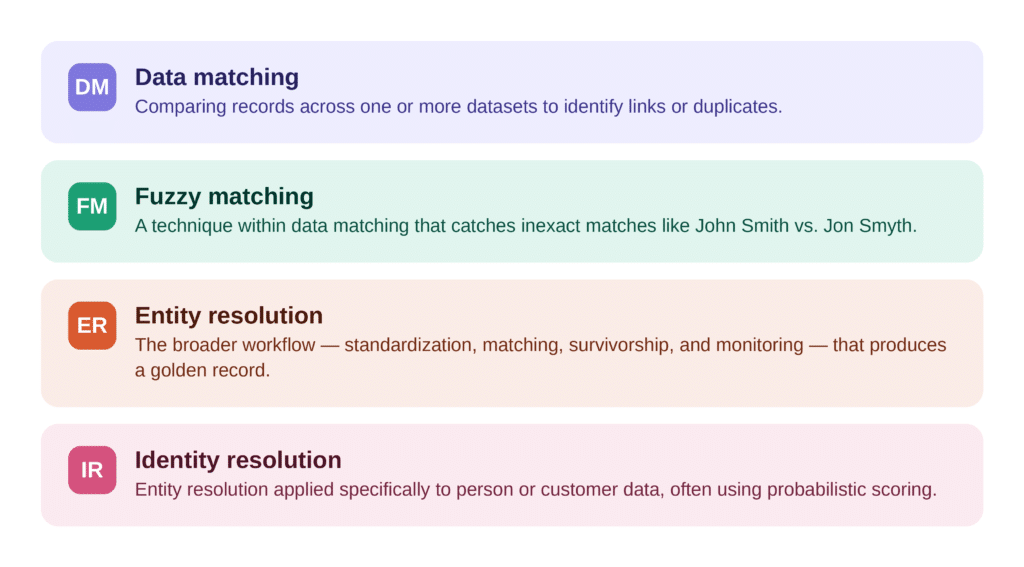
Data matching refers specifically to the process of comparing records across one or more data sets to identify links or duplicate records. The output is a set of record pairs or groups where the same real-world entity appears more than once. That is the core function that any data matching tool handles.
Fuzzy matching is a technique within data matching. It handles inexact comparisons, such as catching that “John Smith” and “Jon Smyth” likely refer to the same person, or that “IBM Corp.” and “International Business Machines” are the same organization. Fuzzy matching is not a product category; it is an algorithm type that any serious matching tool should support.
Entity resolution is the broader workflow that data matching feeds into. It typically includes standardization and parsing (cleaning up input records before comparison), the matching logic itself, survivorship logic (deciding which version of a record to keep or how to create a merged golden record), and ongoing monitoring. Not every tool in this guide does the full workflow, and not every team needs it to.
Identity resolution tends to refer to entity resolution applied specifically to person or customer data, often in a marketing or fraud-detection context. It usually involves external reference data and probabilistic scoring across behavioral signals, contact data, and identifiers to link records.
Key distinction: A tool that does data matching is a component of entity resolution. A tool that does entity resolution includes data matching plus standardization, survivorship, and often governance. Many vendors blur these terms intentionally. This guide does not.
With those definitions in place, the tools below can be evaluated on the right criteria: not which one claims to do the most, but which one solves the specific problem a given team is facing.
How We Evaluated These Tools
The tools in this list were selected to represent meaningful points on the spectrum from developer-led open-source libraries to no-code enterprise platforms. Here are some of the factors that we took into consideration:
- Matching algorithm depth: Does the tool support exact, fuzzy, probabilistic, and/or ML-based matching? Which methods are configurable versus fixed?
- Use-case fit: Which team profiles and data environments does this tool actually serve well?
- Deployment model: Is the tool on-premise, cloud SaaS, API-based, or available as a Python package?
- Scalability: What is the realistic throughput at typical enterprise data volumes?
- Technical requirement: How much engineering skill does it require to get results?
- Pricing transparency: What is known about cost before a sales conversation?
We also reviewed how each tool is discussed by its own users—drawing on verified buyer reviews on G2, Capterra, TrustRadius, and Gartner Peer Insights to see where real deployments hold up and where they don’t. That perspective surfaces a different layer of information showcasing friction points teams actually run into after the sales call ends.
