































Last Updated on September 24, 2024
With 89% of employees reporting sifting through up to six data sources daily to find relevant information, data sprawl emerges as a major culprit undermining workplace efficiency. The result? Excessive time waste, disrupted workflows, and growing frustration among employees. Data silos are costing businesses millions in missed opportunities and flawed decision-making. Yet, many organizations still treat data integration as an afterthought. Without a solid data integration strategy, businesses face mounting inefficiencies, inconsistent insights, and costly errors.
They are not just missing out – they are falling behind.
By unifying data into a single, accessible system, organizations can eliminate silos, streamline access to information, and significantly improve productivity, employee satisfaction, and decision-making.
What is Data Integration?

Data integration is the process of combining, consolidating, and merging data from multiple disparate sources to attain a single, uniform view. This practice allows organizations to break down silos, enable efficient data management and analysis, and improve accessibility.
Capturing and storing is the first step in a data management lifecycle. But disparate data sets – residing at various databases, spreadsheets, local servers, and third-party applications – are of no use, until they are brought together. Data integration enables your business to practically and holistically apply the captured information and answer critical business questions.
Consider customer data integration as an example. In many organizations, customer information is scattered across various platforms. These may include website tracking tools, CRMs, marketing automation and accounting software, financial databases, and so on. To make sense of the customer information a company has and extract useful insights, its employees need easy access to all of it, where they do not have to cannot constantly switch between applications. They require a single, uniform access to customer data records – where data is kept clean and free from ambiguities. Data integration does exactly that! It consolidates all the information from different applications and systems into a single, coherent, accessible view. This ensures that insights gained from the data are accurate, timely, and actionable.
This is just one example. There are countless other benefits of data integration that enable efficient data management, business intelligence, and other data operations.
5 Types of Data Integration

Organizations can achieve data integration in various ways, depending on their specific needs and goals. These methods, also referred to as types or techniques of data integration, vary in their application, complexity, and end goal. Here are five key types or methods of data integration:
1. Batch Data Integration
In this type of data integration, data goes through the ETL (Extract, Transform, Load) process in batches at scheduled times (weekly or monthly). It is extracted from disparate sources, transformed into a consistent and standardized view, and then loaded to a new data store, such as a data warehouse or multiple data marts. Batch integration is mostly useful for data analysis and business intelligence in scenarios where immediate data processing isn’t required, such as maintaining company file indexes or processing monthly utility bills.
2. Real-Time Data Integration
Real-time data integration refers to the continuous processing and transfer of data as it is generated. In this type of data integration, incoming or streaming data is integrated into existing records in near real-time through configured data pipelines. It allows organizations to access data and utilize it almost instantly, rather than waiting for batch processing intervals, enabling them to respond swiftly to changes.
Real-time data integration is crucial for operational dashboards, fraud detection, inventory management, and other types of time-sensitive decision-making.
Businesses can employ data pipelines to automate the movement and transformation of data, and routing it to the targeted destination. During this, processes for integrating incoming data (as a new record or updating/appending to existing information) are built into the data pipeline.

3. Data Consolidation
Data consolidation involves combining data from different sources into one environment to create a single, unified view. During this process, first, a copy of all source datasets is created in a staging environment or application. Data records are then consolidated to represent a single view, and then finally moved to a destination source. Although this type of data integration is similar to ETL, it has a few key differences such as:
- Data consolidation focuses more on concepts like data cleansing and standardization and entity resolution, while ETL focuses on data transformation.
- While ETL is a better option for big data, data consolidation is a more suitable type for linking records and uniquely identifying main data assets, such as customer, product, and location.
- Data warehouses mostly help in data analysis and BI, while data consolidation is also helpful for improving business operations, such as using a customer’s consolidated record to contact them or creating invoices, etc.
4. Data Virtualization
As the name suggests, this type of data integration doesn’t create a copy of data or move it to a new database with an enhanced data model. Instead, it introduces a virtual layer that connects with all data sources and offers uniform access as a front-end application.
Since it does not have a data model of its own, the purpose of the virtual layer is to accept incoming requests, create results by querying the required information from connected databases, and present a unified view. Data virtualization reduces the cost of storage space and integration complexity, as data just seems integrated but resides separately at source systems.
5. Data Federation
Data federation is similar to data virtualization and is often considered its subtype. It also doesn’t involve copying or moving data to a new database. Instead, it creates a new data model, which represents an integrated view of source systems.
Data federation provides a querying front-end interface. When data is requested, it pulls data from the connected sources, and transforms it into the enhanced data model before presenting the results. This method of data integration is particularly useful when the underlying data models of source systems are too different and must be mapped to a newer model in order to use the information more efficiently.
Data Integration Process