Core Features to Require in Any Data Matching Tool
Regardless of which platform a team shortlists, these capabilities are the minimum bar:
– Configurable match algorithms: the ability to choose and combine exact, fuzzy, phonetic, and probabilistic methods per field, not a single black-box score.
– Multi-field weighted scoring: match confidence computed across name, address, phone, and identifier fields simultaneously, with user-defined field weights.
– Survivorship rules: configurable logic for which record version wins when duplicates are merged into a golden record.
– Live API access: real-time matching at the point of data entry, not just scheduled batch jobs.
– Deployment flexibility: on-premise or private cloud options for regulated industries where data cannot leave the firewall.
How a Production Data Matching Pipeline Actually Works
Most comparisons jump straight to tool profiles without covering the workflow those tools are meant to support. That gap matters because the stage at which a tool excels or falls short often determines whether it fits your environment, regardless of what the feature list says.
A production data matching pipeline moves through five stages. Understanding each one helps you identify where your current process is breaking down and which capabilities to prioritize when evaluating tools.
Stage 1: Data profiling and assessment
Before any matching logic runs, the source data needs to be understood. Profiling scans every column for completeness, cardinality, format consistency, and null rates, telling you which fields are reliable enough to match on and which need work first.
A 500,000-record CRM export might reveal that the company name field has 14 distinct casing patterns, that 11% of phone numbers are missing area codes, and that address data was entered inconsistently across regional teams. That intelligence shapes every algorithm and threshold decision downstream. Tools that skip profiling and go straight to matching are effectively operating blind. DataMatch Enterprise includes built-in data profiling as part of the match workflow, so teams get this visibility before any matching job runs.
Stage 2: Pre-match standardization
Fuzzy matching algorithms measure similarity between two values. If those values carry formatting differences that have nothing to do with whether the underlying records refer to the same entity, the algorithm ends up scoring formatting noise rather than genuine record similarity.
Pre-match standardization parses and normalizes fields before any comparison begins. Addresses are verified and formatted to a consistent standard, names are stripped of titles and suffixes, phone numbers are brought to a uniform format, and identifiers like EIN or NPI are validated against reference data. This stage is what separates match scores that mean something from match scores that reflect how data was entered.
Stage 3: Blocking and candidate pair generation
Comparing every record against every other record in a million-row dataset is computationally prohibitive. The comparison space grows as O(n²), meaning doubling the dataset quadruples the work. Blocking solves this by generating candidate pairs only for records that share at least one blocking key, such as the same first three characters of a surname combined with the same ZIP prefix.
A well-designed blocking strategy cuts comparison cycles by orders of magnitude without sacrificing recall. The tradeoff is that overly restrictive blocking keys will miss genuine matches where both blocking fields are corrupted or incomplete. Getting this balance right is one of the more consequential configuration decisions in any matching deployment.
Stage 4: Scoring and threshold filtering
Each candidate pair is scored across configured fields. A typical production rule might weight company name at 40%, address at 30%, phone at 20%, and email at 10%, producing a composite match score between 0 and 1. Pairs above an accept threshold are confirmed as matches, those below a reject threshold are dismissed, and pairs in between go to a human review queue.
When a tiered structure is in place, high-volume matching becomes both automated and auditable. DataMatch Enterprise exposes configurable field weights and threshold controls directly in the UI with no scripting required, so data quality managers can tune match sensitivity without engineering support.
Stage 5: Survivorship and entity resolution
Confirmed match pairs feed into a survivorship step that determines what the merged record looks like.
Which version of a customer name survives?
Which address is more recent?
Which source system is considered more authoritative for a given field?
Without defined survivorship rules, merged records silently inherit incorrect or outdated values from whichever source record happened to be processed last.
Entity resolution extends this further by maintaining a persistent identity graph across batch runs. When a new record arrives next month, the system already knows that “IBM Corp” and “IBM Corporation” resolve to the same node and links the new record accordingly without re-running the full pipeline. DataMatch Enterprise handles survivorship logic as part of the match workflow, with configurable rules for which source record wins on each field, and supports golden record creation as the output of the consolidation process.
At a glance, here is how the eight tools compare on the criteria most buyers ask about first. Full context and tradeoffs for each are in the write-ups below.
| Tool | Algorithm Types | Deployment | Technical Req. | Pricing |
| DataMatch Enterprise | Exact, fuzzy, phonetic, rules-based | On-prem & cloud, code-free | Low | Subscription, free trial |
| WinPure Clean & Match | Exact, fuzzy, phonetic | Windows desktop | Low | ~$1,500/yr, limited free |
| Informatica MDM / IDMC | ML, fuzzy, exact, cluster | Cloud, on-prem, hybrid | High | Custom, IPU-based |
| Syniti Knowledge Platform | Fuzzy, phonetic, exact, AI-assisted | Cloud, on-prem | Medium-High | Enterprise contract |
| Melissa Data Quality Suite | Exact, fuzzy, AI-assisted | Cloud API, on-prem | Low-Medium | Usage-based, free trial |
| IBM Master Data Management | ML, rules-based, exact/fuzzy | IBM Cloud, hybrid | High | Custom, Cloud Pak add-on |
| Splink | Probabilistic (Fellegi-Sunter) | Python package (local/Spark/Athena) | High | Free, open-source |
| OpenRefine | Exact, key collision, clustering | Desktop (local) | Medium | Free, open-source |
The 8 Best Data Matching Software Tools in 2026
Data matching software options in 2026 range from high-scale enterprise platforms to user-friendly, no-code tools. Let’s take a look at some of the top options.
1. Data Ladder DataMatch Enterprise
Use case fit: Mid-market to enterprise data teams running multi-source matching and deduplication across CRM, ERP, healthcare, financial, or government datasets.
DataMatch Enterprise (DME) is purpose-built for data matching, deduplication, cleansing, and enrichment. That narrower scope is what makes it effective because every design decision in the product serves the matching workflow, and teams do not wade through features built for other use cases to get to the ones they need.
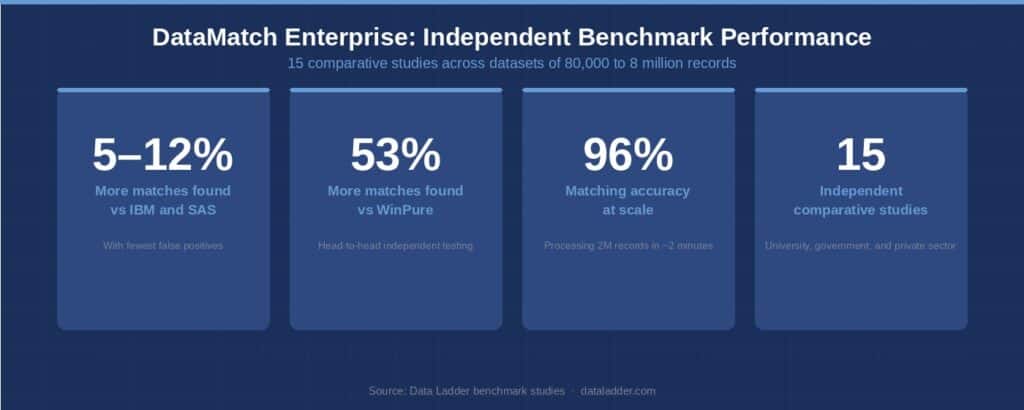
The matching engine supports exact match, fuzzy match, phonetic matching, and configurable rules-based scoring. DME has been independently benchmarked against IBM and SAS across 15 comparative studies, with results showing it finds 5 to 12 percent more matches with fewer false positives. Against WinPure in head-to-head testing, DME found 53 percent more matches. At throughput, it processes 2 million records in approximately 2 minutes at 96 percent accuracy.
Deployment is a meaningful differentiator here. The platform is code-free, meaning data engineers and data quality managers can configure match jobs, set thresholds, and run deduplication workflows without writing custom scripts. In fact, a G2 reviewer matching large volumes of business-partner and address data called it an “easy tool which works and has plenty of functionalities, plus perfect service support,” while another working on a multi-system provider-matching project for a state licensure dataset praised how quickly the software “parses” large batches of names and addresses, noting “the speed is incredible.”
Where implementations of Informatica MDM or IBM MDM typically require months of configuration and often an external implementation partner, DME can be operational within a day.
The free trial does not require a credit card. For teams that have outgrown basic deduplication scripts or hit the ceiling on a lighter tool, DME is the most practical starting point for serious matching work without enterprise MDM overhead.