Regardless of the type of data integration method employed, the overall flow of the process is similar for all, as the goal is to seamlessly combine and consolidate data into a unified system that improves data accessibility and usability. Let’s discuss the general enterprise data integration framework that you can use while implementing any data integration technique.
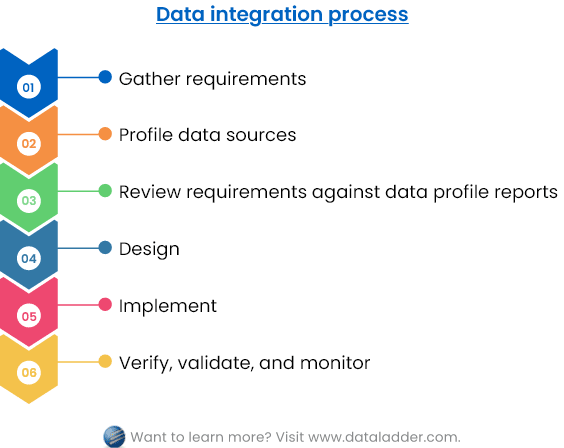
1. Requirement Gathering
The first step in any data integration process is to gather and assess business and technical requirements. This helps plan, design, and implement a framework that produces the expected results. Here are a few key things you must consider while gathering requirements:
- Do you need to integrate data in real-time or batch integrate at scheduled times?
- Do you need to create a copy of data and then integrate it? Or do you want to implement a virtual layer that integrates data on the fly without replicating databases?
- Should the integrated data follow a new, enhanced data model?
- Which sources need to be integrated?
- What will be the destination of integrated data?
- What functional departments in the organization need access to integrated information?
2. Data Profiling
Another initial step of the data integration process is to generate data profiling or assessment reports of data that needs to be integrated. It is essential for understanding the current state of data, uncover hidden details about its structure and content, and identify gaps in it. By generating data profiling reports, organizations can identify issues, such as blank values, field data types, recurring patterns, and other descriptive statistics that highlight potential data cleansing and transformation opportunities. This step ensures that the integration process begins with a clear understanding of the data’s current state.
3. Reviewing Profiles Against Requirements
With integration requirements and assessment reports in hand, now it’s time to identify the gap between the two. There will be many functionalities requested in the requirements phase that are not valid or don’t add up with the profiled reports of existing data. But the comparison between the two will help you plan an integration design that fulfills as many requirements as possible.
Reviewing profiles helps identify any discrepancies or gaps between the ideal integration setup and the actual state of the data. It also helps formulate a realistic and effective integration plan.
4. Design
This is the planning phase of the process. At this stage, you need to design some key concepts about data integration, such as:
- The architectural design that shows how data will move between system
- The trigger criteria that decide when the integration will take place or what will trigger it
- The new, enhanced data model and the columns mappings that define the consolidation process
- The data cleansing, standardization, matching, and quality assurance rules that need to be configured for error-free integration
- The technology that will be used to implement, verify, monitor, and iterate the integration process
5. Implementation
With the integration process designed, it’s time for the execution. The execution can happen incrementally. This means, you integrate low volumes of data from less conflicting sources, and iteratively increase volumes and add more sources. This can be useful to catch any initial errors that may arise. Once the integration for existing data is completed, the process can be scaled up to integrate new incoming streams of data and handle larger datasets, and more diverse data sources.
6. Verification, Validation, and Monitoring
After implementation, the integration process must be tested and validated for accuracy and efficiency. Profiling destination source can be a good way to catch errors and validate the integration. A number of areas must be tested before the integration setup can be entrusted for future activities, such as:
- There is no/minimal data loss,
- The quality of data did not deteriorate after the integration,
- The integration process performs consistently as expected,
- The meaning of data did not change during the integration,
- The measures mentioned above still hold true after some time has passed.
Post-integration, the system must also be continuously monitored. Monitoring helps catch any discrepancies as they occur and ensures that the integration remains reliable over time and adapts to any changes in data sources or requirements.
Data Integration and Data Quality: Too Integrated to Be Differentiated