- Algorithm types: Exact, fuzzy, phonetic, rules-based, configurable scoring
- Deployment: On-premise and cloud; code-free UI
- Technical requirement: Low
- Best for industries: Healthcare, financial services, government, retail, marketing operations
- Pricing: Subscription-based; free trial available at dataladder.com
2. WinPure Clean & Match
Use case fit: Marketing, sales ops, and business analyst teams that need to deduplicate CRM exports, mailing lists, or spreadsheet data without involving IT.
WinPure Clean & Match is a Windows-based desktop tool oriented toward non-technical users who need straightforward deduplication and basic fuzzy matching. Its interface is visual and accessible, and it handles common scenarios like removing duplicate contacts from a Salesforce export or cleaning up a mailing list before a campaign launch.
For what it targets, it works. The tool covers name and address parsing, phonetic matching, and configurable match thresholds. It connects to common sources including Excel, Access, SQL Server, and Salesforce.
Reviewers on G2 and Capterra also back this up. One Capterra user matching large datasets said the tool “does what its supposed to do really well and very quickly,” and a CRM migration customer on G2 credited WinPure’s onboarding support for making “even the most complex matching and cleaning tasks” manageable.
The tradeoff is depth. WinPure’s algorithms are less configurable than enterprise-grade tools, which shows up in match recall on messy, high-variation data. Third-party aggregation of WinPure’s G2 reviews confirms this pattern from the other side: reviewers consistently flag “limited scalability” on very large datasets as a recurring drawback, alongside a learning curve once you move past the basic matching screens into custom configuration.
- Algorithm types: Exact, fuzzy, phonetic
- Deployment: Windows desktop; some cloud functionality
- Technical requirement: Low
- Pricing: Paid plans starting around $1,500/year; limited free version available
3. Informatica MDM / IDMC
Use case fit: Large enterprises managing customer, product, and supplier master data across complex multi-system environments, particularly organizations that have dedicated MDM teams or work with implementation partners.
Informatica occupies the high end of the market. The Intelligent Data Management Cloud (IDMC) includes a full MDM capability with AI-powered match-and-merge, data quality profiling, governance workflows, and integration with hundreds of upstream and downstream systems. If the requirement is to manage master data across multiple domains at enterprise scale with stewardship workflows, compliance controls, and lineage, Informatica is one of the most capable options available.
The matching engine within IDMC MDM supports configurable exact and fuzzy rules, confidence scoring, cluster-based duplicate grouping, and ML-assisted rule suggestions. The platform handles survivorship logic and golden record creation as part of its consolidation workflow, which puts it firmly in entity resolution territory rather than just matching.
G2 reviewers reflect that capability: one reviewer running an MDM cloud deployment for customer identification said the experience came down to strong “product functionality and performance,” and a reviewer who relied on it for marketing-driven customer and lead matching said they “really don’t know how we would have done it without Informatica.”
The practical constraint is implementation complexity and cost. Most large deployments require an implementation partner and a multi-month project before the first production match job runs. Pricing is based on Informatica Processing Units (IPUs), a consumption model that can be difficult to estimate before scoping. This is also one of the most consistent themes across Informatica’s own G2 reviewswhich state “implementation can get complex” and setup “can be quite complex, particularly for those who are new to the platform”.
For teams that need matching accuracy and speed without months of configuration, Informatica is often more complex than the problem requires.
- Algorithm types: ML-powered, fuzzy, exact, configurable scoring, cluster matching
- Deployment: Cloud-native SaaS (IDMC), on-premise, or hybrid
- Technical requirement: High
- Pricing: Custom enterprise; IPU-based consumption model
4. Syniti Knowledge Platform
Use case fit: Organizations undergoing SAP S/4HANA migrations or consolidating ERP data who need data matching and deduplication as part of a broader migration and data quality workflow.
Syniti built its reputation on SAP data migrations, and that context shapes how its matching capability works. The Syniti Knowledge Platform includes a data matching module (previously marketed separately as 360Science’s matchIT, which Syniti acquired) that handles party data matching, operational data matching for materials and parts, and deduplication in migration contexts.
The matching engine supports fuzzy, phonetic, and exact matching with AI-assisted contextual evaluation. For supply chain and MRO use cases specifically, Syniti includes pre-loaded taxonomies and characteristic sets that make it faster to configure matching for materials and parts data, which is a genuinely differentiated capability.
That depth also shows up in long-tenure reviews: one Capterra reviewer who had used the legacy matchIT product for over a decade called it “the most flexible and affective” deduplication tool they had tried, citing extensive parameterization and “brilliant and responsive customer support.”
Where Syniti is less suited is for teams that need standalone data matching outside a migration or SAP context. The platform is priced and scoped as an enterprise migration tool, not a lightweight matching utility. There is also a product transition worth flagging: Syniti has been migrating the matchIT product into its broader Syniti Knowledge Platform, and users of the legacy desktop-based matchIT may find the transition path requires attention.
That friction too shows up in current reviews with one recent Capterra reviewer describing “unintuitive, convoluted ways of achieving even the most basic results” and flagged problems with comma-delimited file handling.
- Algorithm types: Fuzzy, phonetic, exact, AI-assisted contextual matching
- Deployment: Cloud-native SaaS, on-premise
- Technical requirement: Medium to high
- Pricing: Enterprise contract; no public pricing
Ready to improve data matching in your environment?
Try Data Ladder on your own data to see how it supports matching, deduplication, and entity resolution across complex systems.
Start a Free Trial5. Melissa Data Quality Suite
Use case fit: Organizations that need to validate, standardize, and match contact data including names, addresses, email addresses, and phone numbers, particularly where real-time API-based validation at point-of-entry matters.
The matching and identity resolution capabilities within Melissa work well for the specific domain it focuses on: person and contact data. It uses AI alongside reference data to consolidate records and create a unified customer view. Melissa’s Unison integration framework allows real-time validation across CRMs, ERPs, and marketing platforms.
Users on G2 consistently point to accuracy as Melissa’s strongest trait: one reviewer praised the Phone & Email Validator for its “accuracy, efficiency, reliability, and ease of use,” crediting it with reducing miscommunication from bad contact data, and TrustRadius reviewers separately call out the responsiveness of Melissa’s implementation and support team as a recurring strength.
Melissa is not a general-purpose matching engine for arbitrary structured data. Its strengths are tightly coupled to the contact domain. For product matching, operational data matching, or multi-entity resolution beyond person and organization records, a different tool would be needed.
That domain focus comes with a cost on the interface side—TrustRadius’s aggregated review summary notes that “many users have found the user interface to be outdated and confusing, requiring a significant amount of time to get used to,” and one G2 reviewer flagged that integrating the tool with existing systems and the training overhead required can be “challenging.”
- Algorithm types: Exact, fuzzy (name/address/phone/email), reference data matching, AI-assisted
- Deployment: Cloud API and on-premise; available via SaaS
- Technical requirement: Low to medium (API-first)
- Pricing: Usage-based API pricing; free trial available
- Where it is not the right choice: Multi-domain enterprise matching beyond contact data, or scenarios requiring configurable probabilistic scoring across arbitrary data types.
Wondering how Melissa fares against Data Ladder? Check out our Data Ladder vs Melissa comparison.
6. IBM Master Data Management (formerly Match 360)
Use case fit: Large enterprises with existing IBM Cloud Pak for Data deployments that need ML-powered matching and entity resolution integrated within the IBM ecosystem.
IBM’s matching stack has gone through a product evolution worth understanding. IBM Match 360 transitioned into IBM Master Data Management in December 2025, representing the rebranded and expanded continuation of the InfoSphere MDM portfolio. The core matching capability, which uses ML-powered algorithms with confidence scoring and match tuning, has carried forward with modern cloud-native architecture.
The platform handles multi-domain matching for customers, organizations, locations, and other entity types. It includes stewardship tools with audit trails, AI-suggested matching attributes, and REST API access to entity explorer results. The ML matching engine is designed to reduce the manual tuning burden over time by learning from stewardship decisions.
Reviewers who have stayed with the platform long-term back up its depth: one G2 reviewer called it “by far the best customer data management platform,” and a Gartner Peer Insights reviewer in banking highlighted its “robust data governance capabilities and flexibility to handle complex data hierarchies” at scale.
The honest assessment of IBM MDM is that the capability is enterprise-grade, but the value delivery depends heavily on being within the IBM ecosystem. Setup is complex, pricing runs through IBM Cloud Pak for Data licensing, and implementation typically requires experienced IBM consultants.