Before we move on, let’s discuss an important concept related to data integration that often confuses people: the relationship between data integration and data quality.
From a holistic point of view, both data integration and data quality have the same goal: to make data usage easier and efficient. In efforts to achieve this goal, one cannot mention data integration without data quality, and vice versa. It can get confusing if you try to understand where does one ends and the other begins. The truth is that both concepts are too integrated to be differentiated and must be handled seamlessly. However, understanding their connection is also essential for effective data management.
Data integration refers to the process of combining data from various sources, while data quality focuses on ensuring that the data is accurate, consistent, and usable. Another distinction between the two is that data quality is not an initiative – but a habit or exercise that must be consistently monitored. Although in the case of data warehouses, data integration can happen at specific times of the week or month, you cannot forget about data quality even during that wait.
Poor data quality undermines integration efforts and make data unusable despite being unified across systems. Data integration efforts with zero data quality consideration are bound to be wasted. A strong emphasis on data quality is essential for successful integration. Data quality management is a catalyst to the data integration process as it improves and speeds up data consolidation.
Imagine consolidating customer data from multiple sources only to find that records are inconsistent, outdated, or contain errors. Without proper data quality measures, integration results in data replication (duplicate records), incomplete profiles, and ultimately unreliable insights, all leading to misguided business decisions.
Why Data Quality Assurance Must Be Part of Data Integration?
Here are some reasons why data quality should be a constant, integrated part of any data integration initiative:
- Continuous Validation: Data quality should be monitored even after integration. It’s not a one-time event but an ongoing process to maintain consistency and integrity across datasets.
- Minimizing Data Loss: Ensuring high-quality data reduces the risk of data loss or corruption during integration, especially in complex ETL (Extract, Transform, Load) processes.
- Maximizing Usability: High-quality data allows businesses to trust the results of integration efforts, making it easier to leverage for analysis, forecasting, and decision-making.
In essence, data quality acts as a catalyst for improving the outcomes of data integration processes. Without it, integration efforts will result in inefficiencies and errors and waste both time and resources.
Data Integration Tools and Solutions

With the increasing volumes and complexity of data that organizations store and integrate, manual efforts are out of the equation for most integration initiatives. Utilizing technology to integrate and consolidate data residing at separate sources can prove to be more effective, efficient, and productive. Let’s discuss what are some of the common features you can look for in a data integration platform:
1. Wide Data Source Connectivity
A powerful data integration tool should be able to connect to a wide range of data sources, including structured databases (SQL, Oracle), semi-structured data (JSON, XML), unstructured data (emails, documents), cloud data warehouses, and third-party applications (CRMs, marketing automation tools).
The ability to pull data from a wide variety of formats and environments is critical to achieving seamless integration.
2. Comprehensive Data Profiling
Effective data integration starts with data profiling. The tool should generate detailed profiling reports to highlight the current state of your data – revealing completeness, patterns, inconsistencies, data types, formats, null values, outliers, and more. Profiling helps identify opportunities for cleansing and standardization before integration. It ensures that only clean, high-quality data is consolidated.
3. Data Cleansing and Data Standardization Capabilities
Clean data is the foundation of reliable business insights. A good integration tool should be equipped with features to eliminate data ambiguities, such as duplicate records, misspelling, null or garbage values, and noise. Additionally, it should transform the data into a standard format by correcting inconsistencies, replacing abbreviations, and resolving mismatches in data types.
4. Data Mapping
Data integration tools should allow for comprehensive data mapping – matching fields from disparate data sources to highlight how data will flow during integration. Clear mapping ensures that data from different systems is aligned correctly and helps maintain consistency and accuracy.
5. Data Matching
For integration involving customer or entity data, advanced matching algorithms are important. These algorithms should identify records belonging to the same entity across multiple systems and enable deduplication.
6. Record Merging
The tool must also have the capability to overwrite values wherever needed and merge records across sources to create golden records (a single source of truth for each entity).
7. Automation and Scheduling
Automation is integral to efficient data integration. A good tool should allow scheduled integrations or real-time integrations through API calls or other similar mechanisms. This eliminates the need for manual interventions and ensures that your data is always up-to-date.
8. Destination Flexibility
A versatile integration tool must support the loading of combined data into multiple destinations, whether it’s a data warehouse, data lake, or a BI tool, based on your organization’s data architecture.
Unifying Data Integration, Cleansing, and Matching
Integrating large amounts of data can be an overwhelming process, especially if you are opting for an ETL or data virtualization setup. A basic data integration environment that brings data together while minimizing intolerable data quality defects can be a good place to start for most companies. Prioritizing the single, most important data integration aspect of data consolidation can help you to start low and incrementally improve as needed.
You can start by employing a unified, modern data integration platform that offers a variety of common connectors as well as in-built features for data profiling, cleansing, standardization, matching, and merging. In addition to this, a scheduling feature that batch integrates data at configured times can kickstart your initiative within a few days.
DataMatch Enterprise is one such data consolidation tool that can help integrate your data residing at separate sources. Download a trial today or book a demo with our experts to see how we can help execute your data integration initiative.