That complexity surfaces directly in reviews: G2 users repeatedly flag a “confusing interface” and “design of software” as drawbacks, and a Gartner Peer Insights reviewer noted the “user interface is less intuitive compared to more modern MDM solutions,” adding that implementation complexity “may pose challenges for organizations that are new to master data management.”
For teams already on the IBM data fabric, it integrates well. For everyone else, the acquisition and operational cost is high relative to what alternative platforms can deliver faster.
- Algorithm types: ML-powered, configurable rules-based, exact and fuzzy
- Deployment: IBM Cloud (SaaS) and hybrid cloud; Cloud Pak for Data
- Technical requirement: High
- Pricing: Custom; included in or add-on to Cloud Pak for Data
Check out our head-to-head comparison between IBM Master Data Management and Data Ladder.
7. Splink
Use case fit: Data engineers, researchers, and government agencies that need probabilistic record linkage on large datasets and have the Python skills to configure and run it.
Splink was developed by the UK Ministry of Justice’s data linking team and released as open-source software. It implements the Fellegi-Sunter probabilistic record linkage model with a set of enhancements for scalability and accuracy. It supports deduplication within a single dataset, linking between two datasets, and large-scale multi-dataset linkage using backends including DuckDB, Apache Spark, and AWS Athena.
The scale numbers are credible: a million records linked on a laptop in approximately one minute, with support for 100-plus million records using distributed backends. The Australian Bureau of Statistics used Splink to build the 2024 National Linkage Spine for the National Disability Data Asset. The European Medicines Agency uses it to detect duplicate adverse event reports for veterinary medicines. Harvard Medical School researchers used it for probabilistic linkage across 8.1 million records.
Splink requires no training data for model training because it uses unsupervised expectation-maximization to estimate parameters. It also includes an interactive visualization suite that makes it practical to diagnose model quality, which matters given that probabilistic linkage results can be opaque without good tooling.
The constraint is engineering skill. Splink is a Python package. Configuring a blocking strategy, defining comparison functions across fields, and interpreting match weights requires comfort with the underlying statistical model. For teams with that capability, it is likely the highest-performing free option available. For teams without it, the learning curve is steep.
- Algorithm types: Probabilistic (Fellegi-Sunter), configurable fuzzy comparisons, term-frequency adjustments
- Deployment: Python package; runs locally (DuckDB), on Spark, or AWS Athena
- Technical requirement: High (Python, data engineering)
- Pricing: Free and open-source
8. OpenRefine
Use case fit: Data analysts and researchers handling one-time or periodic data cleaning tasks, where the goal is to explore and clean a dataset interactively before loading it into a pipeline.
OpenRefine is a desktop application for working with messy data. It provides faceting, clustering, and transformation tools that allow users to identify and collapse near-duplicate values within a single column or field, and it supports reconciliation against external data sources including Wikidata.
The clustering algorithms, which include key collision methods like fingerprinting and phonetic hashing alongside nearest-neighbor approaches, are effective for the specific problem of cleaning inconsistent string data. If a dataset has 40 variations of the same city name, OpenRefine will surface them and let a human decide how to handle them.
G2 reviewers describe exactly this workflow in practice: one reviewer said OpenRefine “made it so much simpler” to transform and process incoming data “at a fraction of the time” compared to their old approach, and another credited it with surfacing “outliers and errors” in a dataset that “you would never spot by just glancing.”
OpenRefine does not handle record-level deduplication across multiple fields the way a purpose-built matching tool does. It has no batch scheduling, no API, no survivorship logic, and no production pipeline integration. It is most useful as a preprocessing and data exploration tool, particularly for analysts working in research or journalism contexts where the dataset is bounded and the task is not repeatable at scale.
That scaling ceiling is exactly what G2 reviewers flag as the tool’s main drawback: one wrote plainly that it “does not scale to analyze large data sets” because it’s “limited to the amount of RAM you have on your computer since it runs locally and not on the cloud.”
- Algorithm types: Exact, key collision (fingerprinting, n-gram), nearest-neighbor clustering
- Deployment: Desktop application (local)
- Technical requirement: Medium (desktop application, some learning curve)
- Pricing: Free and open-source
How to Choose the Right Data Matching Software
The decision usually comes down to three variables: the nature of the data problem, the team’s technical profile, and the role matching plays in the broader data architecture.
Start with the data problem. Single-source deduplication on contact records is a different problem than multi-source entity resolution across five systems with different schemas. The tools that handle one well often do not handle the other as effectively. Be specific about what you are trying to produce whether it’s a deduplicated list, a golden record, a match confidence score for downstream use, or a linked dataset for analytical purposes.
Then assess team profile. A data engineer comfortable in Python and familiar with probabilistic models has different options than a marketing ops analyst who needs a result by end of week. Open-source tools like Splink offer high performance at zero licensing cost, but the configuration overhead is real. Code-free platforms compress that time-to-value significantly, at the cost of some configurability.
Consider where matching sits in your architecture. If matching is a preprocessing step for an analytics pipeline, you may not need survivorship or governance tooling. If the output feeds a system of record or drives operational decisions, the standards are higher and a tool with audit trails, confidence scoring, and stewardship workflows earns its cost.
Understand how pricing works. Enterprise MDM platforms from IBM and Informatica are priced for enterprise budgets and typically require multi-month implementations before production use. Mid-market options like DataMatch Enterprise or Melissa offer more accessible entry points with free trials. Open-source tools cost nothing in licensing but require engineering investment. That investment is real and should be estimated honestly when comparing total cost.
FAQ About The Best Data Matching Software
What is the difference between data matching and entity resolution?
Data matching is the process of comparing records to find which ones refer to the same real-world entity. Entity resolution is the broader workflow that includes data matching plus standardization, survivorship logic (deciding which version of a record to keep or how to merge records into a golden record), and ongoing governance. Matching is a component of entity resolution, not a synonym for it.
How do data matching processes help organizations?
Data matching processes can significantly reduce the volume of data to be maintained, leading to faster and more accurate data analysis across the enterprise. The performance of data matching tools is critical in enterprise environments, where they must handle large datasets with inconsistent formatting across multiple systems without significant slowdowns or errors.
Can open-source tools like Splink replace commercial data matching software?
For technically proficient teams working on probabilistic linkage at large scale, Splink is competitive with commercial alternatives on accuracy and throughput. The gap is in ease of deployment, UI-driven configuration, and built-in stewardship workflows. Commercial tools compress the time from data ingestion to actionable match output, which matters significantly when the person running the matching job is not a data engineer. Ongoing maintenance and version updates are also considerations with open-source tooling.
What matching algorithms should enterprise data matching software support?
At minimum: exact match for structured identifiers, fuzzy match for names and addresses (typically using algorithms like Jaro-Winkler, Levenshtein, or phonetic encoding), and configurable scoring that combines multiple field-level comparisons into a record-level match score. More capable platforms also support probabilistic matching using frequency-based weighting, ML-assisted rule suggestions, and blocking strategies that reduce the comparison space without sacrificing recall.
How do you evaluate false positives and false negatives in data matching?
False positives are records incorrectly identified as matches (over-matching). False negatives are matches the system misses (under-matching). Most tools let you tune a match threshold score to balance between these. Evaluating performance requires a labeled test set where the ground truth is known. Interactive tools like Splink’s comparison viewer or a match review workflow in enterprise platforms help stewards identify where the threshold needs adjustment. Independent benchmarks, such as those published by Data Ladder comparing DME against IBM and SAS, can also inform expectations before configuration begins.
Is data matching the same as fuzzy matching?
No. Fuzzy matching is one technique used within data matching. It handles comparisons where string values are similar but not identical. Data matching encompasses the full process of configuring which fields to compare, defining scoring logic across multiple fields, handling blocking to reduce the comparison space, and reviewing or acting on match results. A tool that only does fuzzy string comparison on a single field is not a data matching platform.
Conclusion
The best data matching software is the one that fits the actual problem, not the one with the longest feature list. For teams that need enterprise-grade accuracy across multi-source environments without months of configuration overhead, DataMatch Enterprise is a strong starting point and offers a no-credit-card free trial. For large-scale probabilistic work with engineering resources in-house, Splink is worth serious evaluation. For teams at the enterprise MDM level already embedded in IBM or Informatica ecosystems, those platforms deliver the governance layer that justifies their complexity.
Still not sure which tool fits your stack?
DataMatch Enterprise finds 5–12% more matches than IBM and SAS across 15 independent benchmarks and it’s operational in a day, not months.
Run a free trial of DataMatch Enterprise on your own data — no credit card, no sales call required. See what your current process is missing before committing to anything.

